

.png)
以分类驱动的保护机制守护 AI 工作流安全
- eDiscovery
- 1 min
关键要点: 要实现安全且可靠的 AI,组织必须从严谨的数据分类和控制机制入手,同时保护 AI 提示内容和 AI 生成结果。通过使用敏感性标签来驱动数据丢失防护及其他控制措施,组织可以确保 AI 应用仅使用被允许的数据,并使生成的结果自动继承相应的保护级别。
随着数据规模迅速增长、AI 深度融入日常工作流,组织需要对数据拥有更清晰的控制能力,以避免不断出现的新风险,包括无意的数据暴露。
Copilot 就绪框架的第五步聚焦于数据安全控制,将分类从静态标签转变为主动防护机制。在第四步完成数据分类并建立稳固基础后,组织已具备将敏感性标签转化为可执行保护措施的条件。通过延续以标签驱动的逻辑,第五步的重点从识别敏感数据,转向主动管控数据的流动方式。
在这一阶段,分类成为驱动数据丢失防护的核心引擎,确保在第四步中设定的规则,能够在传统工作流和 AI 交互中得到一致应用。
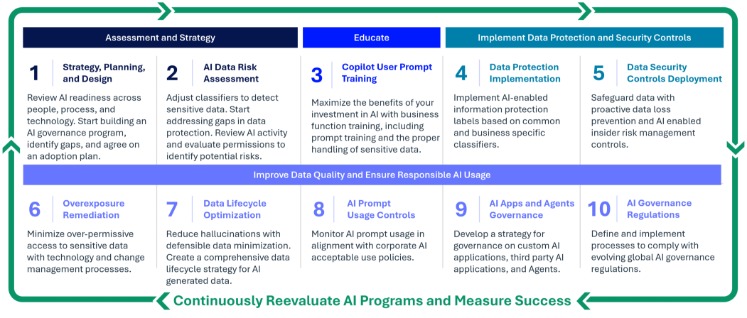
以分类驱动数据丢失防护
在第四步中完成敏感性标签和分类器部署后,组织已具备一层智能能力,能够在整个环境中持续识别敏感内容。数据丢失防护确保保护措施随数据流转,无论数据移动到何处,包括在 AI 交互过程中。
传统的数据丢失防护主要用于保护通过电子邮件、云存储和协作应用传输的数据。分类机制通过与标签体系对齐,进一步强化防护执行,将标签转化为触发警示、要求说明或直接阻止的规则。由于 AI 可以与用户或代理被授权访问的任何数据进行交互,数据保护变得更加关键。面向 AI 的数据丢失防护沿用同样的逻辑,同时保护用户提交的提示内容以及 AI 生成的响应结果。
例如,传统的数据丢失防护可以阻止包含信用卡号的邮件,或要求用户提供发送理由。如果有人尝试将包含个人身份信息、受保护的健康信息或机密业务内容的电子表格上传到个人应用,数据丢失防护可以直接阻止上传,并显示策略提示,引导更安全的操作行为。
在 AI 工作流中,被标记为机密或受限的提示内容可以触发警告、理由说明请求或阻止操作。如果 AI 生成的响应暴露了受保护的数据,数据丢失防护可以阻止复制、下载或共享,将与传统工作流相同的保护机制应用到 AI 场景中。在数据实现一致分类之后,数据丢失防护就成为在传统应用和 AI 应用中强制执行这些分类规则的核心控制手段。
数据丢失防护部署最佳实践
在完成数据分类后,部署数据丢失防护需要兼顾安全性与工作效率,采取审慎且有节奏的方法。这些最佳实践有助于团队以结构化、低风险的方式推进控制措施,逐步提升用户认知,使防护执行与真实业务需求保持一致,并确保保护机制在传统工作流和 AI 交互中得到一致应用。
从可视性开始(审计模式)
在审计模式下,可以先启用监控,了解人员的操作行为、信息如何流动以及流向何处,并识别潜在风险模式。这在任何强制执行之前提供必要的可见性,确保后续策略不会干扰正常工作效率。
渐进式执行
渐进式执行通过分阶段引入控制措施,让团队在真正阻止操作之前先学习、调整并建立用户认知。流程通常从提示和提醒开始,随后对高风险行为要求说明,只有在影响被充分理解和验证后,才启用阻止机制。这种方式既降低风险,又支持平稳落地。
将控制措施与法规和业务需求对齐
不同行业需要不同的控制方式。在金融服务领域,企业可能需要识别并保护交易文件、财务信息或客户数据。在医疗行业,团队可能需要检测发送至未获批准 AI 工具中的受保护健康信息,并仅在数据经过脱敏且访问受限的情况下允许使用 Copilot。将这些控制措施与监管要求对齐,有助于实现合规且可控的 AI 使用。
尽早让相关方参与
尽早将法务、合规、安全和业务负责人纳入讨论,有助于确保策略贴合真实工作流程。他们的参与可以帮助制定符合实际工作方式的规则,减少阻力,并避免用户在执行方式发生变化时措手不及。
将策略视为动态控制机制
有效的 AI 治理并非一次性完成,而是需要随着新风险和工作模式不断调整。团队应定期审查违规趋势,收集用户反馈,并关注可能引入新风险的 AI 使用行为。这些洞察将指导控制措施的持续优化,确保策略始终保持一致性和适用性。
使用终端数据丢失防护保护设备
并非所有数据都始于云端或始终停留在云端。终端数据丢失防护将以分类驱动的保护机制延伸至用户设备,为团队提供可见性和控制能力。这包括将 AI 生成的响应复制到 USB 设备、将敏感数据集上传至外部 AI 工具,或对受保护内容进行打印和屏幕捕捉。无论数据如何被使用或流转,敏感信息都能在每一次交互中持续受控,即使员工在云环境之外使用 AI 工具亦是如此。分类与数据丢失防护相结合,使组织能够安全利用 AI,同时有效阻止高风险的 AI 使用行为。
借助内部风险管理扩展保护能力
数据丢失防护主要用于保护正在流动中的敏感数据,而内部风险管理则帮助组织识别并应对那些未必触发传统策略违规、但已显现风险升高的行为。内部风险管理通过分析异常的数据访问模式、大规模下载、尝试外泄数据或高风险用户活动等信号,及早发现潜在威胁,尤其适用于 AI 加快数据交互速度和规模的场景。
通过将以标签驱动的数据丢失防护与内部风险管理洞察相结合,组织可以更全面地了解敏感信息如何流动,以及潜在的内部风险可能在何处出现。这种统一的方法强化了治理能力,支持合规要求,并确保控制措施能够跟上快速变化的 AI 工作环境。
数据丢失防护、终端控制和内部风险管理协同构建起分层防御体系,全面支撑 Copilot 就绪框架的这一关键阶段,确保无论人员还是 AI 系统如何与数据交互,敏感信息始终受到保护。
安全 AI 工作流的核心结论
负责任的 AI 采用归根结底在于把基础工作做好。持续一致地对数据进行分类,并让这些标签在 MIP、数据丢失防护以及更广泛的治理工具中驱动执行,从而打造一个在设计之初就具备安全性的 AI 环境,而不是依赖人工控制或事后审查。
在遵守监管、合同和道德标准的同时,持续推进有价值的 AI 创新。通过完善的控制机制保护最敏感的信息,增强将 AI 作为变革性工具加以运用的能力。
了解更多关于负责任 AI 与 Copilot 就绪的信息

Manikandadevan Manokaran, 高级数据安全顾问
作为 Epiq 的高级数据安全顾问,Manikandadevan(Mani)专注于帮助组织利用 Purview AI 提升安全性、合规性和数据保护能力。Mani 以客户为中心,在 Microsoft 技术领域拥有超过十六年的经验,专长涵盖云迁移、安全与合规。他热衷于通过智能 AI 解决方案,协助组织实现数据环境的现代化升级。

Paul Renehan, 咨询副总裁
Paul Renehan 是一位拥有二十多年经验的资深管理者,专注领域涵盖数据治理、信息保护和电子发现,并日益聚焦于帮助组织应对人工智能快速发展带来的新要求。作为咨询副总裁,他领导一支专家团队,推动企业数据治理与保护战略的现代化,确保信息生态系统安全、合规、具备 AI 就绪能力,并能够持续创造业务价值。
本文的内容仅旨在传达一般信息,不提供法律建议或意见。