

Angle

为何依赖LLM置信度评分存在风险
当涉及LLM的置信度评估时,对预测结果进行评分至关重要。关键不在于评分本身,而在于这些评分生成的排序结果。
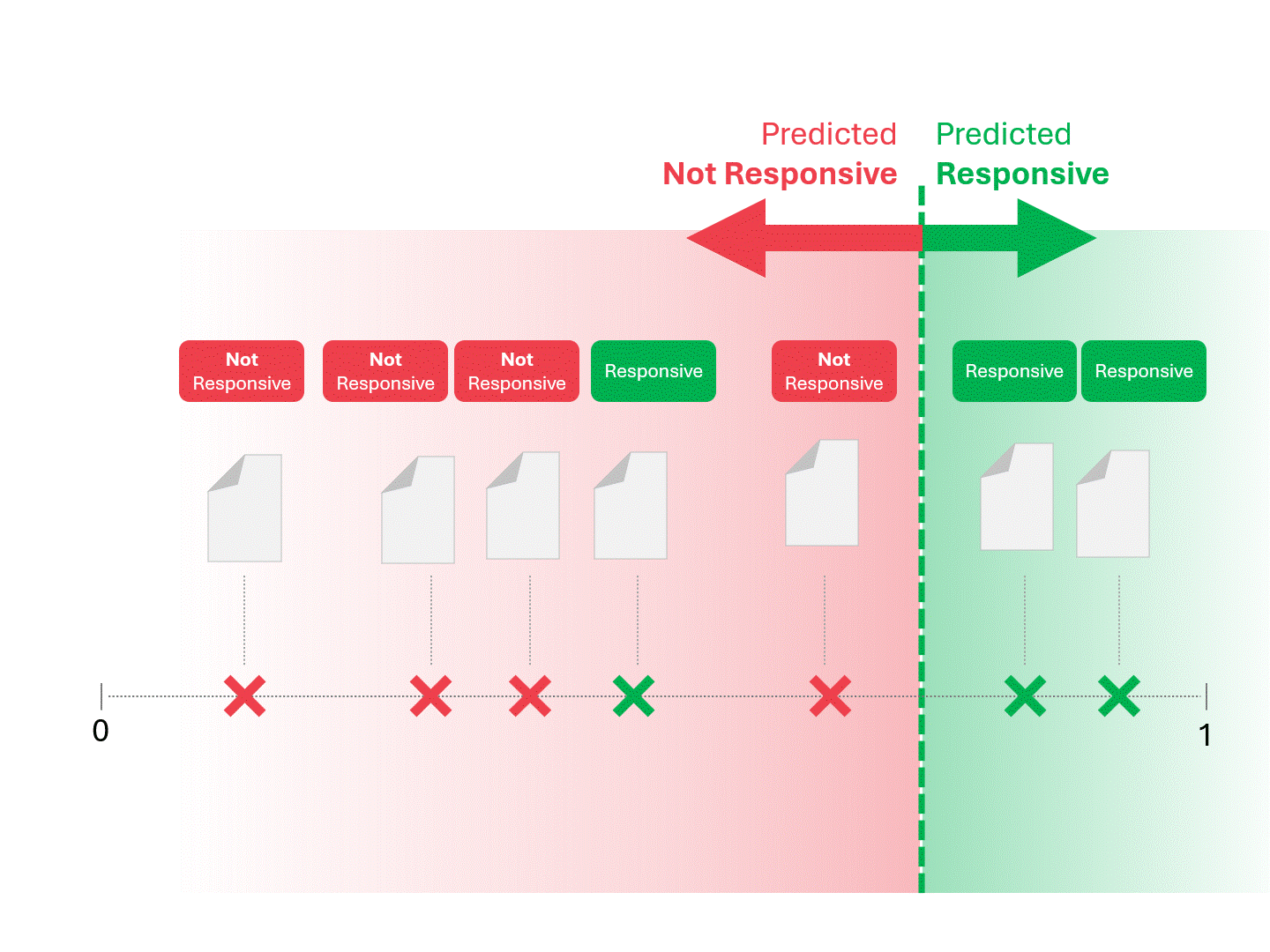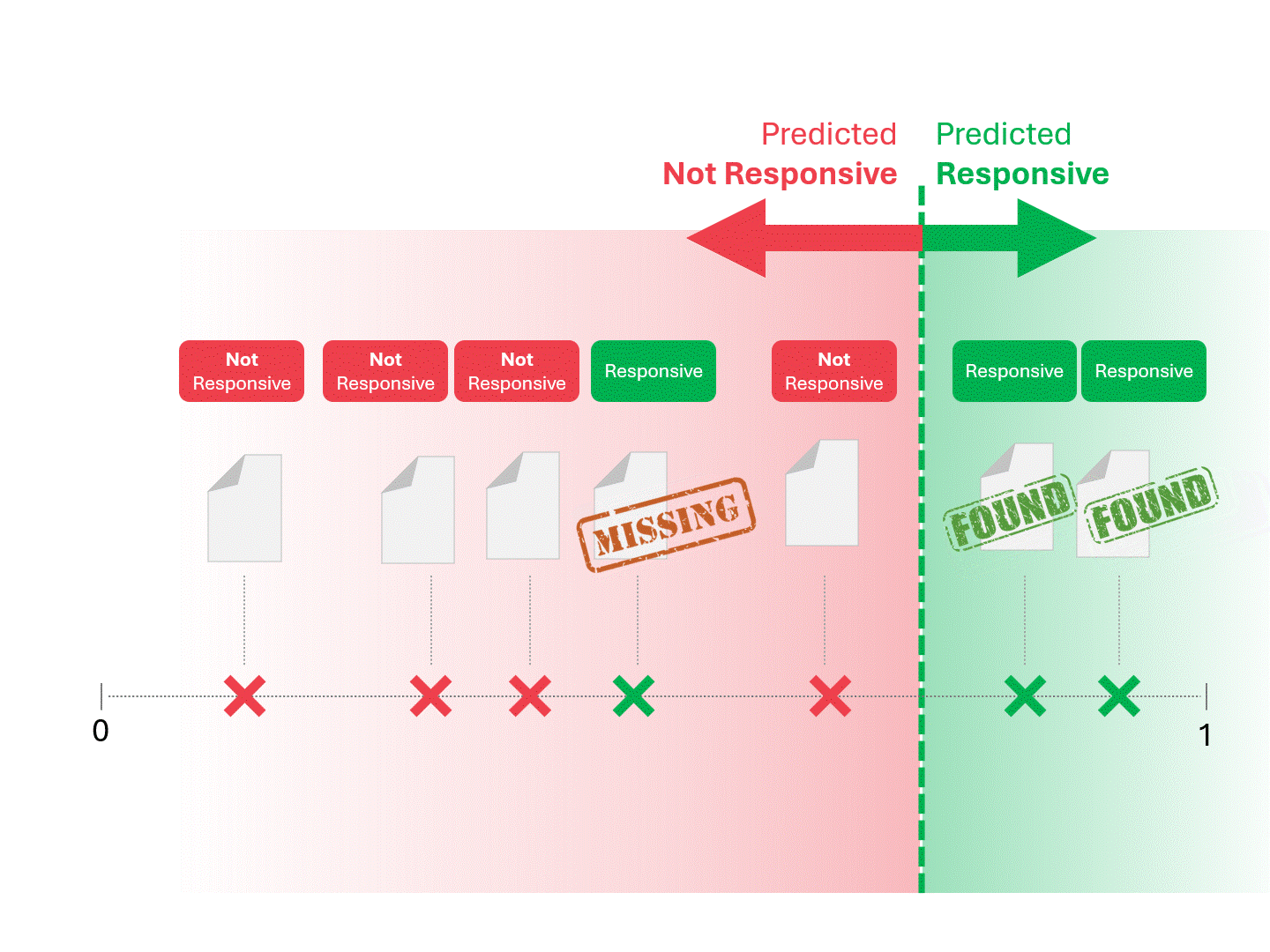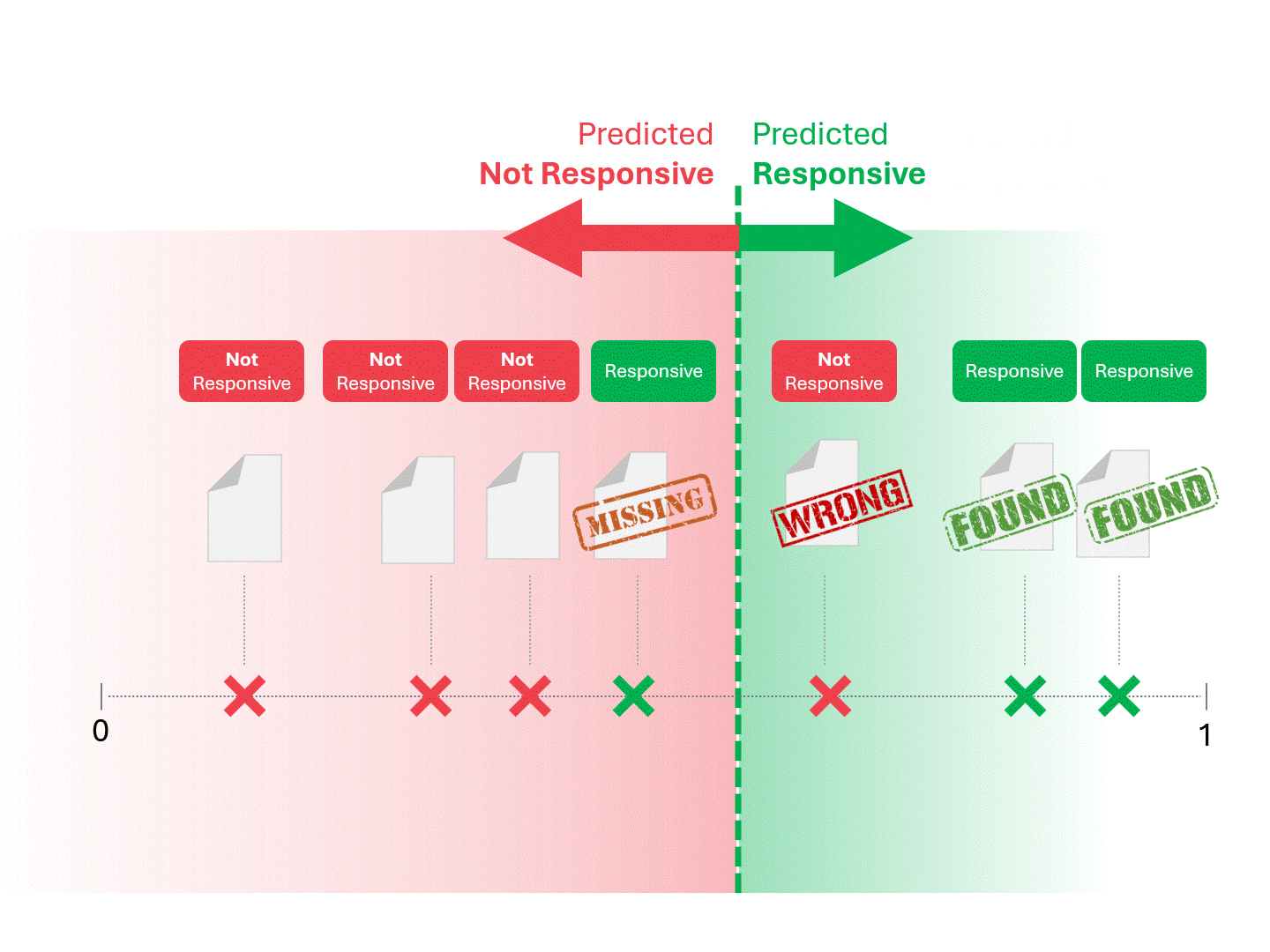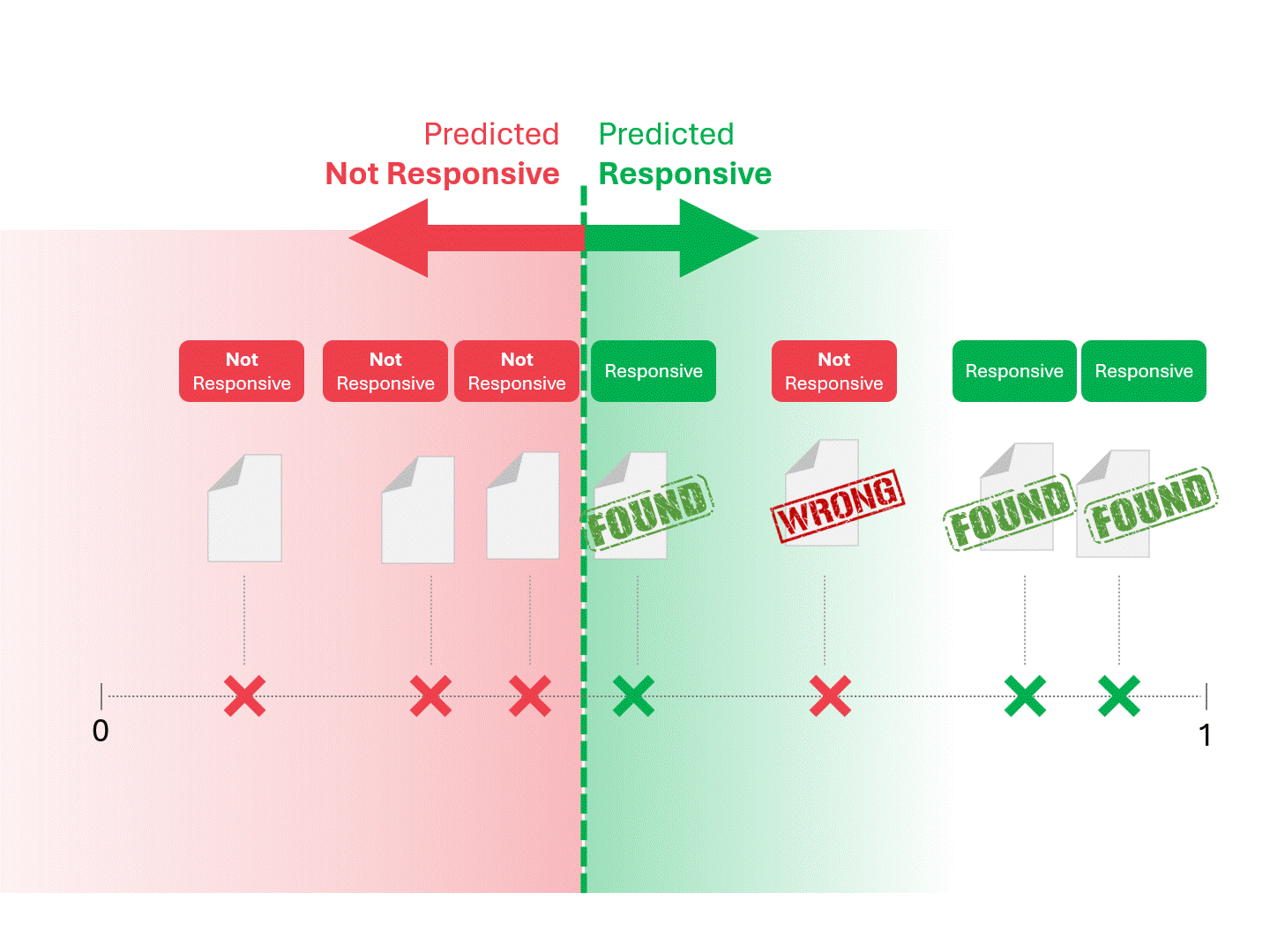
一旦我们的模型(无论是TAR 1.0、TAR 2.0、CAL还是LLM)给出评分,我们就会对案例进行排序,并划定分界线:
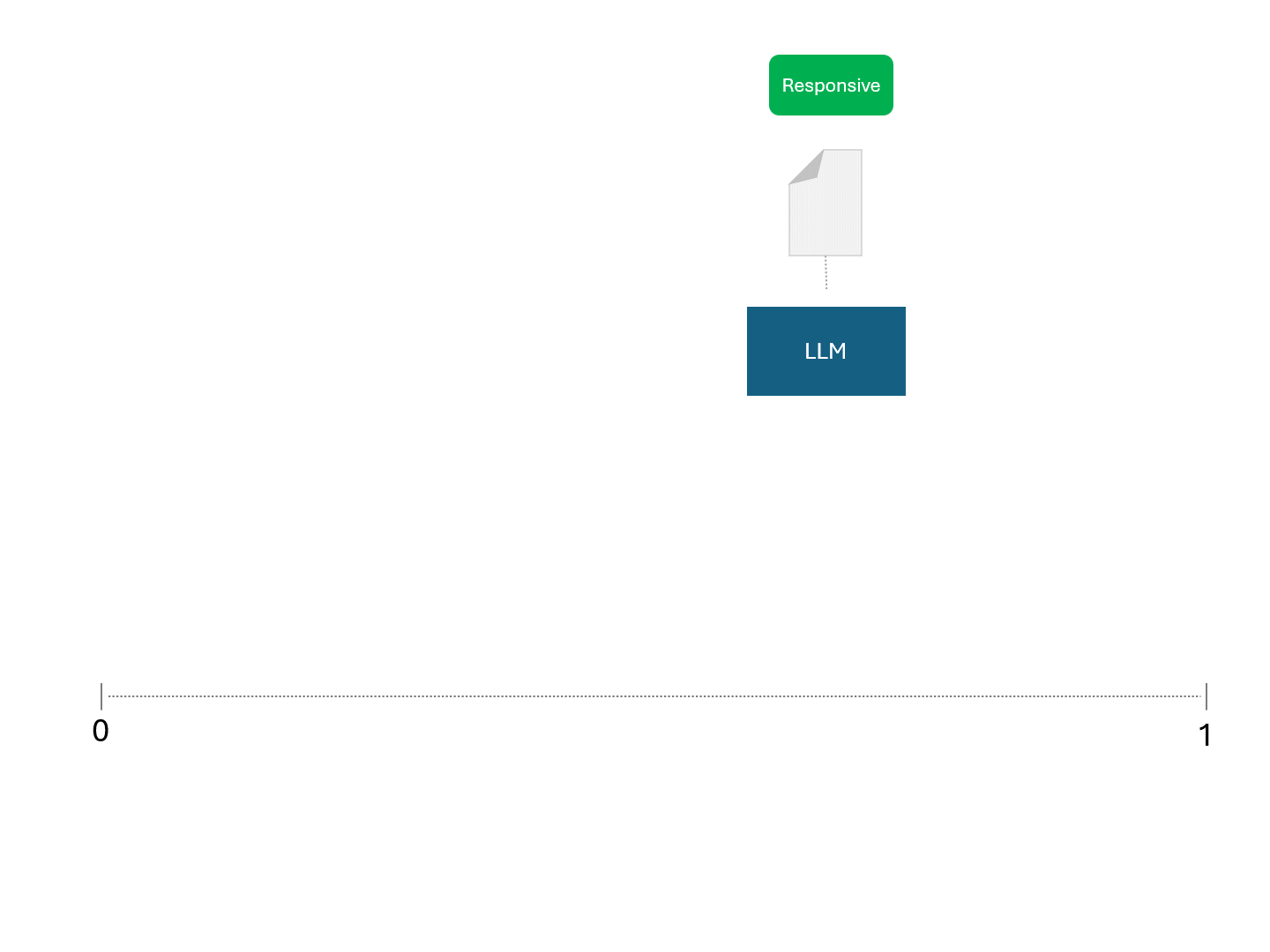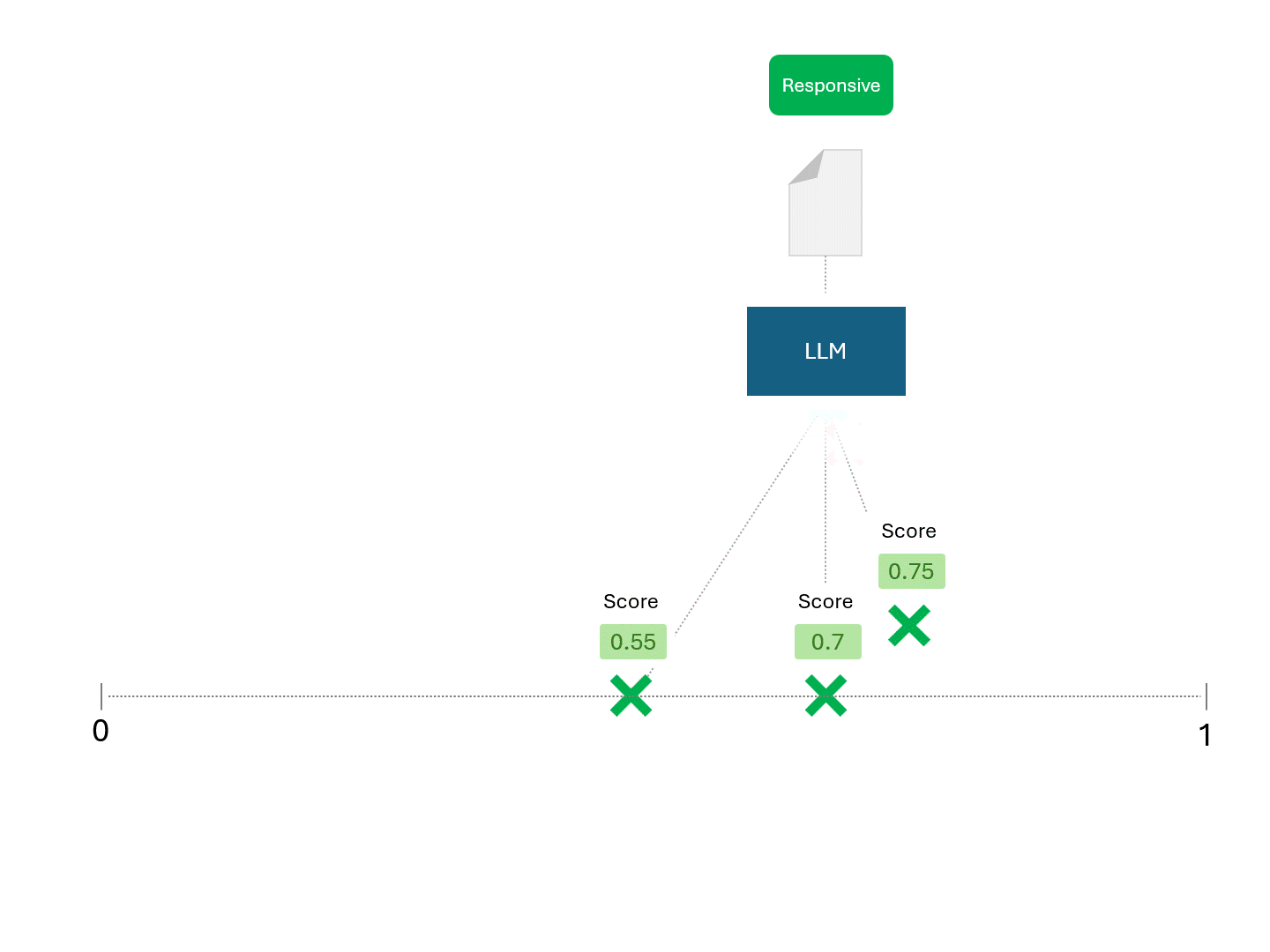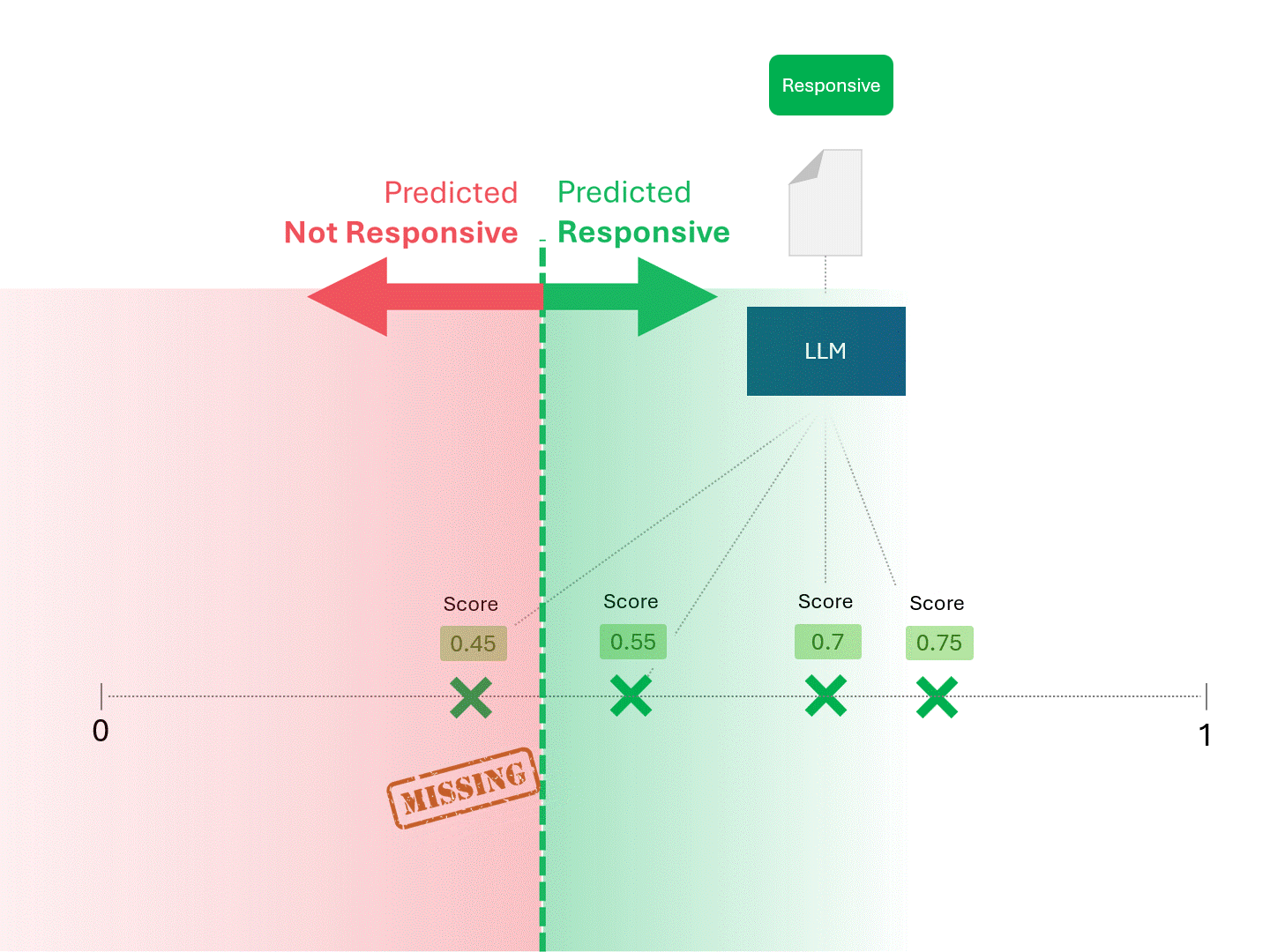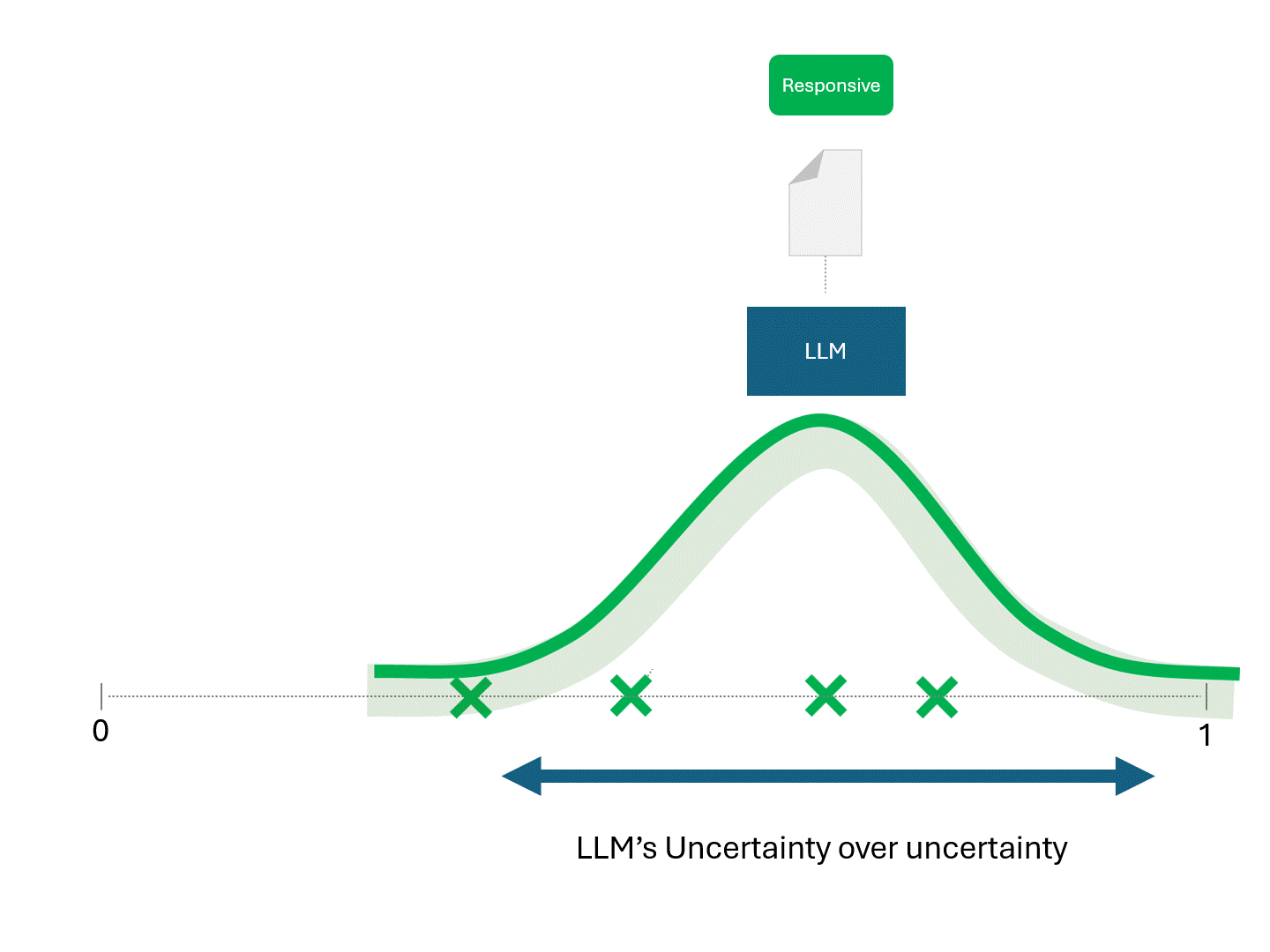
我们通过划定分界线来确定每份文件的响应性,将模型判定为"响应性"和"非响应性"的文档区分开来。这种划分方式必然会产生一定误差,包括误报和漏报两种情况。
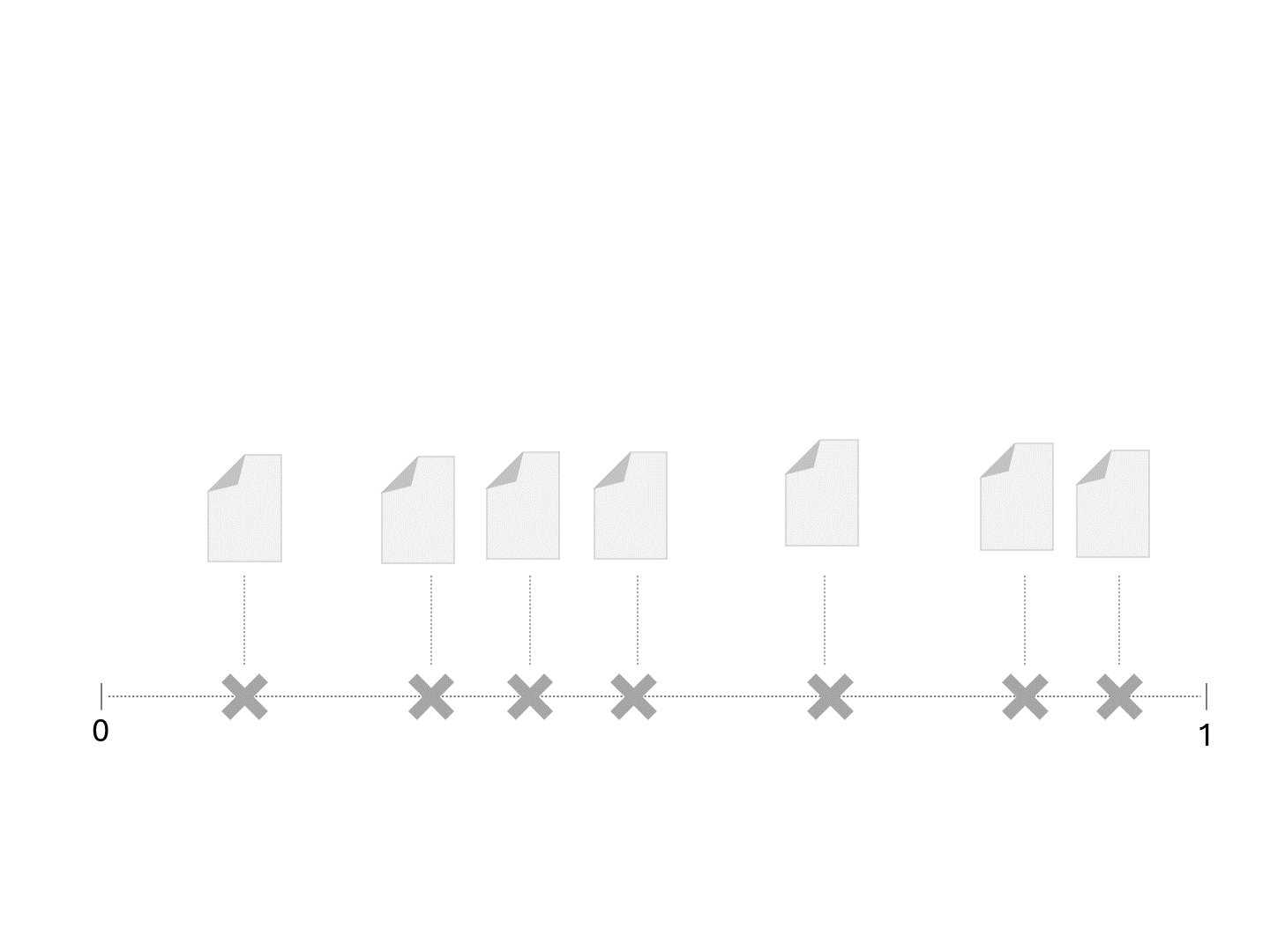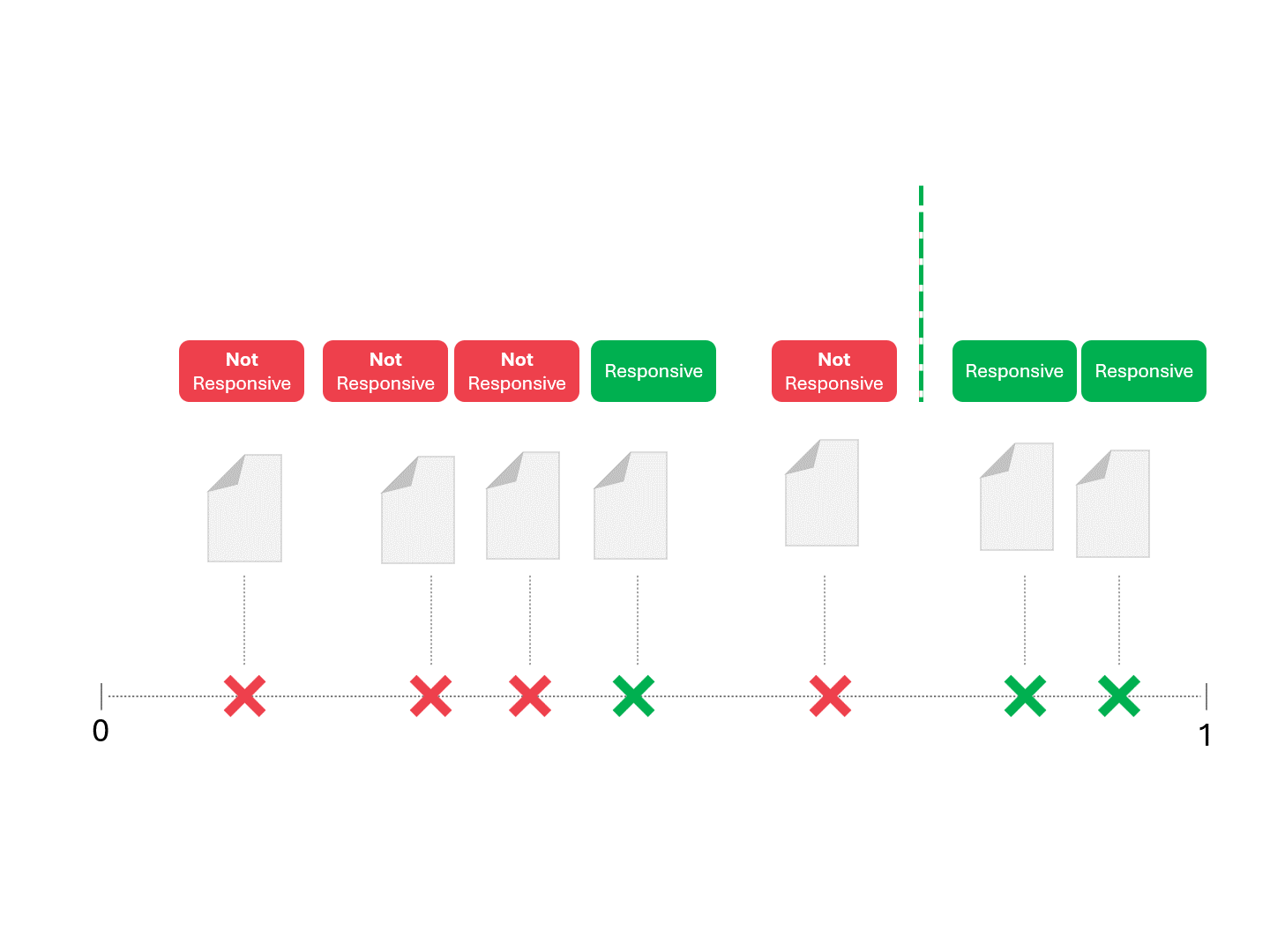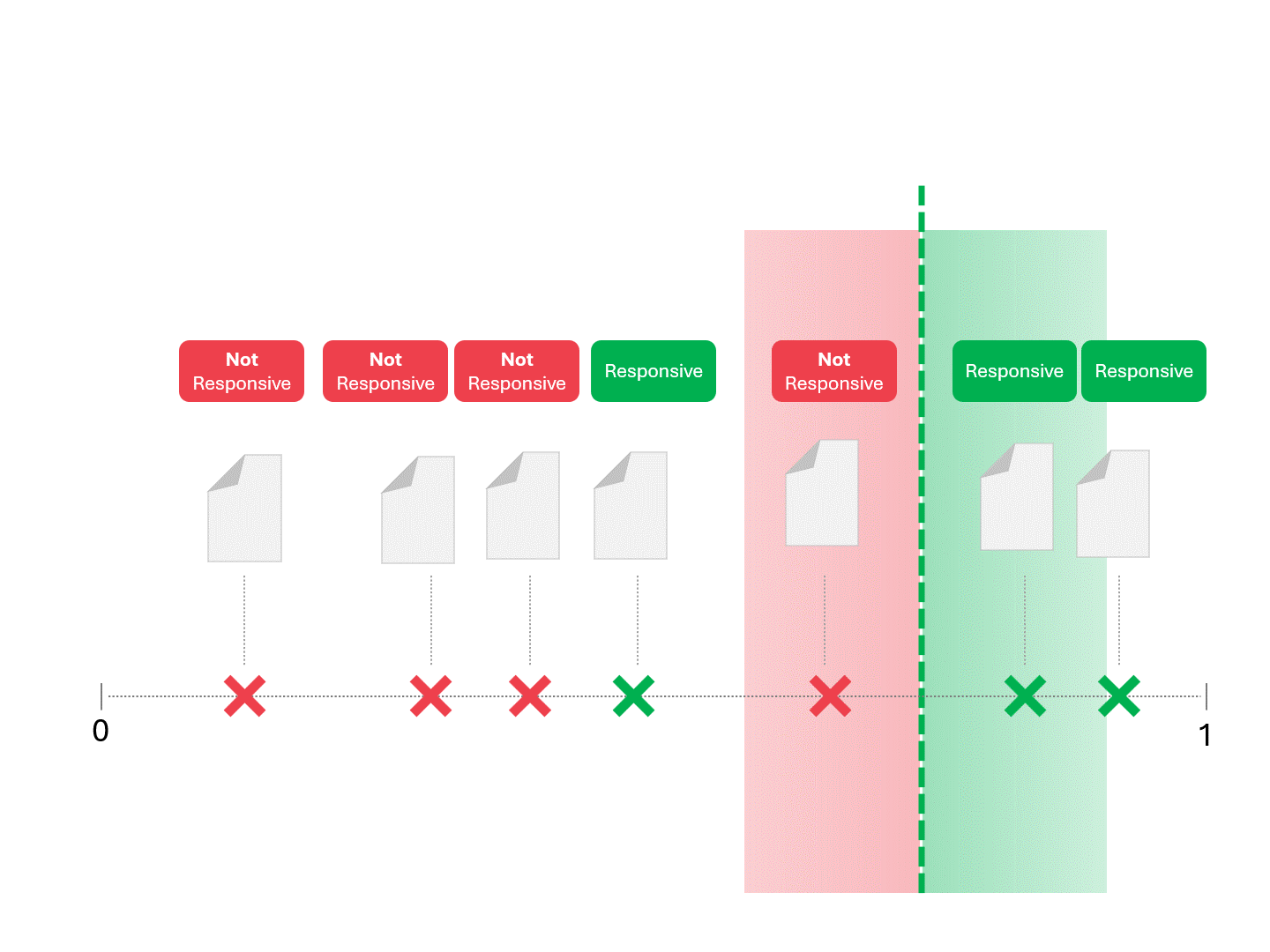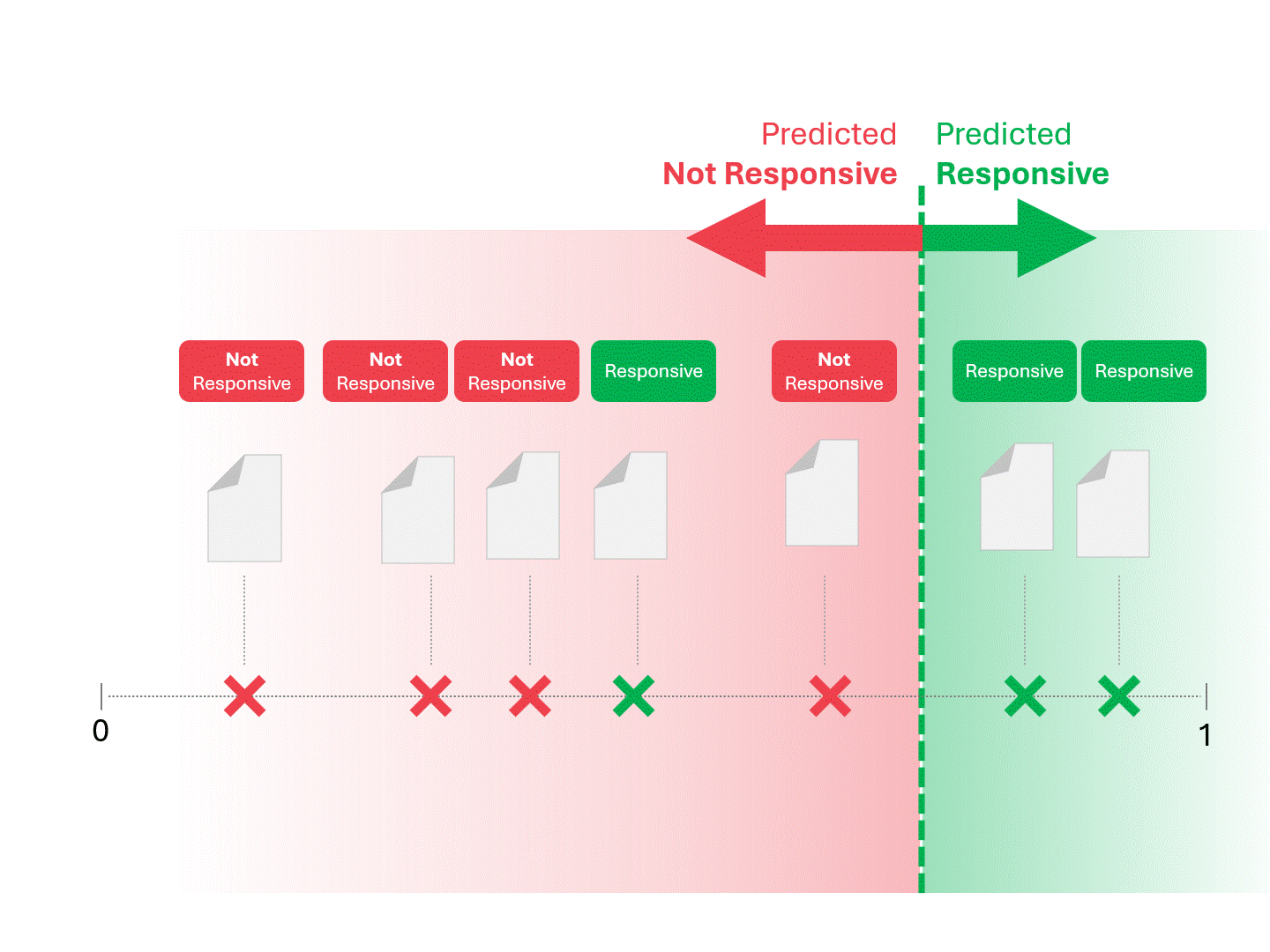
当我们调整评分阈值时,会得到不同的结果和错误率。例如,提高包容性可能导致更多误报,但会减少漏报—这是使用任何机器学习模型都必须接受的权衡。不存在绝对正确的答案,这本质上是一种价值判断。
上述流程自TAR(技术辅助审查)技术诞生以来即成为标准操作规范。只要模型能提供某种形式的评分,即可采用该方法进行预测。
TAR模型与LLM的唯一区别在于:LLM生成的评分具有非确定性特征。在相同数据上重复运行同一模型,会得到不同评分结果,进而导致排序差异。
例如,当反复向TAR模型请求评分时,预期输出应呈现如下特征:
向LLM请求评分时,可能会呈现如下形式:
由于不同评分会导致不同的排名结果,因此每次向LLM请求预测时,您也会得到不同的性能指标,例如召回率和精确率。
解决方案是什么?
我们之前提到,提高模型预测一致性的唯一方法是对预测结果或评分进行平均处理—例如,对同一份文档反复向LLM索取评分,然后对结果取平均值。随着查询次数的增加,这个平均值会逐渐收敛于真实的预测评分,并趋于稳定,从而表现得像传统模型那样接近确定性。
但这种方法存在一个明显问题:对LLM进行多次重复查询在实际操作中并不可行,特别是像GPT-4这样的模型,其使用成本往往高得令人望而却步。
结论是什么?
让我们看看当直接采用LLM输出的置信度时会产生什么情况。
为证明这种结论,我们将确定性模型的精确率-召回率曲线与预测结果存在干扰的模型(如LLM)进行对比分析。
为模拟这一过程,我们首先构建一个假设的评分数据集,然后向其中添加一定程度的随机干扰。最后,我们将对比分析添加干扰前后的精确率-召回率曲线变化。
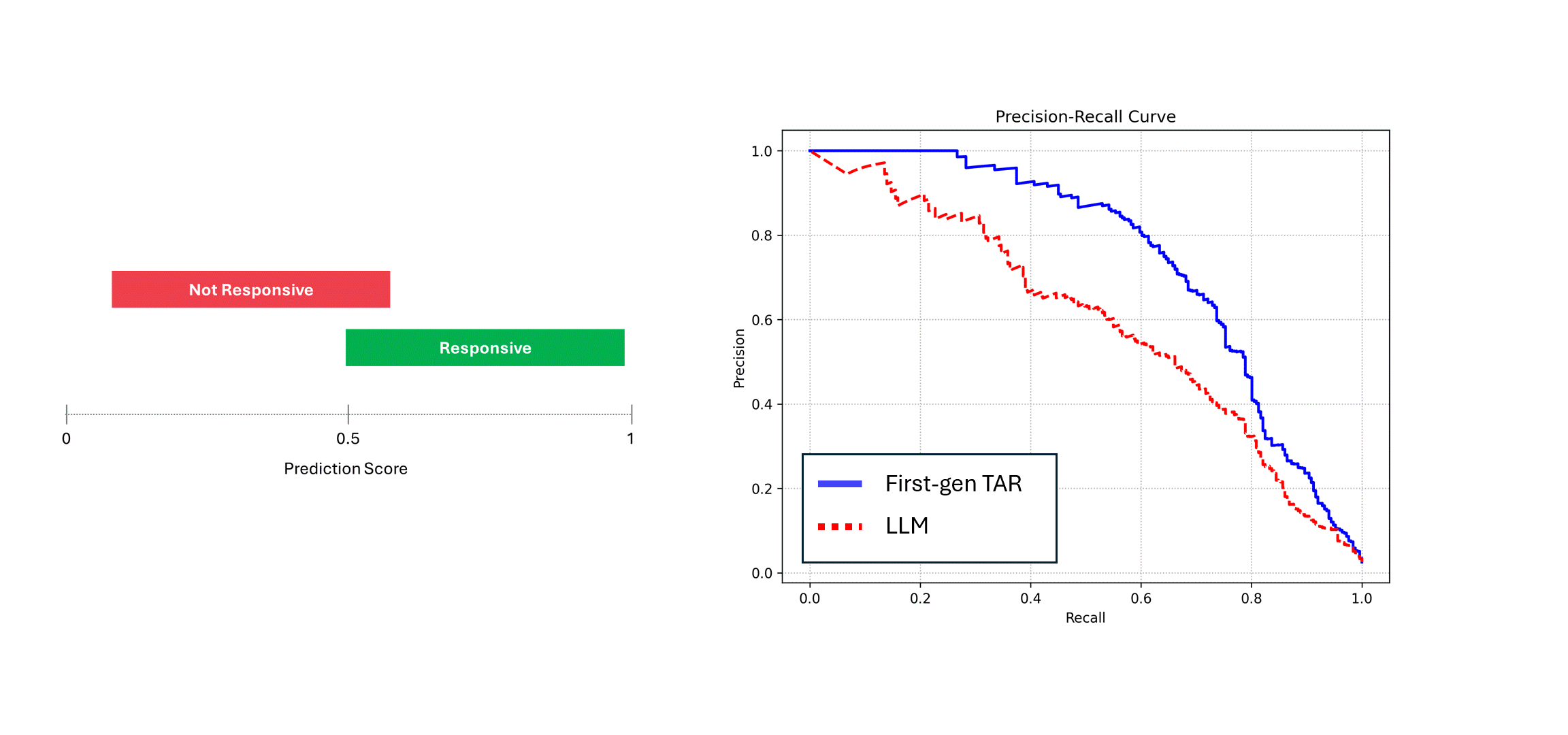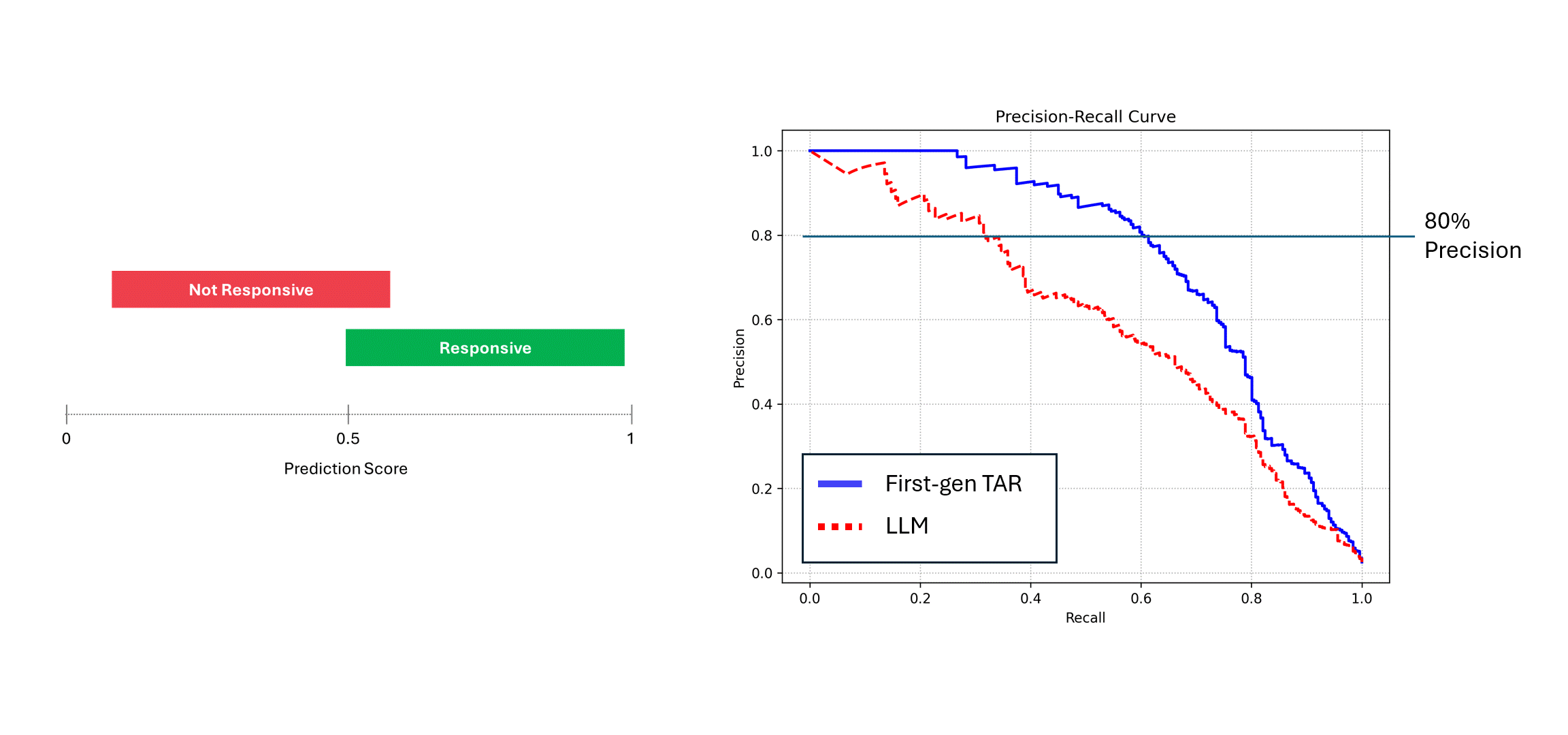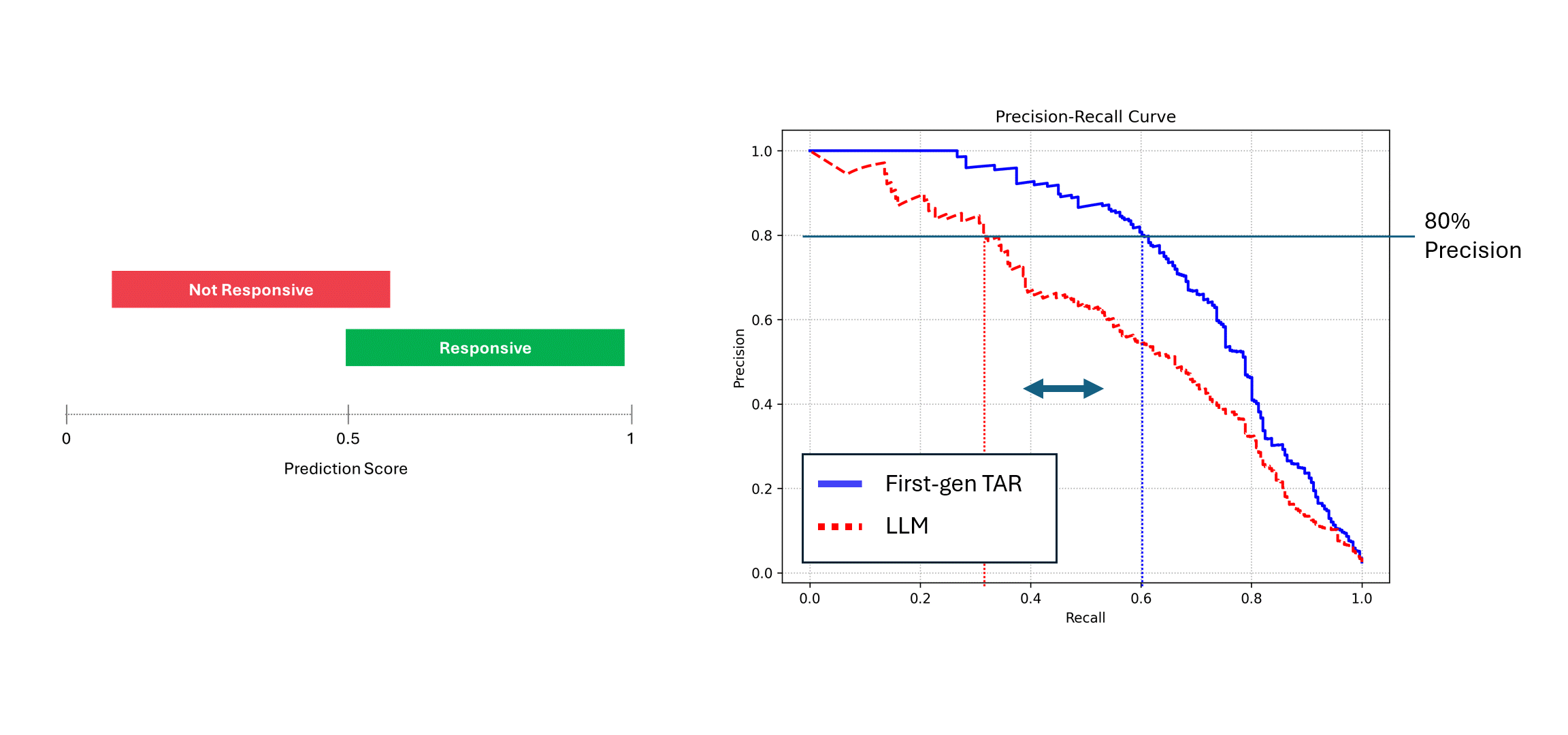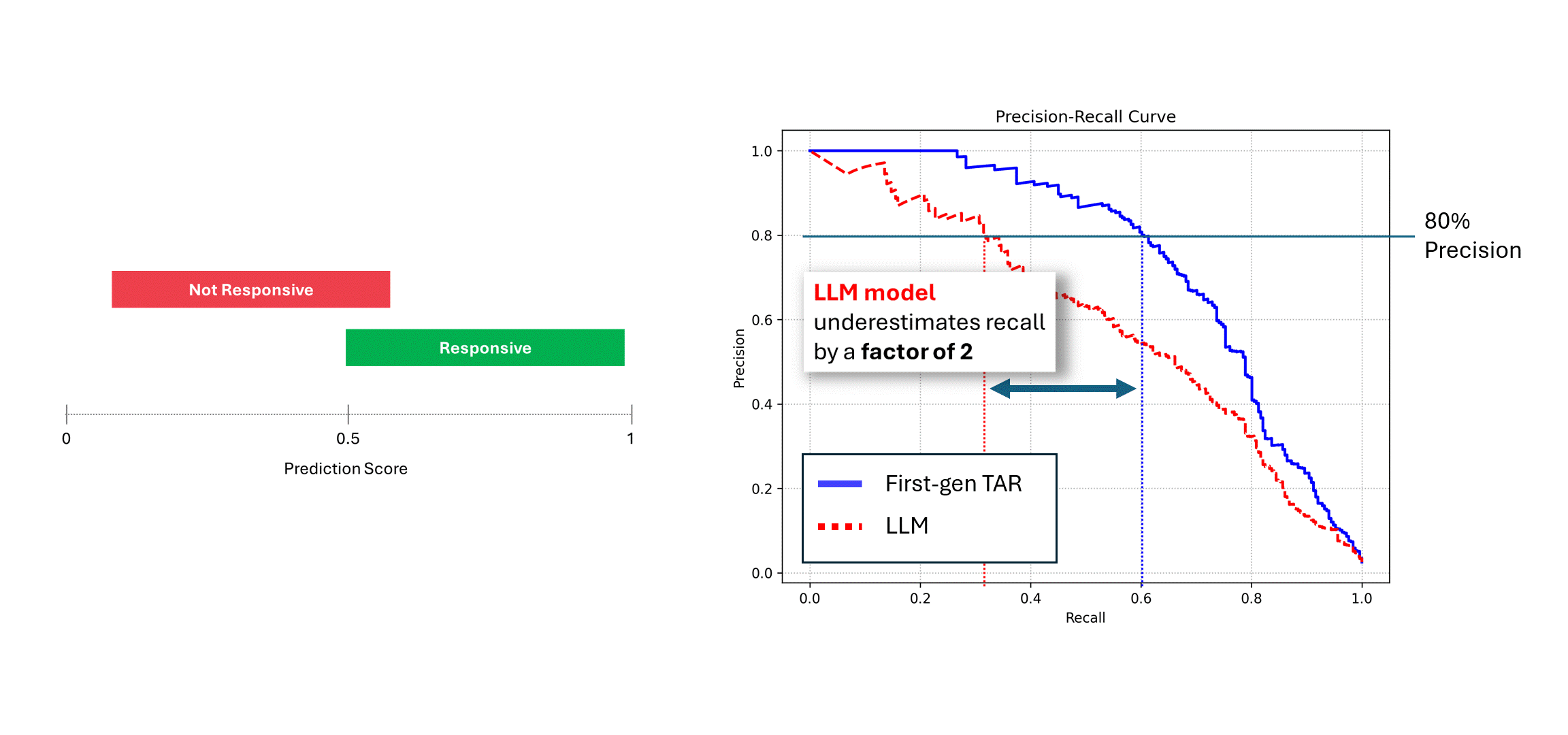
当存在干扰的模型(例如LLM)对相同数据进行多次运行时,通过对其评分取平均后,其精确率和召回率会趋近于确定性模型(即蓝色曲线)的性能水平。然而,当仅依赖单次预测结果(红色曲线)时,模型性能会显著下降,始终低估模型的真实能力。在上述示例中,报告的性能可能仅为实际水平的一半。
实际应用分析
在实际应用中,当您查看LLM的精确率-召回率曲线(即上图中的红色曲线)时,您只会看到不充分的性能表现,却无法确定原因。直觉反应可能是通过调整提示词或添加示例来提升模型性能。
但在此情况下—所有这些努力都将徒劳。性能差距并非因为模型本身不够优秀,而是由于其非确定性特性低估了模型的真实能力。要弥合这一性能差距,唯一的方法是要求LLM多次提供评分并对预测结果取平均值。
考虑到出于成本和时间因素,您不可能对每份文档运行模型10次,那么是否存在确保模型性能报告准确性的解决方案?答案是肯定的—我们将在下一篇文章中详细探讨。敬请关注!

Igor Labutov, Epiq AI Labs 副总裁
Igor Labutov 现任Epiq公司副总裁,并共同领导Epiq AI Labs。他是一位计算机科学家,专注于开发能够从人类自然监督(如自然语言)中学习的机器学习算法,在人工智能与机器学习领域拥有超过10年的研究经验。Labutov博士毕业于康奈尔大学,并在卡内基梅隆大学从事博士后研究,期间他在人本人工智能与机器学习的交叉领域开展了开创性研究。加入Epiq之前,Labutov联合创立了LAER AI,将其研究成果应用于为法律行业开发变革性技术。
本文的内容仅旨在传达一般信息,不提供法律建议或意见。