


如何部署大型语言模型(上):模型该放在哪里?
- Legal Transformation
在第一代人工智能模型问世之初,法律行业技术供应商很少被问及“模型部署在何处”的问题。
人们始终认为模型与数据同处一地。例如,若您持有本地部署的电子取证软件许可证,模型便“本地化”存在于您的数据中心或云实例中。
如今,随着大型语言模型(LLMs)的出现,客户面临着一种兼具强大能力与复杂挑战的新型技术。下文将详细阐述您应向供应商提出的问题,以及如何通过其回答来评估解决方案的质量与性能,并理解其中涉及的安全与隐私影响。
为何此刻发问?
“你的模型部署在哪里?”这个问题突然变得普遍,因为这些模型—尤其是大型语言模型(LLMs)—已经超出了大多数《财富》100强企业可用的计算资源范围,更不用说解决方案提供商自身了。因此,极少数企业具备构建和训练大型语言模型的资源。OpenAI GPT、Anthropic Claude和Google Gemini等公司承担了巨额投资,并通过API开放其模型。过去几年间,它们催生了数千家服务商,将API服务打包纳入自身解决方案。在法律服务领域,我们常在文件审查、文档摘要和合同审核等环节看到这些迭代应用。
第三方服务的广泛可用性带来了显著优势,但也引发了我们此前未曾遇到的新问题:
- 我与第三方大型语言模型共享了哪些信息?
- 我的信息是否被存储并用于改进其模型?
- 我是否能控制这些模型?若不能,控制权在谁手中?
随着更多开源大型语言模型(LLMs)的出现,待解决的问题清单只会越来越长。在具备适当基础设施的情况下,这些模型使得构建完全不依赖第三方供应商的部署方案成为可能。在这种情况下,理解避免依赖第三方服务提供商的解决方案所能获得的收益与需要付出的代价就显得尤为重要。
大型语言模型通常如何部署?
大型语言模型服务存在多种部署方案,其中部分方案我们可能已相当熟悉,而另一些则是因需求演变而产生的。
在传统的第一代人工智能应用中,例如合同审查或文件审查这类主要涉及分类任务的场景,人工智能模型体积足够小巧,能够与数据共同存放—无论是部署在自有数据中心还是托管云端,都可与其他客户的数据隔离:
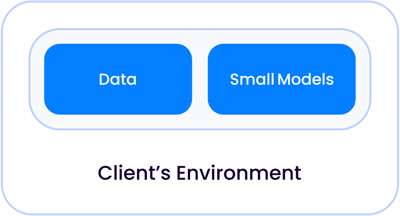
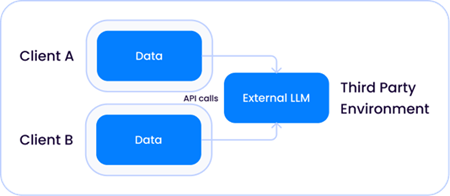
随着模型规模呈指数级增长,演变为如今我们所称的LLM,这些模型相对于您的数据存在两种运行场景:
1. 由OpenAI等公司托管的共享第三方模型,该LLM既独立于解决方案提供商,也独立于您的环境:
2. 由您的解决方案提供商在其云环境中直接托管和部署的法律信息系统:

(服务提供商在托管大型语言模型时需承担高昂的计算和基础设施成本,因此很可能将大型语言模型作为共享服务部署给客户。)
鉴于当前存在多种部署架构,自然会产生这样的疑问:
解决方案提供商依赖OpenAI等外部API服务是否存在风险?
如同所有问题一样,普遍答案是“视情况而定”—需考虑以下三个因素:
1. 第三方(如OpenAI)对其API接收的数据保留的程度。
服务提供商对发送至其API的数据保留时长有不同政策,这些政策很可能源自其与第三方LLM API供应商签订的服务条款。
例如,微软对发送至其GPT API的所有数据默认采用30天保留政策;但解决方案提供商可协商豁免条款,许多企业已获得零天保留政策。
我们建议您直接向解决方案供应商咨询其与第三方API服务商达成的数据保留政策,必要时可根据组织需求进行优化。
需注意区分数据保留与数据使用。数据保留并不意味着第三方可利用您的数据训练其模型—根据多数服务协议,第三方无权使用您的数据。
2. 所发送数据的性质与数量。
数据的性质和数量完全取决于具体应用场景。例如,仅使用公共数据(如公开法庭文件)外部API的解决方案,其风险特征就与将客户取证数据发送至API的解决方案截然不同。进一步细分来看,不同解决方案提供商在取证应用中向API传输的敏感数据量可能存在巨大差异。例如,针对性数据问答解决方案通常最多仅向外部API发送通过搜索引擎检索到的十余份文档片段。而依赖第三方API进行文档分类的解决方案,则需传输数百万份文档。
3. 第三方服务条款中关于其对您数据的处理权限。
最后,需要明确的是:随着为大型语言模型提供服务的第三方API供应商数量增加,它们在处理接收到的数据方面并非完全平等。例如,OpenAI直接提供的GPT-4 API可明确将用户数据用于模型优化,而通过微软Azure提供的同款GPT-4模型则不具备此功能。务必向解决方案供应商确认其外部API服务条款,明确对方对用户数据的具体权限边界。
那么部署自有LLM模型的解决方案提供商呢?是否存在风险?
当解决方案提供商部署LLM(通常基于现有开源模型如Llama-3)时,他们对数据保留和使用拥有直接控制权。如前所述,解决方案提供商部署的LLM往往需要大量计算资源—以及可观的资金投入—因此很可能采用共享架构:
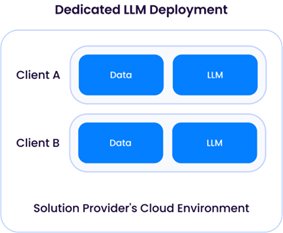
“专用大型语言模型部署”要求解决方案提供商为单一客户配置计算资源(CPU/GPU/内存)。这意味着需从云服务商租用充足的GPU资源,从而导致运营成本上升。该方案的优势在于:解决方案提供商能够灵活地为每位客户定制大型语言模型,利用其专属数据优化模型,且不会与其他客户的数据混合使用:
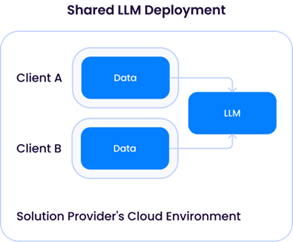
然而,共享大型语言模型(LLM)架构将引发与前文所述第三方LLM服务提供商实例类似的问题。尽管乍看之下令人担忧,但只要不同客户的数据不被用于更新底层LLM,该架构便与OpenAI等第三方API服务高度相似,且(至少理论上)具有相同的风险特征。
深入了解Epiq提供AI解决方案的方法,以及对负责任AI开发的承诺。
 伊戈尔·拉布托夫,Epiq人工智能实验室副总裁
伊戈尔·拉布托夫,Epiq人工智能实验室副总裁
伊戈尔·拉布托夫现任Epiq副总裁,并共同领导Epiq人工智能实验室。作为计算机科学家,他专注于开发能够从自然人类监督(如自然语言)中学习的机器学习算法,在人工智能与机器学习领域拥有逾十年研究经验。拉布托夫在康奈尔大学获得博士学位,后于卡内基梅隆大学担任博士后研究员,期间在以人为本的人工智能与机器学习交叉领域开展开创性研究。加入Epiq前,他联合创立LAER AI公司,将研究成果应用于开发颠覆性法律行业技术。
本文的内容仅旨在传达一般信息,不提供法律建议或意见。