


Renforcer la confiance dans la découverte d'IA grâce à un échantillonnage rationalisé
- eDiscovery
- 3 mins
Dans le domaine de l'eDiscovery, il est primordial de garantir l'exactitude et la défendabilité de l'examen des documents, en particulier lorsque les productions sont partagées avec les parties adverses ou les autorités de réglementation. Epiq AI Discovery Assistant™ apporte une rigueur statistique à ce processus en permettant la validation à l'aide de mesures d'évaluation standard : rappel, précision et évasion.
- Le rappel mesure le nombre de documents pertinents qui ont été correctement identifiés parmi tous les documents pertinents possibles.
- La précision évalue le nombre de documents identifiés comme pertinents qui étaient réellement pertinents.
- L'élusion estime le nombre de documents pertinents qui peuvent exister dans l'ensemble présumé non pertinent.
Ces mesures, basées sur un échantillonnage aléatoire, permettent d'évaluer de manière transparente et statistiquement fiable l'efficacité de l'examen des documents assisté par l'IA.
Quand valider
La validation est particulièrement importante lors de la production de documents à des parties externes. Qu'il s'agisse d'un organisme de réglementation ou d'un avocat adverse, il est essentiel de démontrer la fiabilité de votre processus d'examen. Pour les enquêtes internes ou les productions entrantes, la validation est facultative, mais reste néanmoins utile. La capacité à estimer le rappel, la précision, l'élusion et la richesse avec des intervalles de confiance garantit la défendabilité et la transparence.
Ce qu'il faut mesurer
Epiq AI Discovery Assistant™ ne se contente pas d'identifier les classifications « Répondant » ou « Ne répondant pas ». Il prend également en charge le marquage des problèmes et la détection des privilèges. Le système comprend des mesures intégrées de rappel et de précision pour chaque balise de problème, en tirant parti de la validation croisée k-fold et des codes de révision.
Cependant, cela ne correspond pas à un ensemble de contrôle et ne doit être utilisé que pour orienter les considérations relatives au flux de travail.
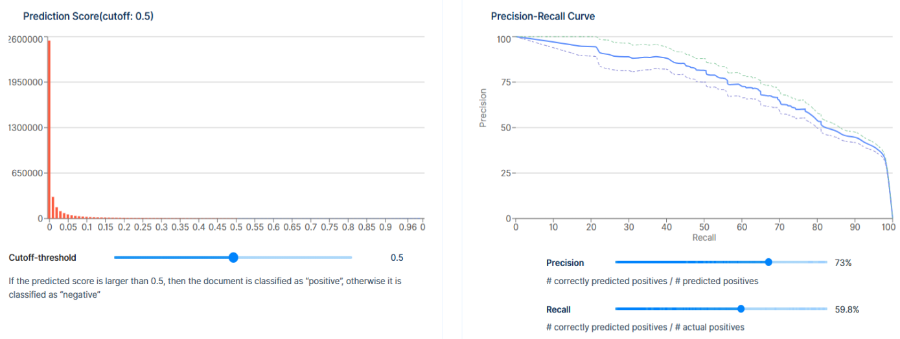
Il est généralement recommandé de valider les catégories « Réactif » et « Non réactif » dans leur ensemble. Les conseils intégrés pour chaque balise peuvent aider à déterminer les scores limites appropriés, mais pour déterminer l'efficacité de la production globale, Epiq recommande de valider les déterminations « Réactif » et « Non réactif » dans leur ensemble.
Ensemble de contrôle : la base de la validation
Un ensemble de contrôle de 500 documents offre souvent une couverture raisonnable. Pour les ensembles de données moins riches ou pour des niveaux de confiance plus élevés, il est possible de sélectionner des ensembles de contrôle plus importants.

L'ensemble de contrôle est sélectionné de manière aléatoire dans la collection, et le codage n'est pas utilisé pour entraîner le modèle. Les documents de l'ensemble de contrôle sont mis de côté lors de l'entraînement et ne sont utilisés que pour la validation.
Échantillonnage de prévalence : premières conclusions
Au début d'un examen, un petit échantillon aléatoire, appelé échantillon de prévalence, est utilisé pour estimer la proportion de documents pertinents dans l'ensemble de données. Cela peut être utile pour déterminer les types de documents et les problèmes susceptibles de se poser lors de la collecte, ainsi que pour planifier les activités en aval. Par exemple, si un examen de deuxième niveau est prévu pour les documents identifiés comme pertinents, un échantillon de prévalence fournit une indication précoce du nombre de documents pertinents qui seront trouvés. Il s'agit d'une étape stratégique qui permet de déterminer l'allocation des ressources et les délais prévus.
Échantillon d'élusion : assurance finale
À la fin du processus d'examen, une étape cruciale consiste à prélever un échantillon aléatoire de documents identifiés comme non pertinents et non produits. Un échantillon d'élusion est un échantillon aléatoire qui identifie le pourcentage de documents pertinents qui ont été négligés ; il s'agit d'un outil puissant dans le cadre d'enquêtes internes et de productions entrantes, lorsque l'équipe souhaite s'assurer qu'aucun élément important n'a été omis. Les échantillons d'élusion permettent également d'estimer le taux de rappel lorsque tous les documents pertinents prévus ont été examinés.
Facilité d'utilisation de l'interface Epiq AI Discovery Assistant™
La configuration et l'exécution d'ensembles d'échantillons avec Epiq AI Discovery Assistant™sont conçues pour être simples. Les utilisateurs lancent les échantillons de contrôle, de prévalence et d'élusion directement via des workflows guidés. Chaque étape comprend des info-bulles et des recommandations intégrées, permettant aux professionnels du droit de configurer les paramètres d'échantillonnage sans avoir besoin d'expertise statistique. Ce processus rationalisé aide les équipes juridiques à valider les ensembles de documents plus rapidement et avec plus de confiance.
Conclusion
Ces indicateurs établis et bien compris pour valider les résultats de la découverte sont également recommandés et intégrés dans le processus Epiq AI Discovery Assistant™. L'identification des intervalles de confiance de précision, de rappel et d'élusion pour la pertinence donne à toutes les parties l'assurance de l'efficacité de la méthode et du résultat.
Bien qu'Epiq AI Discovery Assistant™ offre des fonctionnalités avancées, l'accent reste mis sur l'autonomisation des professionnels du droit, et non sur leur remplacement. En combinant l'expertise humaine et les connaissances de l'IA, les services juridiques et les cabinets d'avocats peuvent rationaliser leurs processus d'examen des documents et répondre aux normes les plus élevées en matière d'exactitude et de responsabilité.

Jon Lavinder, directeur principal de la gestion des produits, Epiq
Responsable des outils d'IA, de la révision assistée par la technologie (TAR), des données collaboratives et de chat, ainsi que des technologies d'évaluation précoce des dossiers (ECA), Jon travaille en étroite collaboration avec des cabinets d'avocats et des professionnels du droit d'entreprise afin de développer les outils et les services de la prochaine génération en matière de recherche juridique et de gouvernance de l'information. M. Lavinder intervient régulièrement lors de conférences sur l'eDiscovery pour parler de l'utilisation de l'IA et de l'avenir du secteur.
Cet article est destiné à fournir des informations générales et non des conseils ou des avis juridiques.