

Angle

Why Confidence Scoring With LLMs Is Dangerous
When it comes to confidence assessments from LLMs, scoring predictions is essential. The most important thing is not the scores themselves, but the resulting ranking these scores produce.
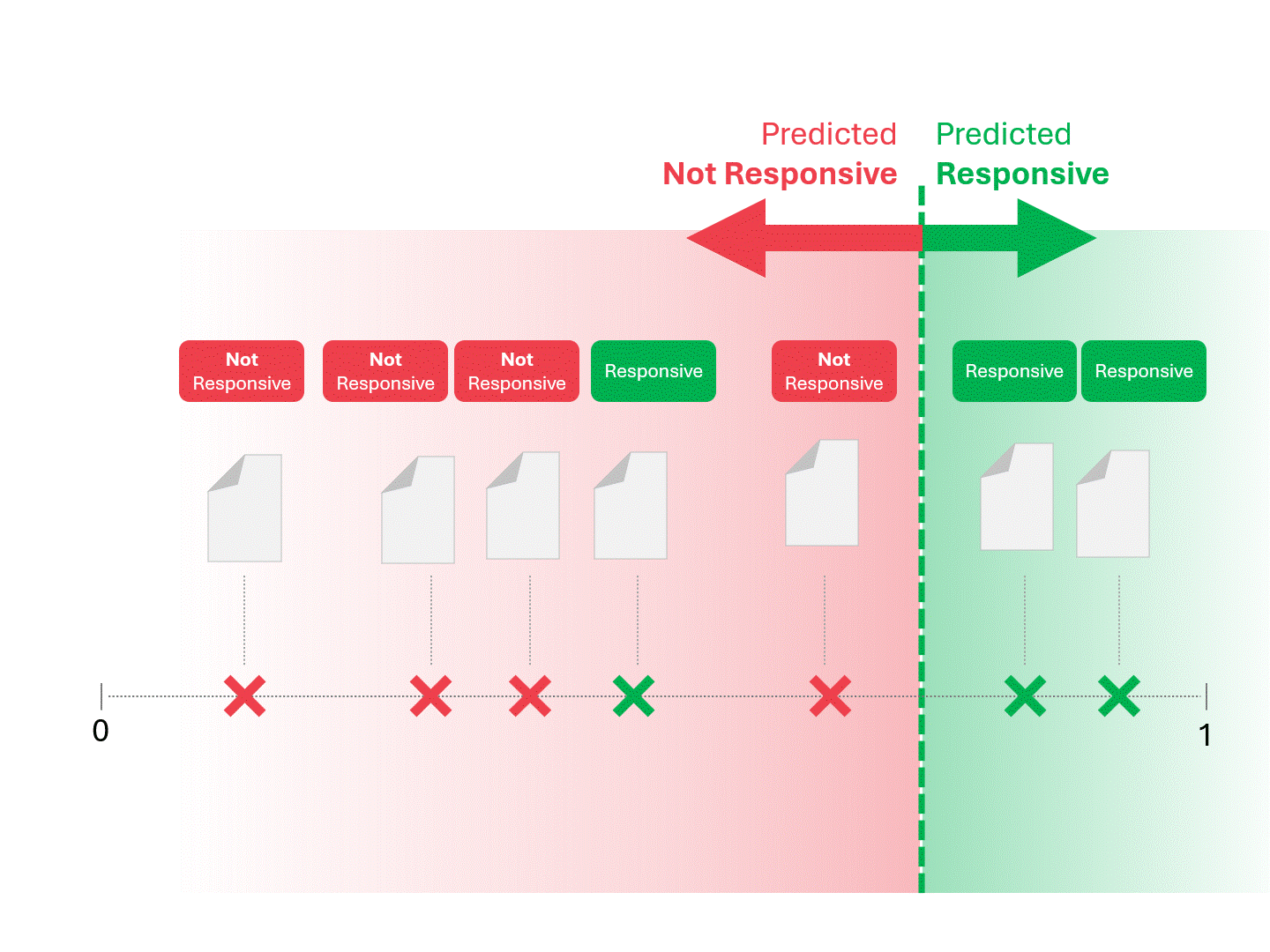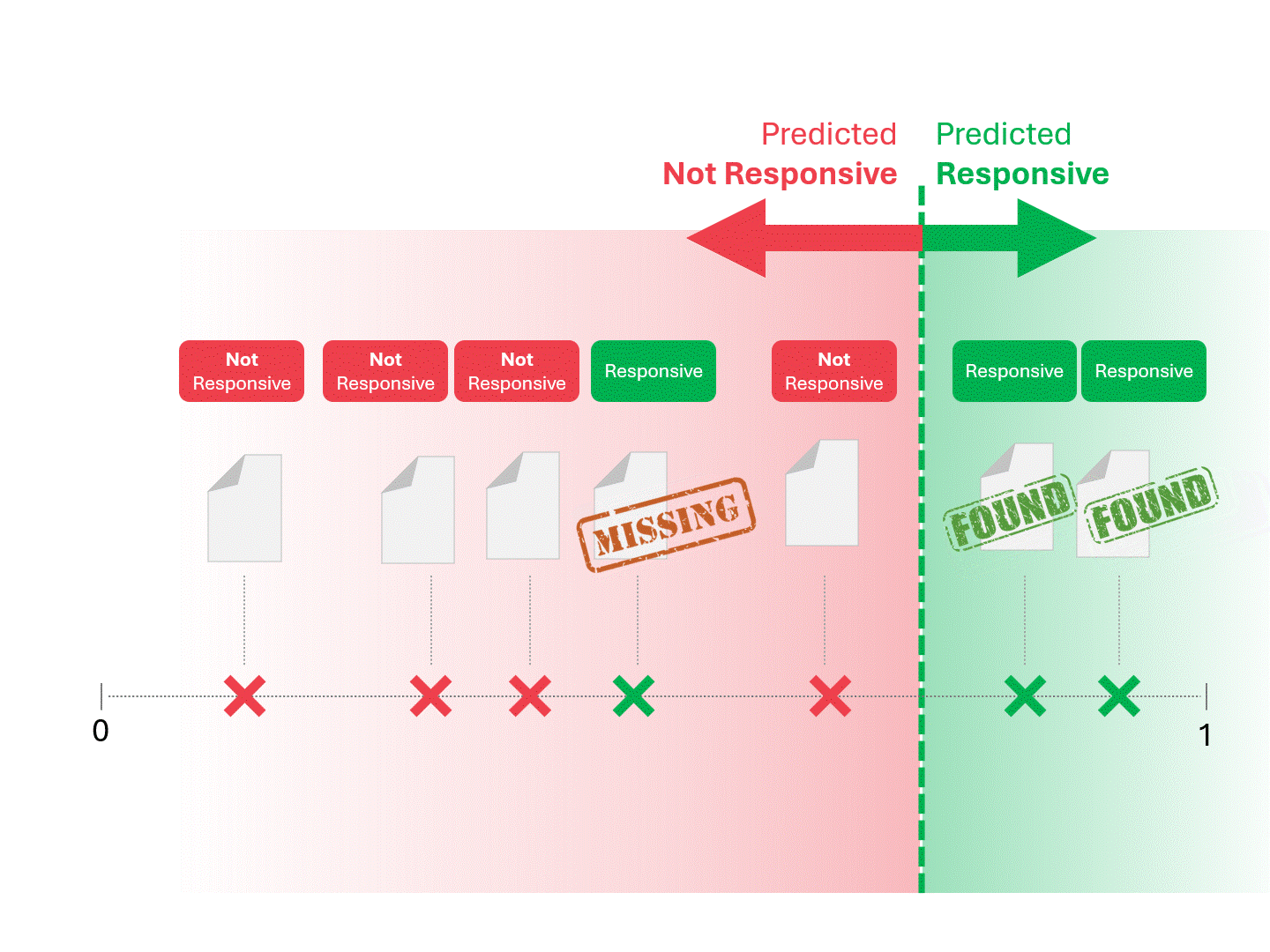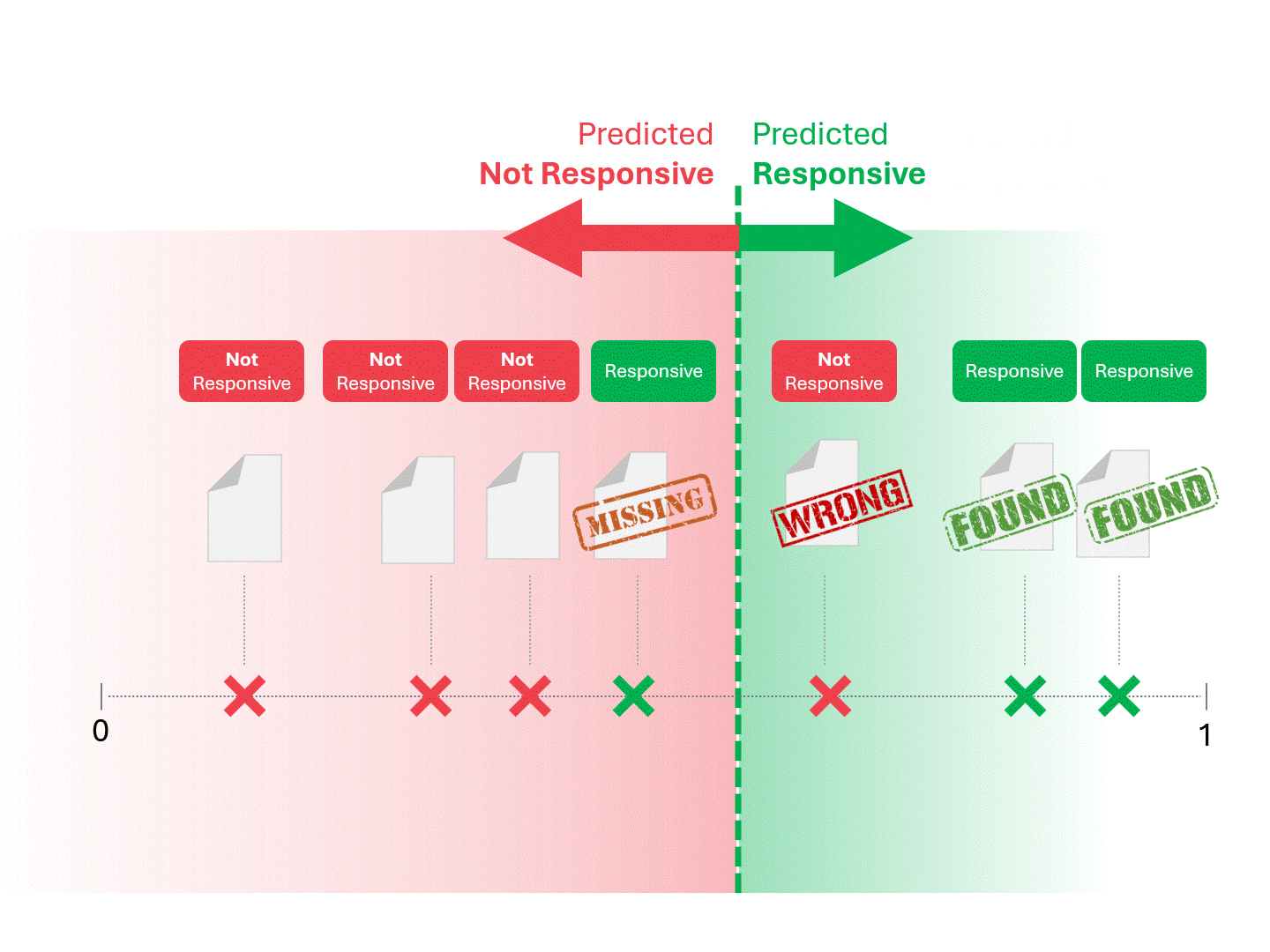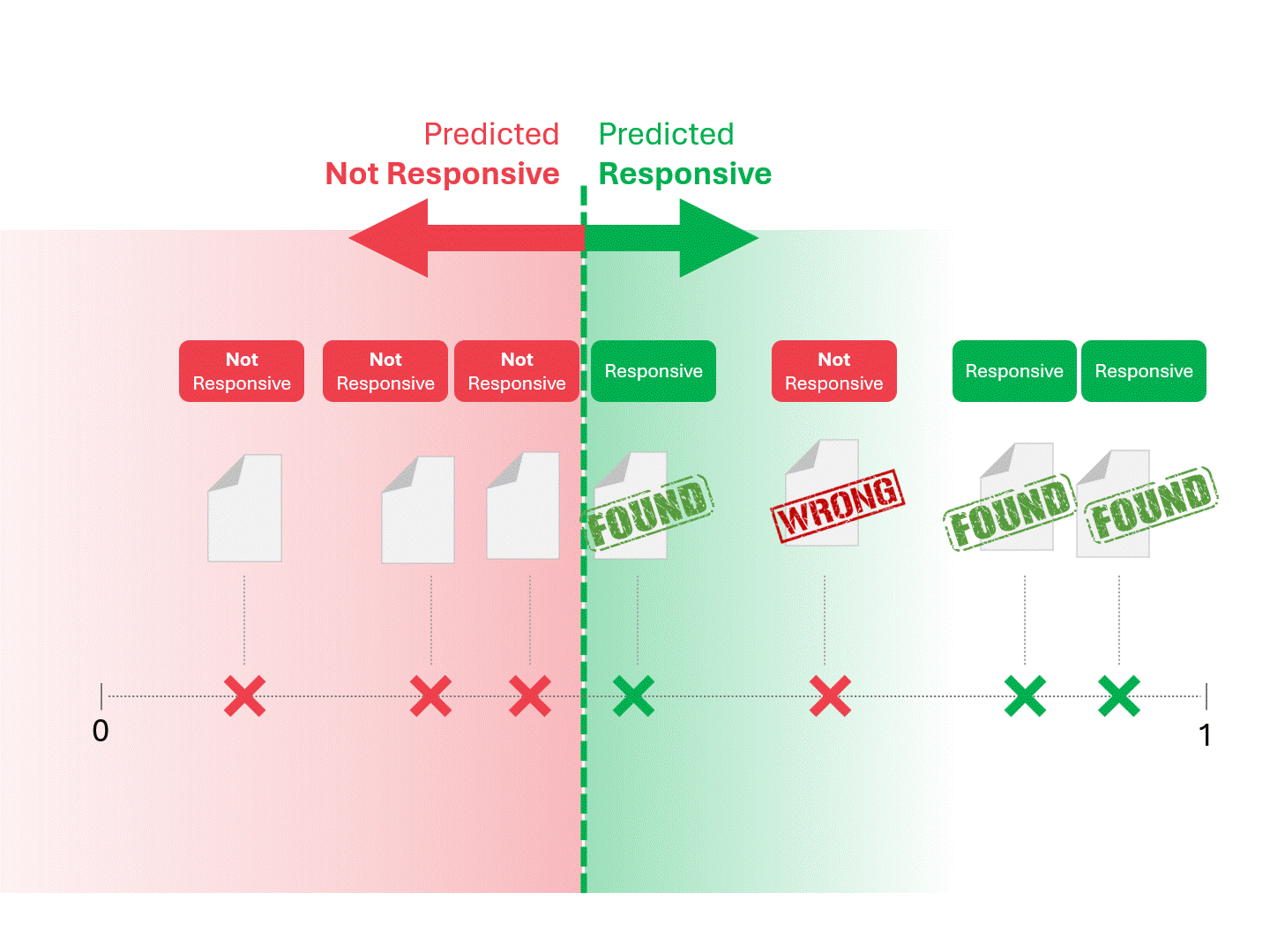
Once our model (TAR 1.0, TAR 2.0, CAL, or LLM) gives a score, we rank examples, and draw a cutoff line:

We decide on responsiveness for each document by drawing a line to separate what the model would call Responsive and Not Responsive. The resulting separation would occasionally have errors, whether false positives or false negatives.
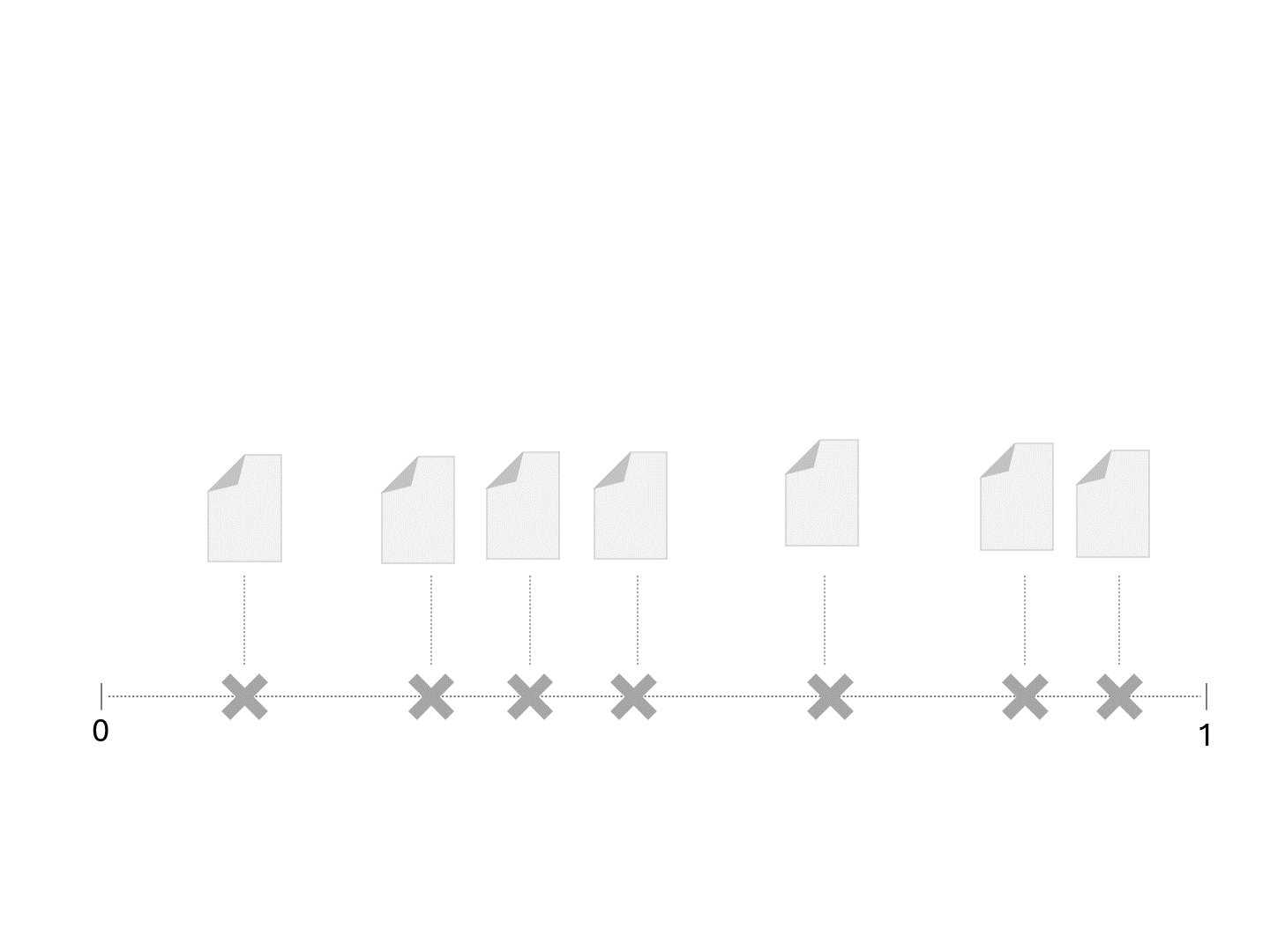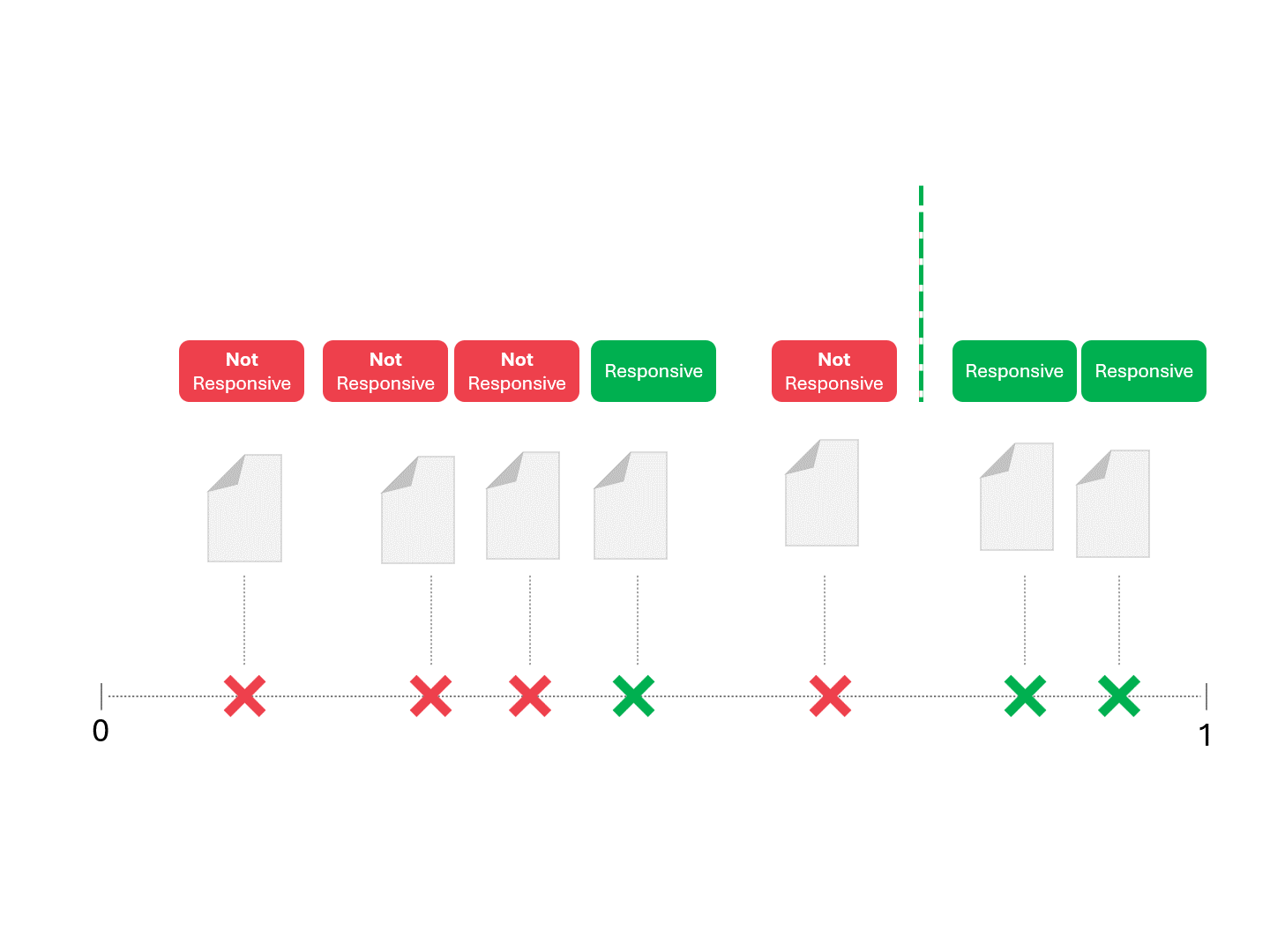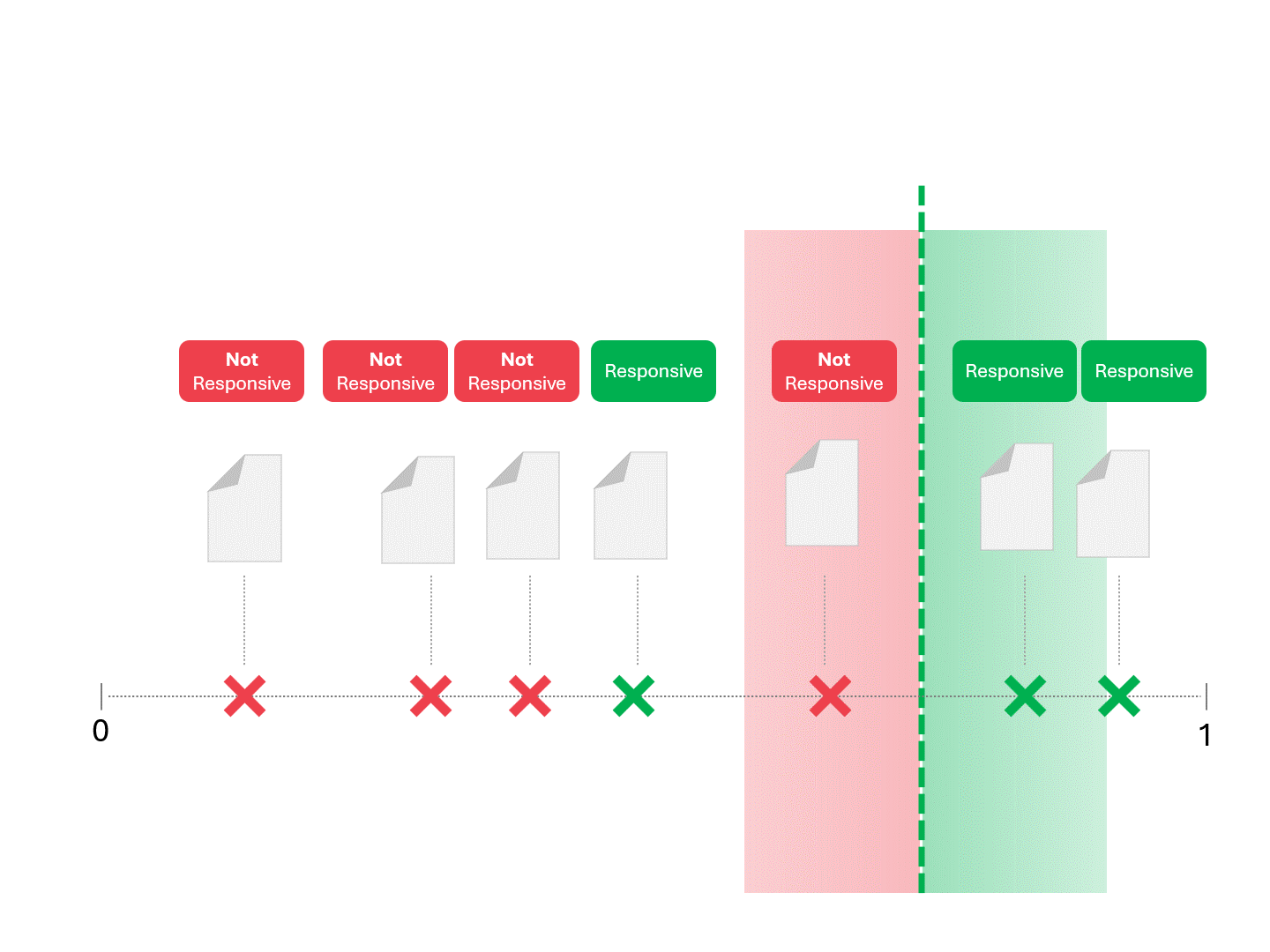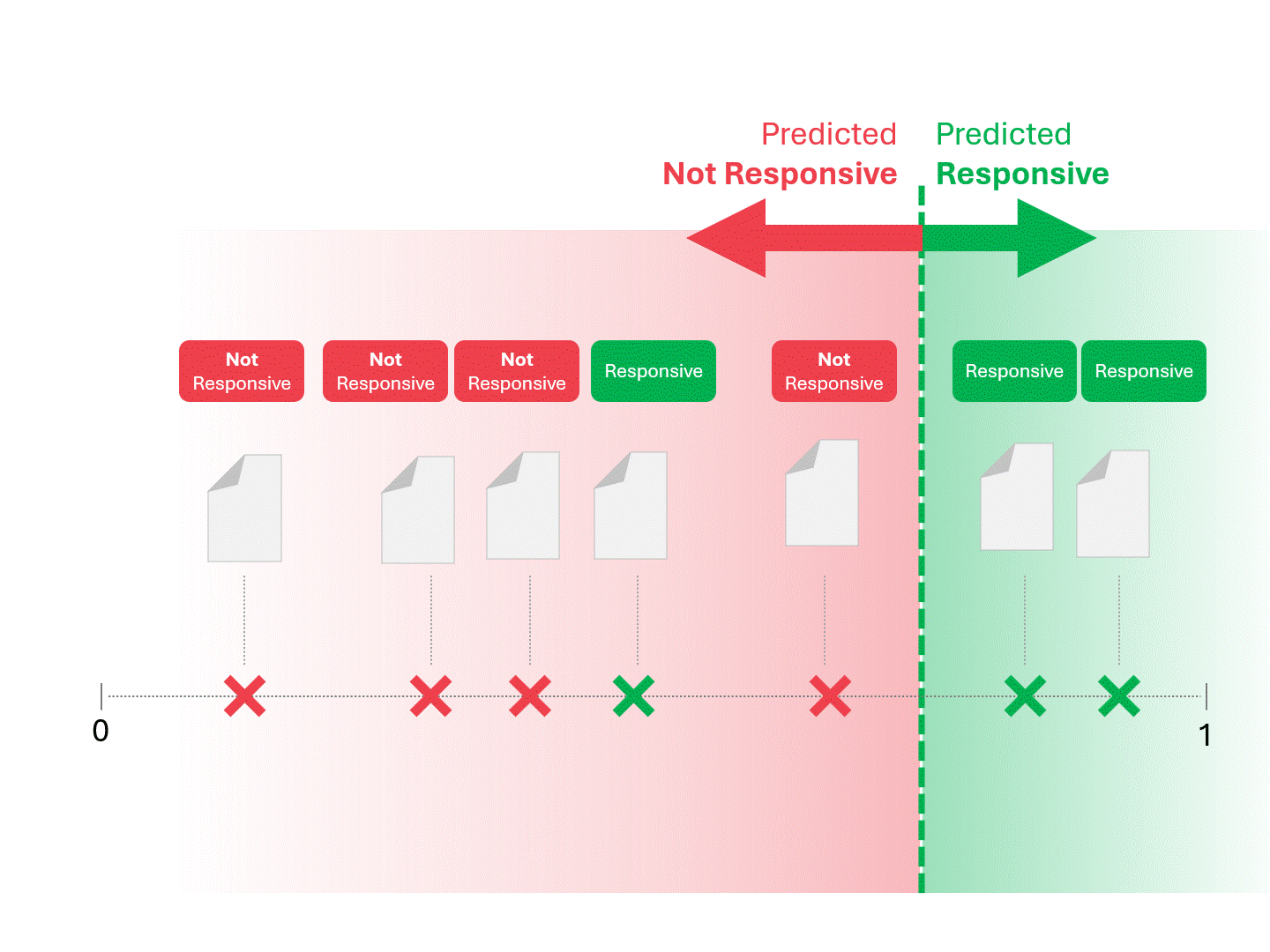
When we change the scoring threshold, we get different results and error rates. For example, inclusivity may get more false positives but miss fewer false negatives, a tradeoff we must accept as part of using any machine learning model. There is no correct answer, instead, it's a value judgment.
The process described above has been standard for as long as TAR has existed. So long as a model gives us a score of some kind, the above method can be used to make predictions.
The only difference between TAR models and LLMs is that scores obtained from an LLM are not deterministic. Running the same model repeatedly on the same exact data would give different scores and therefore a different ranking.
For example, when asking a TAR model for a score repeatedly, we'd expect something like this: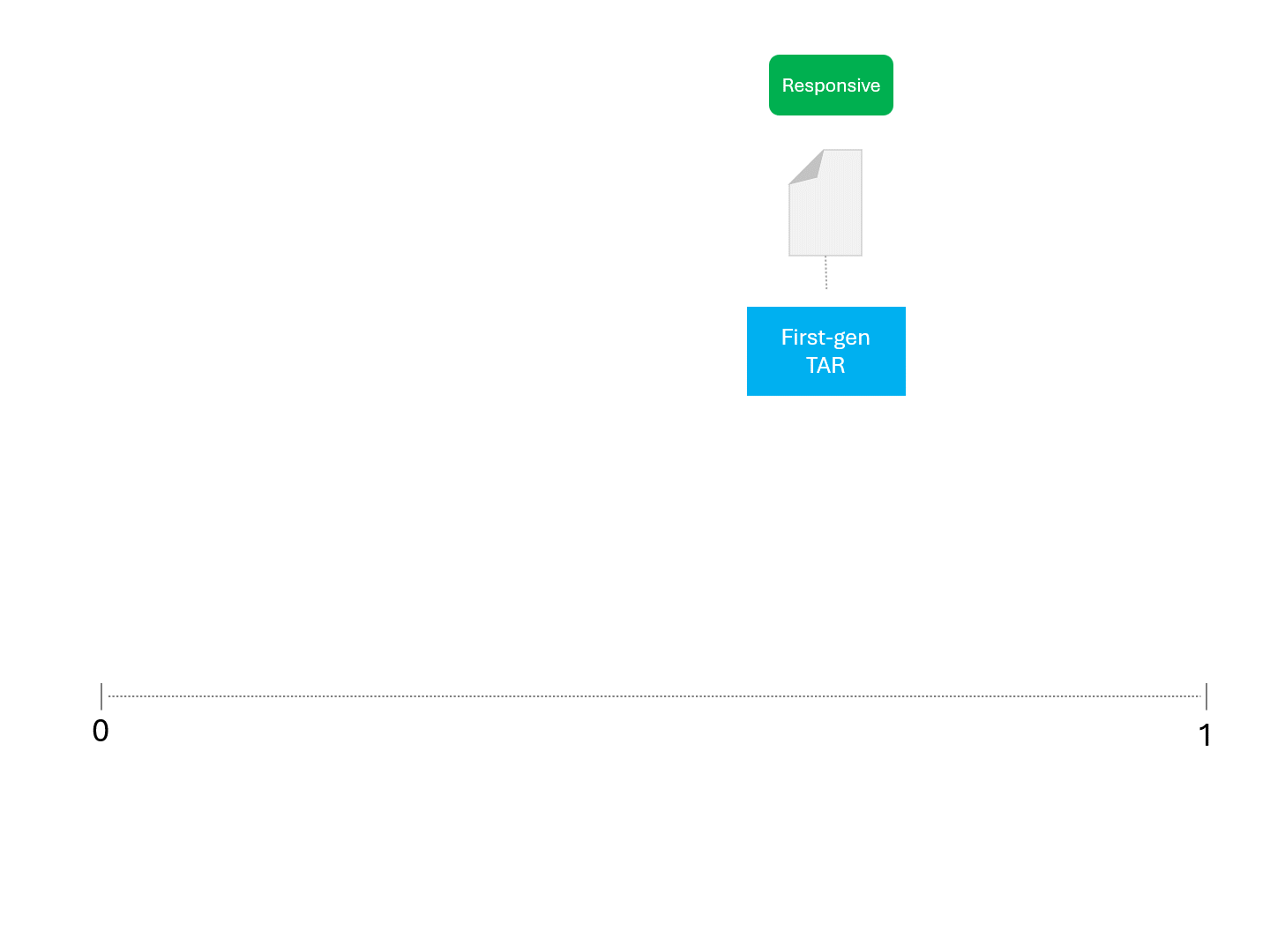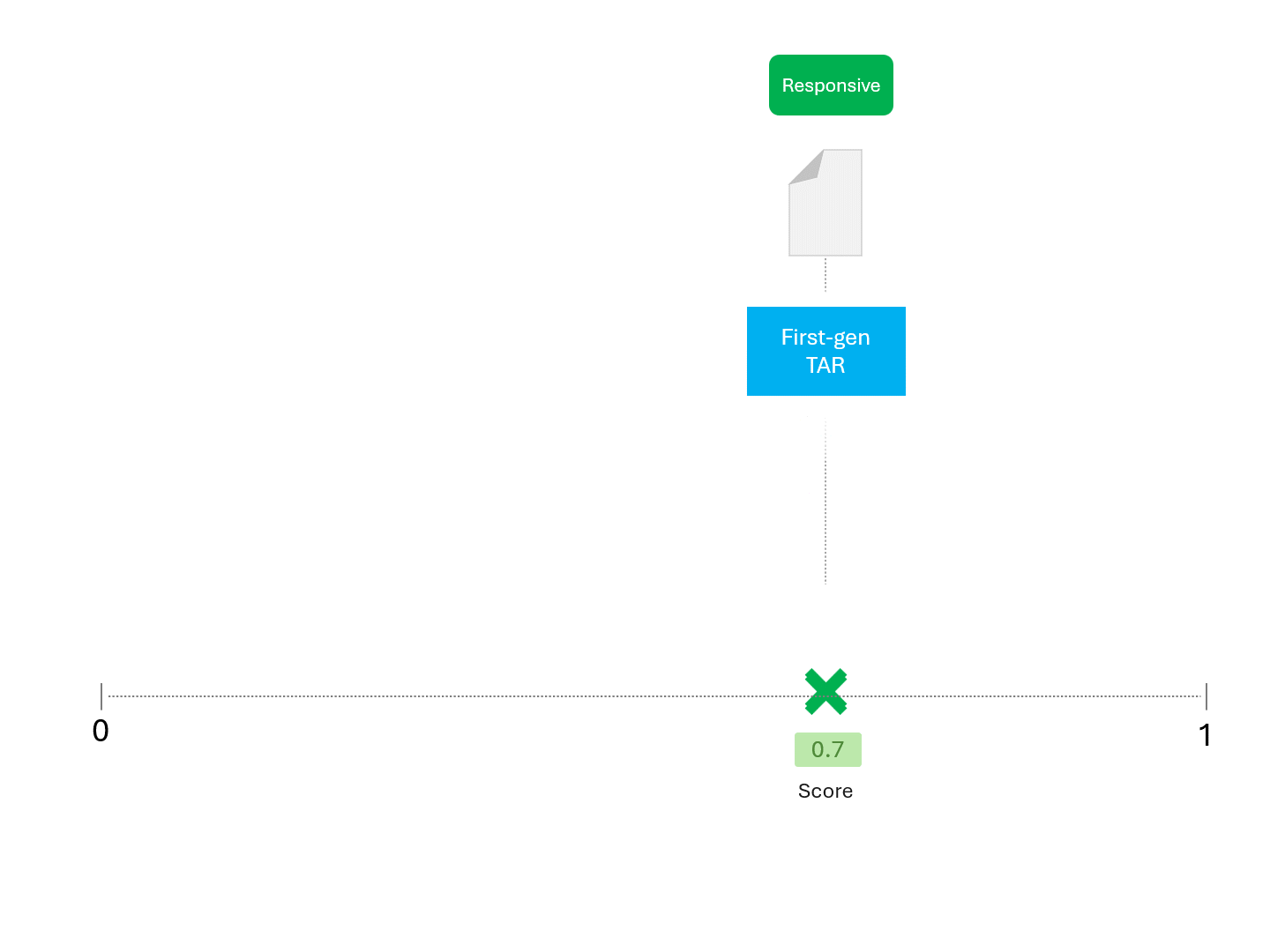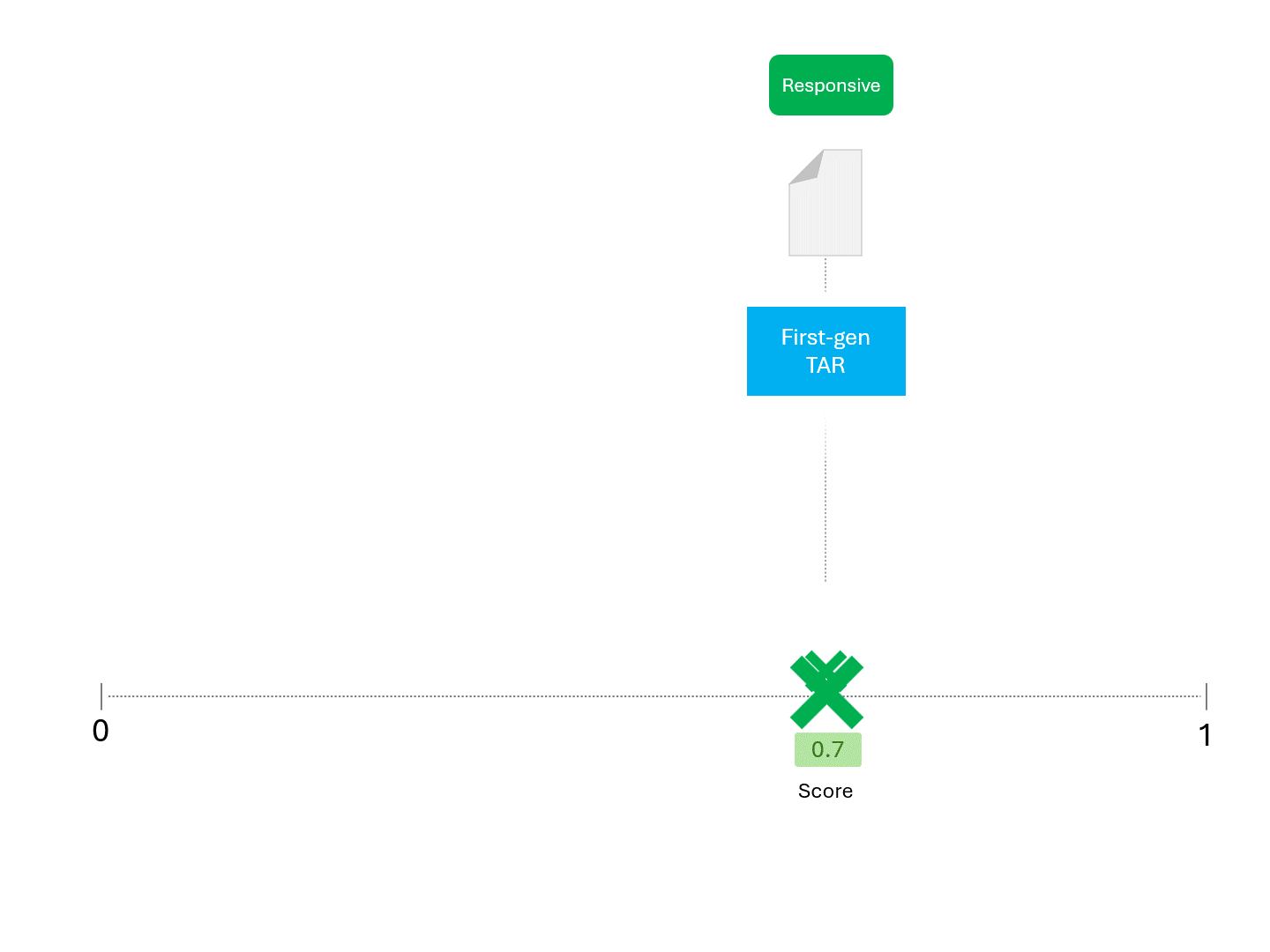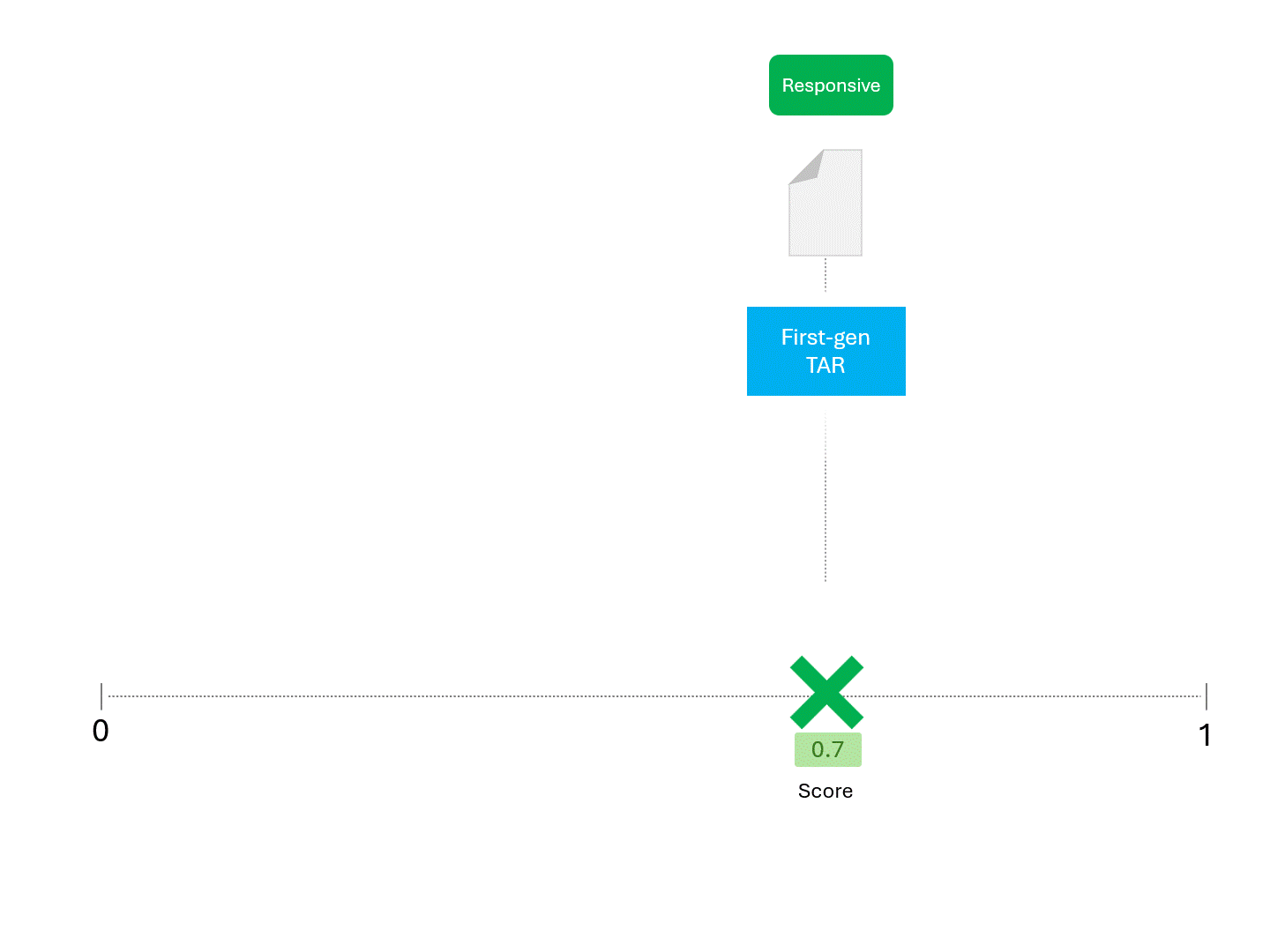
Asking an LLM for a score, on the other hand, would look something like this:
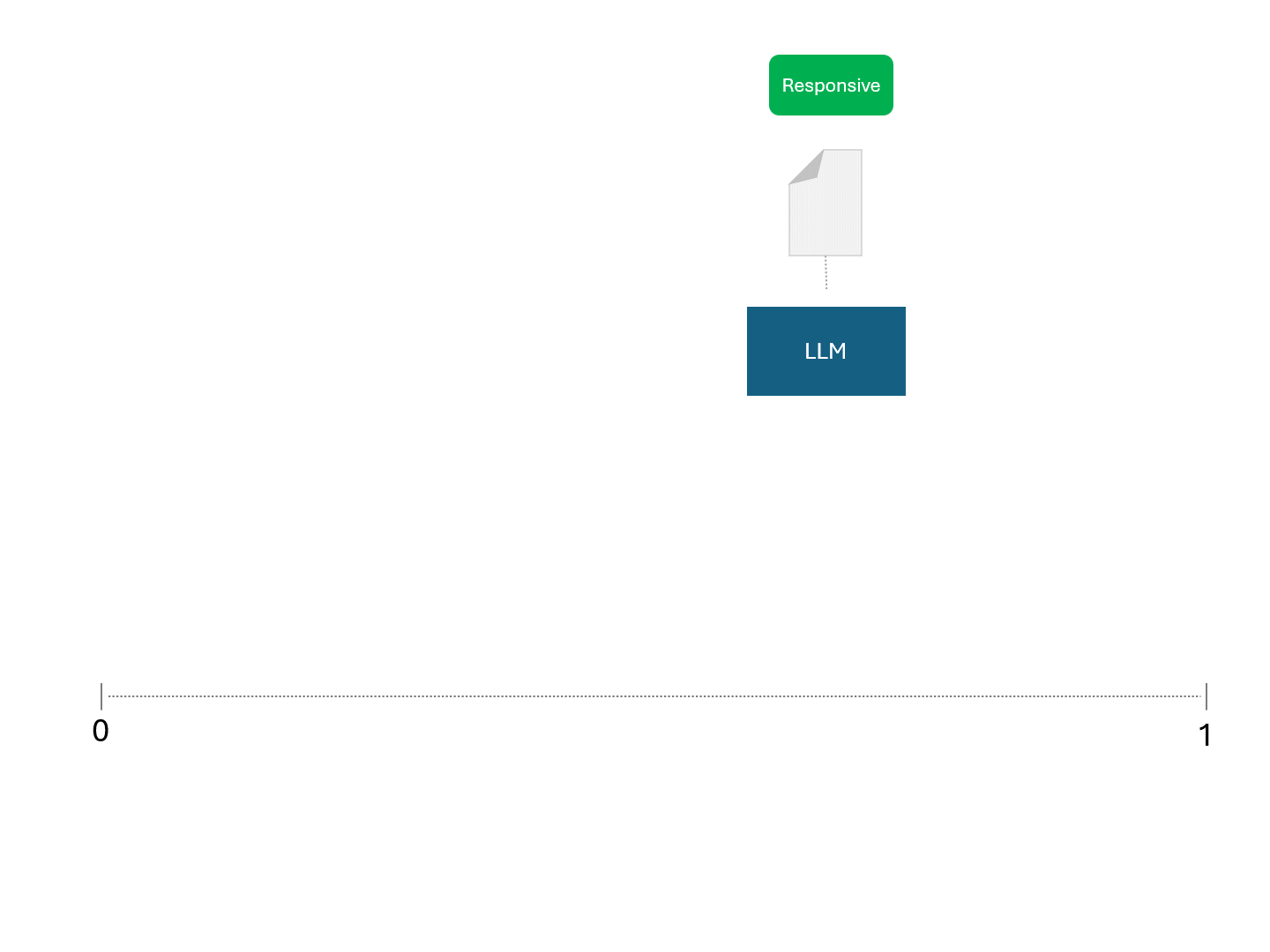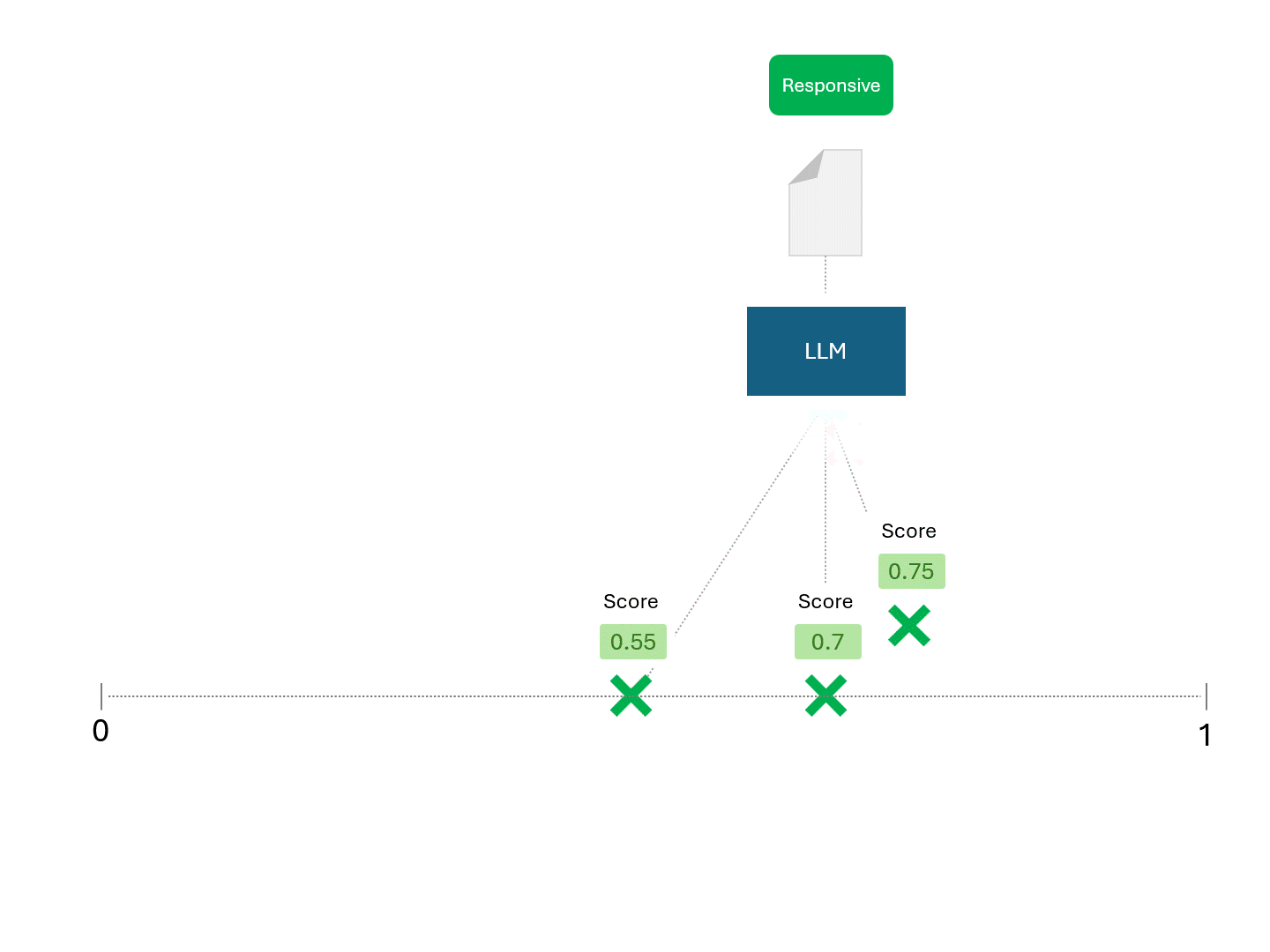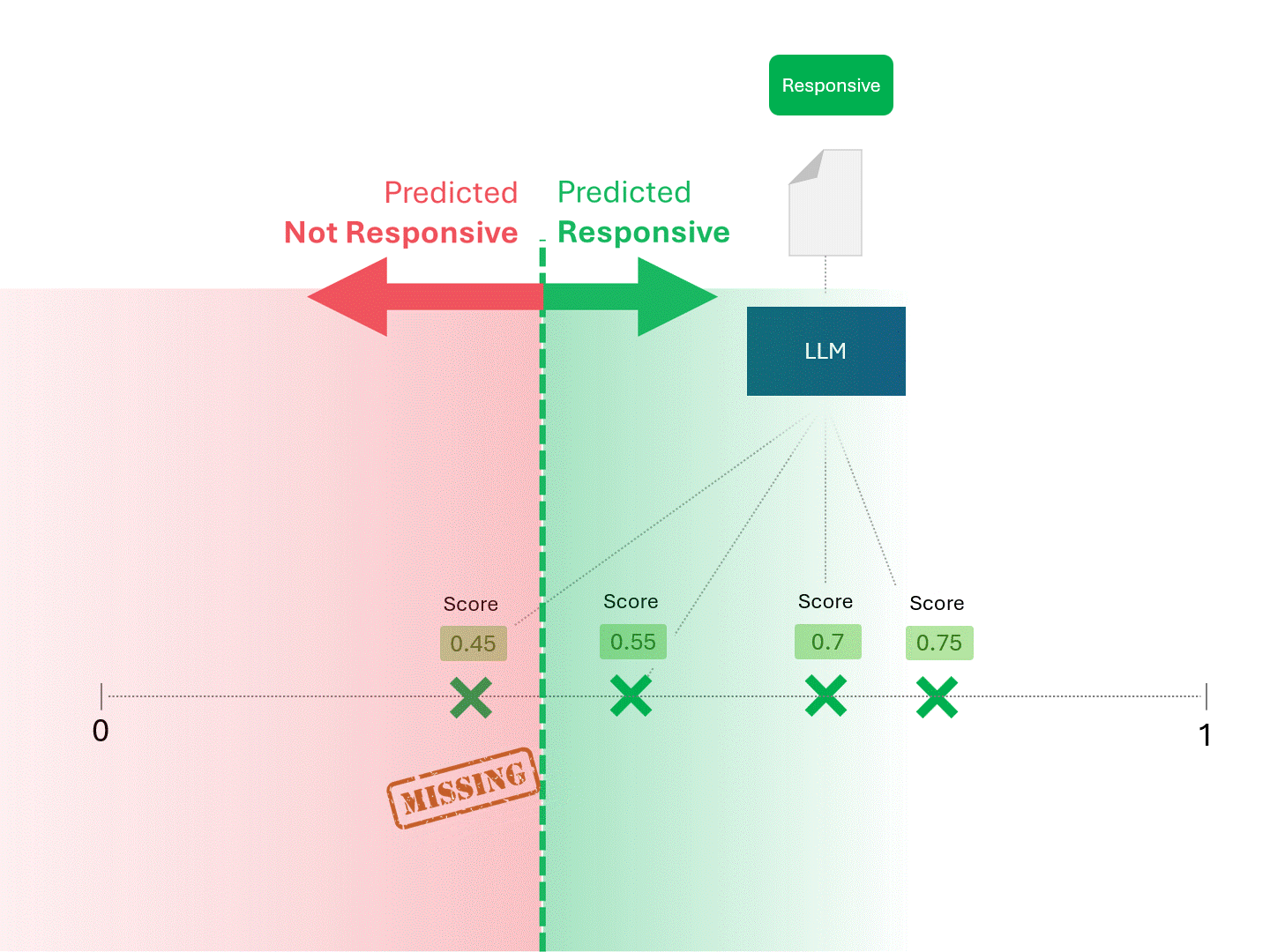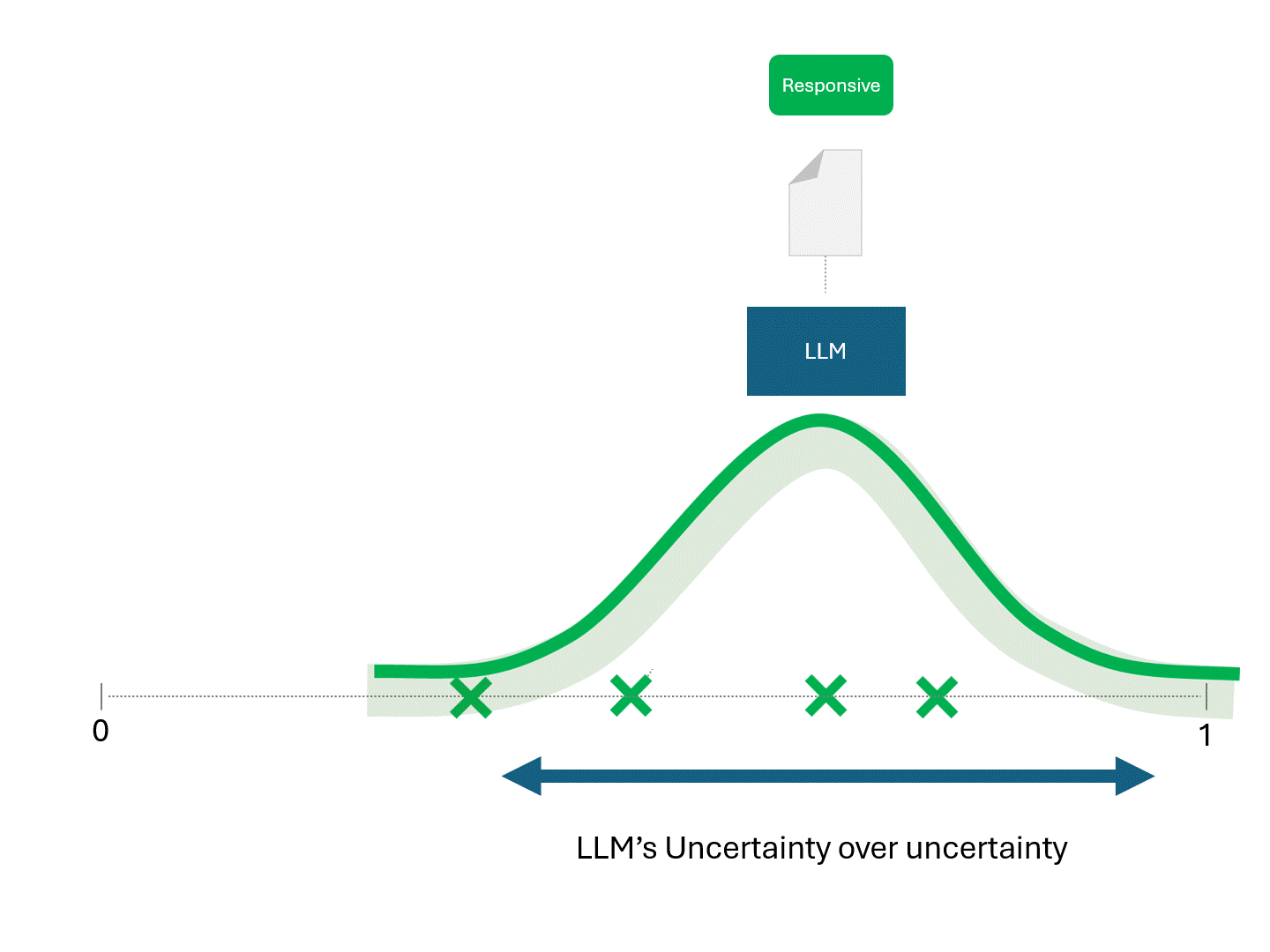
Since different scores would result in different rankings, each time you ask an LLM for predictions, you would also expect different performance metrics like recall and precision.
What Is the Solution?
We mentioned previously that the only way to increase a model's prediction consistency is to average either the predictions themselves or the scores, such as by asking the LLM repeatedly for the score on the same document and then averaging the results. With enough queries, the average would converge to the true prediction score and stabilize, appearing closer to deterministic as with traditional models.
The problem this method would present is that repeating a query to an LLM many times is impractical, especially with something like GPT-4 where costs are often prohibitive.
What Are the Consequences?
Let’s look at what happens when we simply rely on the confidence output of an LLM as it is.
To illustrate the consequences, we compare the Precision-Recall curve for the deterministic model and the model with noise in its predictions, like an LLM.
To simulate this, we take a hypothetical set of scores and add some noise to them. Then, we compare the Precision-Recall curves:
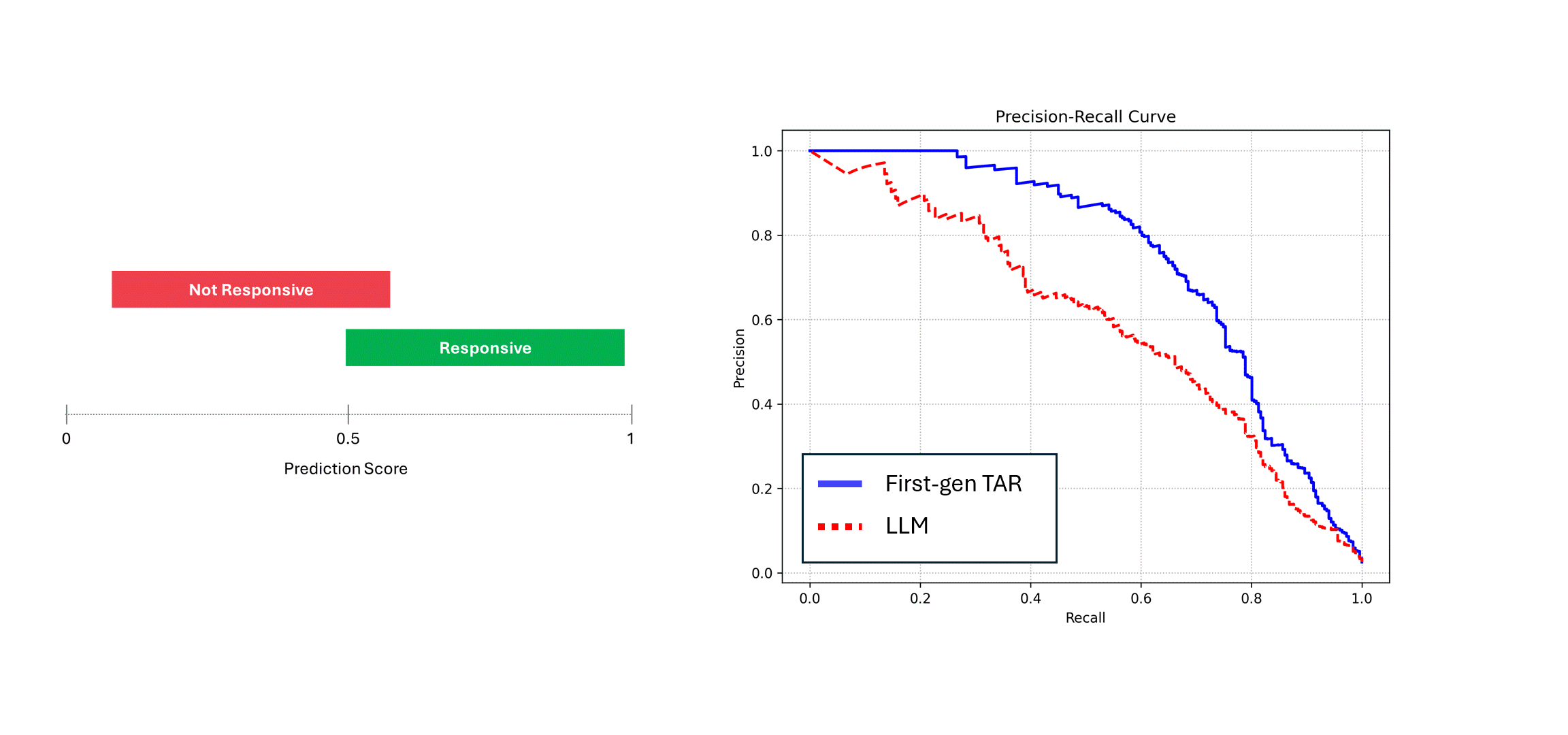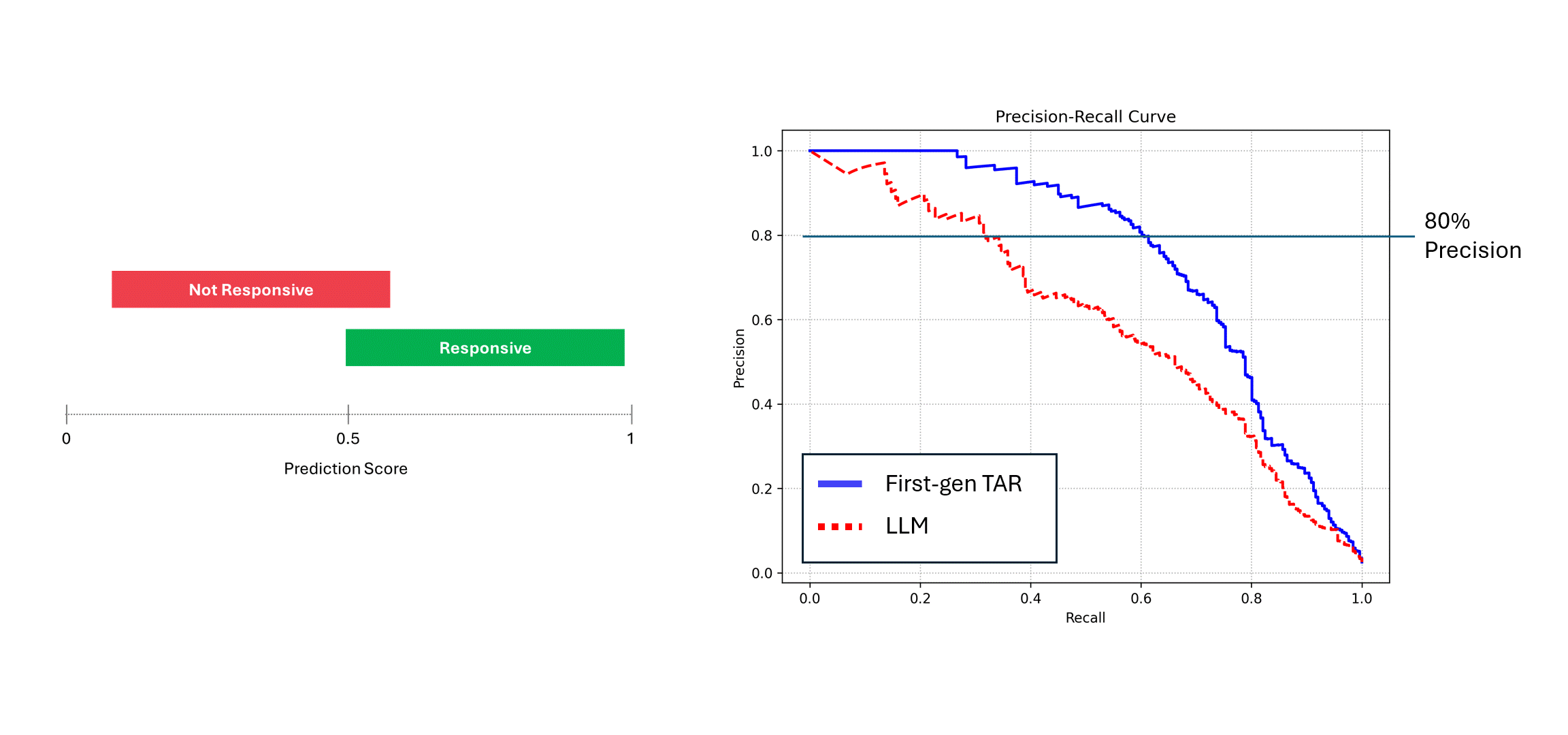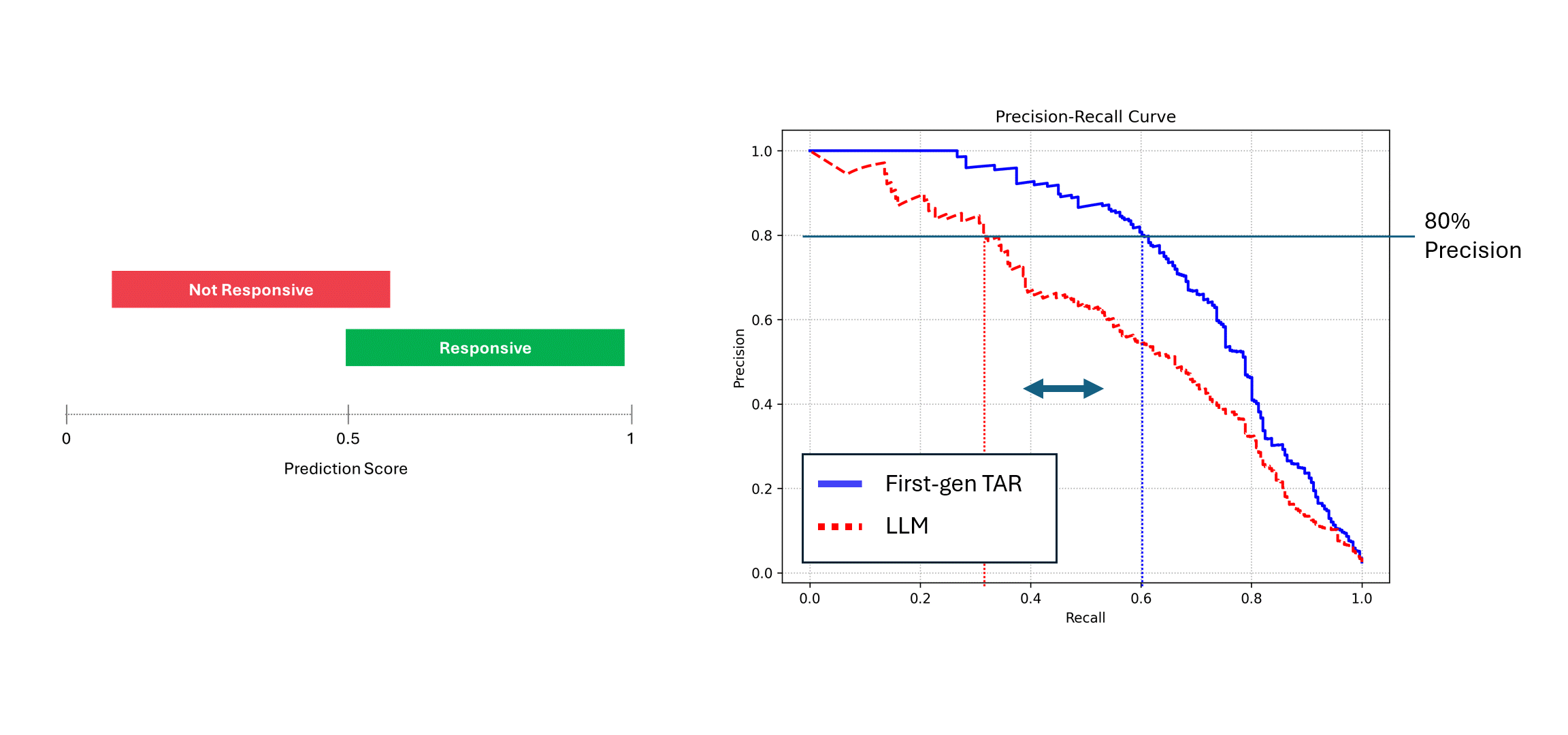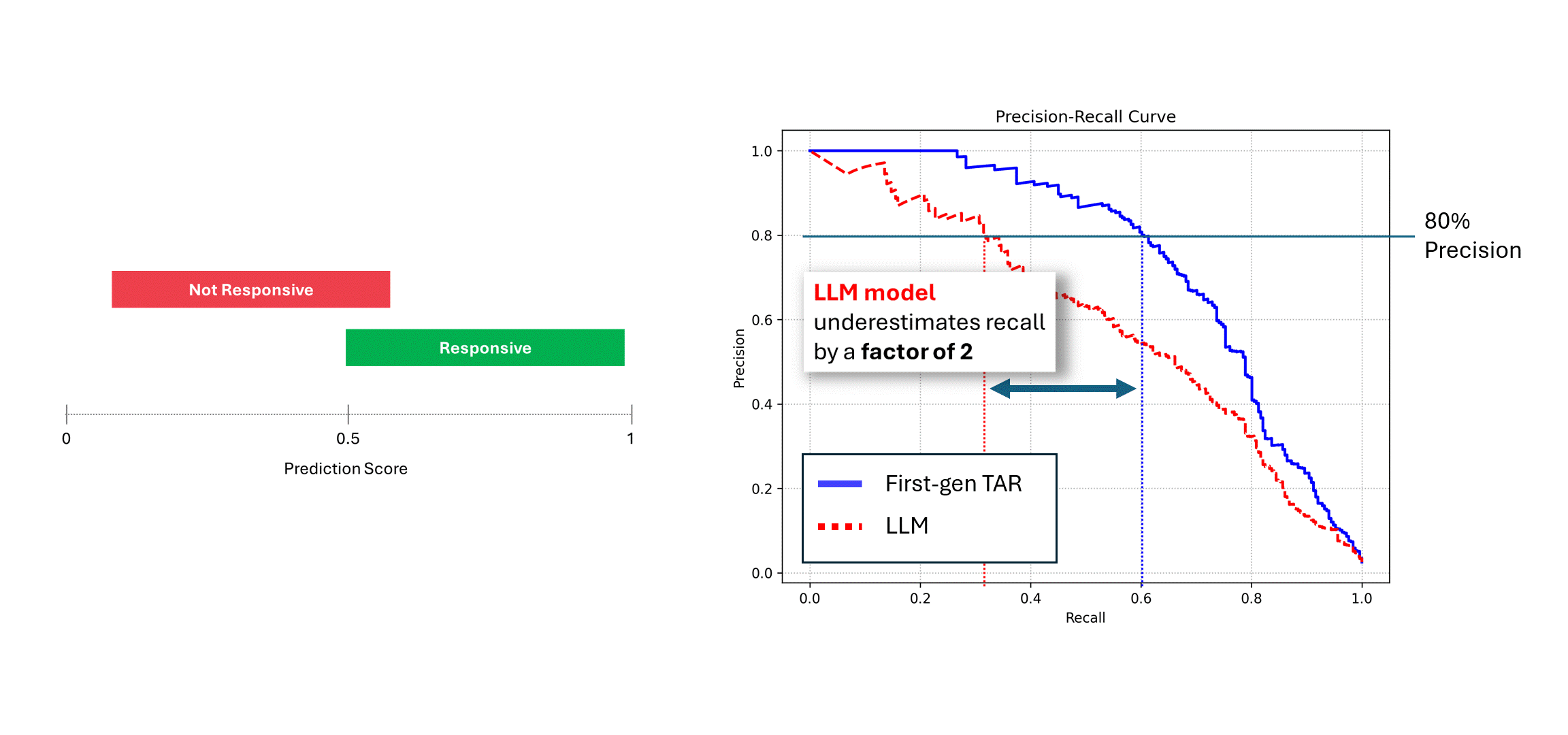 If the noisy model (i.e., an LLM) is run multiple times on the same data, and its scores are averaged, then its Precision and Recall approaches that of a deterministic model, i.e., the blue curve. However, when relying on a single run of its predictions (the red curve), the performance suffers, always underestimating the true performance of the model. In the example above, performance can be reported to be up to half of what it actually is.
If the noisy model (i.e., an LLM) is run multiple times on the same data, and its scores are averaged, then its Precision and Recall approaches that of a deterministic model, i.e., the blue curve. However, when relying on a single run of its predictions (the red curve), the performance suffers, always underestimating the true performance of the model. In the example above, performance can be reported to be up to half of what it actually is.
What Are the Practical Implications?
In practice, when you look at that Precision-Recall curve from an LLM (the red curve above), all you will see is insufficient performance, and you won't know the cause. The instinct is to improve the model's performance, perhaps by tuning prompts or adding some examples.
In this case — all that effort would be wasted. The performance gap is not because the model itself isn't good enough, but because its non-deterministic nature underestimates the model's performance. The only way to close that performance gap is to ask the LLM for scores multiple times and average its predictions.
Given that you won't be running your model 10x on each document simply for cost and time reasons, are there any solutions to ensure the model's performance is reported accurately? The answer is yes — we look at it in our next blog post. Stay tuned!

Igor Labutov, Vice President, Epiq AI Labs
Igor Labutov is a Vice President at Epiq and co-leads Epiq AI Labs. Igor is a computer scientist with a strong interest in developing machine learning algorithms that learn from natural human supervision, such as natural language. He has more than 10 years of research experience in Artificial Intelligence and Machine Learning. Labutov earned his Ph.D. from Cornell and was a post-doctoral researcher at Carnegie Mellon, where he conducted pioneering research at the intersection of human-centered AI and machine learning. Before joining Epiq, Labutov co-founded LAER AI, where he applied his research to develop transformative technology for the legal industry.
The contents of this article are intended to convey general information only and not to provide legal advice or opinions.
