


Building Trust in AI Discovery With Streamlined Sampling
- eDiscovery
- 3 mins
In eDiscovery, ensuring the accuracy and defensibility of document review is paramount, especially when productions are shared with opposing parties or regulators. Epiq AI™ for Review brings statistical rigor to this process by enabling validation through standard evaluation metrics: recall, precision, and elusion.
- Recall measures how many relevant documents were correctly identified out of all possible relevant documents.
- Precision assesses how many documents identified as relevant were actually relevant.
- Elusion estimates how many relevant documents may exist in the set presumed irrelevant.
These metrics, based on random sampling, enable a transparent and statistically sound way to evaluate the effectiveness of document review supported by AI.
When to Validate
Validation is most critical when producing documents to external parties. Whether it’s a regulatory body or opposing counsel, demonstrating the reliability of your review process is essential. For internal investigations or incoming productions, validation is optional but still beneficial. The ability to estimate recall, precision, elusion, and richness with confidence intervals ensures defensibility and transparency.
What to Measure
Epiq AI™ for Review goes beyond simply identifying Responsive or Not Responsive classifications. It also supports issue tagging and privilege detection. The system includes built-in recall and precision tradeoff metrics for each issue tag, leveraging k-fold cross-validation and review codes.
However, this is not the same as a control set and should only be used to guide workflow considerations.
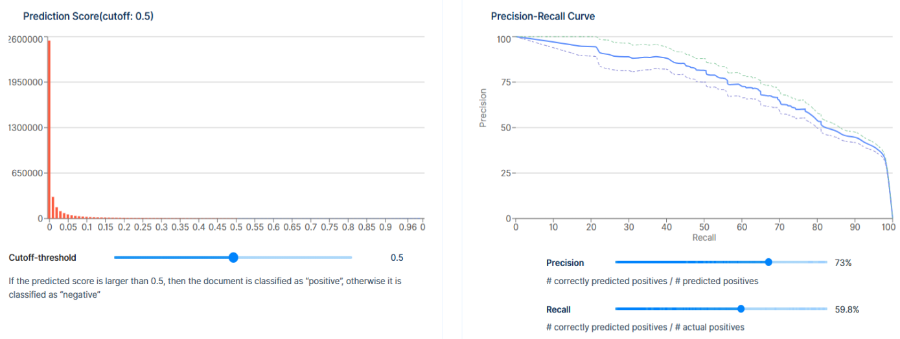
Validating the overall Responsive and Not Responsive categories is generally recommended practice. The built-in guidance for each tag can help determine appropriate cutoff scores, but to determine the effectiveness of the overall production, Epiq recommends validating the overall Responsive and Not Responsive determinations.
Control Set: The Foundation for Validation
A control set of 500 documents often provides reasonable coverage. For lower richness data sets or for higher confidence levels, larger control sets can be selected.

The control set is randomly selected from the collection, and the coding is not used to train the model. The control set documents are set aside from the training and only used for validation.
Prevalence Sampling: Early Insights
At the outset of a review, a small random sample, known as a prevalence sample, is used to estimate the proportion of Responsive documents in the dataset. This can be useful in determining the kinds of documents and issues that might arise from the collection, as well as planning for downstream activities. For example, if a second-level review is planned for documents identified as Responsive, a prevalence sample provides an early indication of how many Responsive documents will be found. It’s a strategic step that informs resource allocation and timeline expectations.
Elusion Sample: Final Assurance
At the end of the review workflow, a critical step is a random sample of documents identified as Not Responsive and not being produced. An elusion sample is a random sample that identifies the percentage of overlooked relevant documents; it is a powerful tool in internal investigations and incoming productions where the team wants assurance that nothing important is missed. Elusion samples also allow one to estimate recall when all predicted relevant documents have been reviewed.
Ease of Use in Epiq AI™ for Review Interface
Setting up and running sample sets with Epiq AI™ for Review is designed for simplicity. Users initiate control, prevalence, and elusion samples directly through guided workflows. Each step includes tooltips and built-in recommendations, enabling legal professionals to configure sampling parameters without needing statistical expertise. This streamlined process helps legal teams validate document sets faster and more confidently.
Conclusion
These established and well-understood metrics to validate discovery results are also recommended and integrated into the Epiq AI™ for Review process. Identifying the precision, recall, and elusion confidence intervals for relevance gives all parties assurance of the effectiveness of the method and the result.
While Epiq AI™ for Review offers advanced capabilities, the emphasis remains on empowering legal professionals — not replacing them. By combining human expertise with AI insights, legal departments and law firms can streamline their document review processes and meet the highest standards of accuracy and accountability.

Jon Lavinder, Senior Director of Product Management, Epiq
Responsible for AI tools, Technology Assisted Review (TAR), chat and collaborative data, and Early Case Assessment (ECA) technologies, Jon works closely with law firms and corporate legal professionals to build the tools and services for the next generation of legal discovery and information governance. Mr. Lavinder is a frequent speaker at eDiscovery conferences on the use of AI and the industry’s future.
The contents of this article are intended to convey general information only and not to provide legal advice or opinions.