

Angle

Warum Confidence Scoring mit LLMs gefährlich ist
Wenn es um Vertrauensbewertungen von LLMs geht, ist die Bewertung von Vorhersagen wesentlich. Das Wichtigste ist nicht die Bewertung selbst, sondern die daraus resultierende Rangfolge.
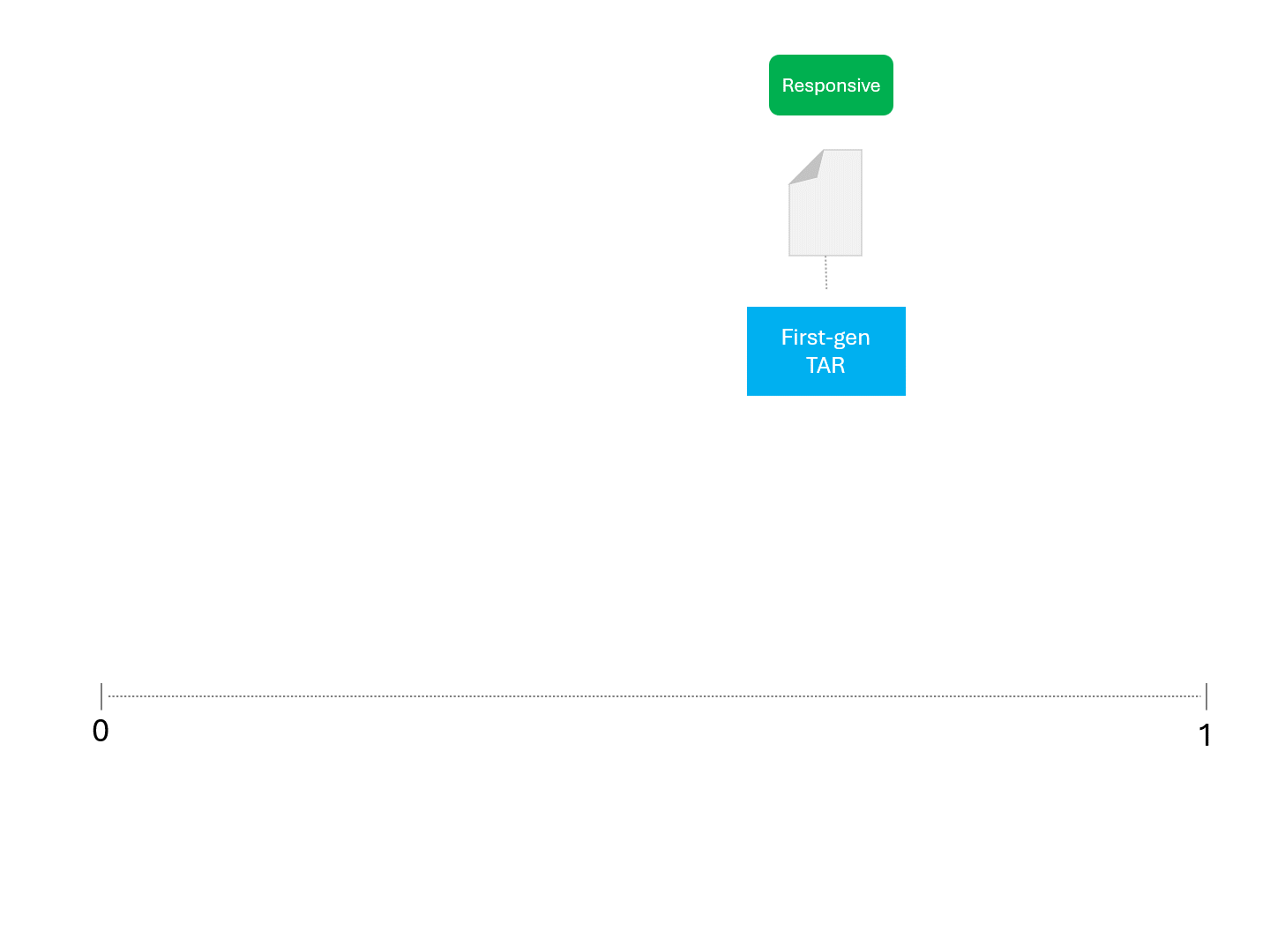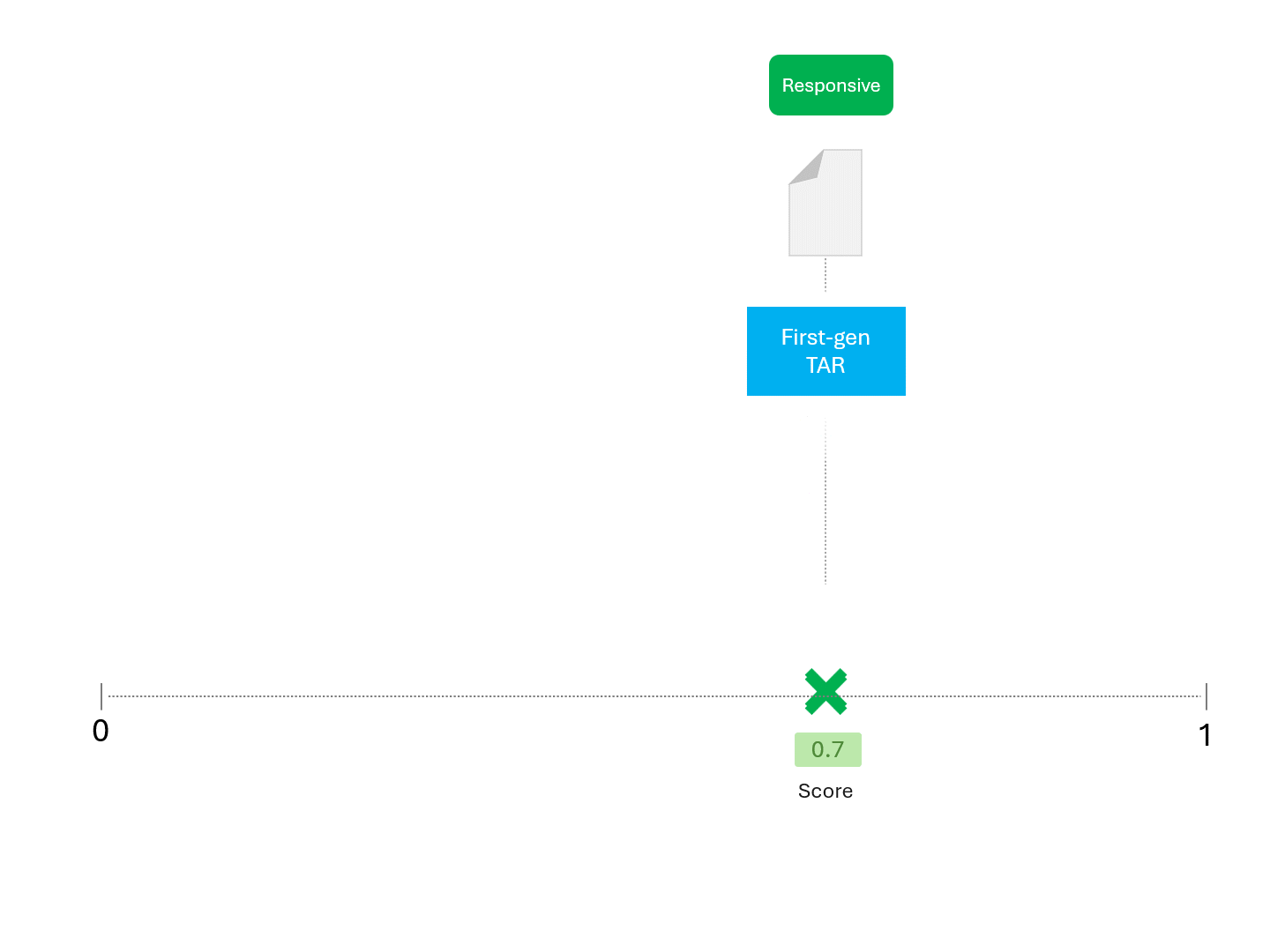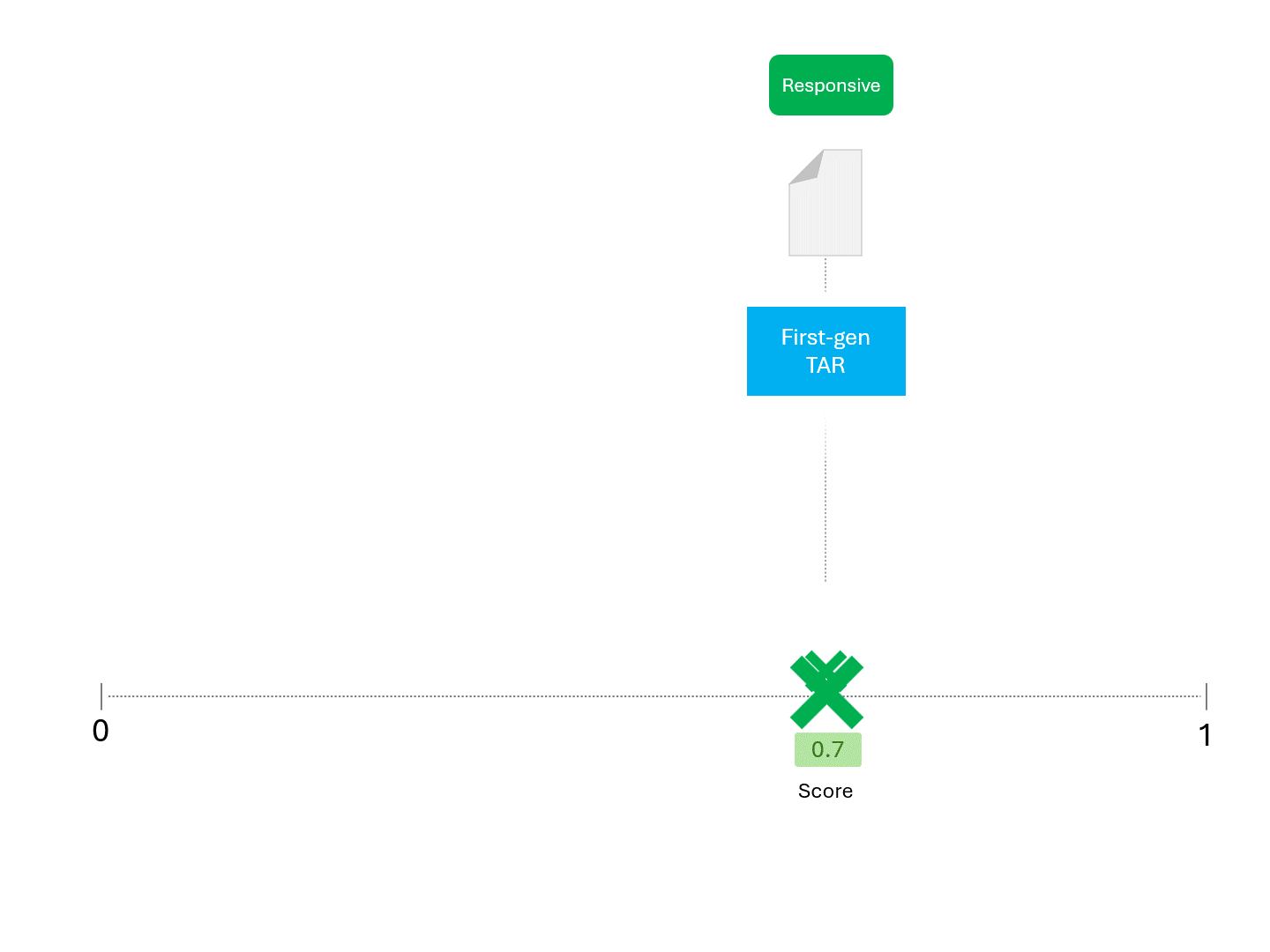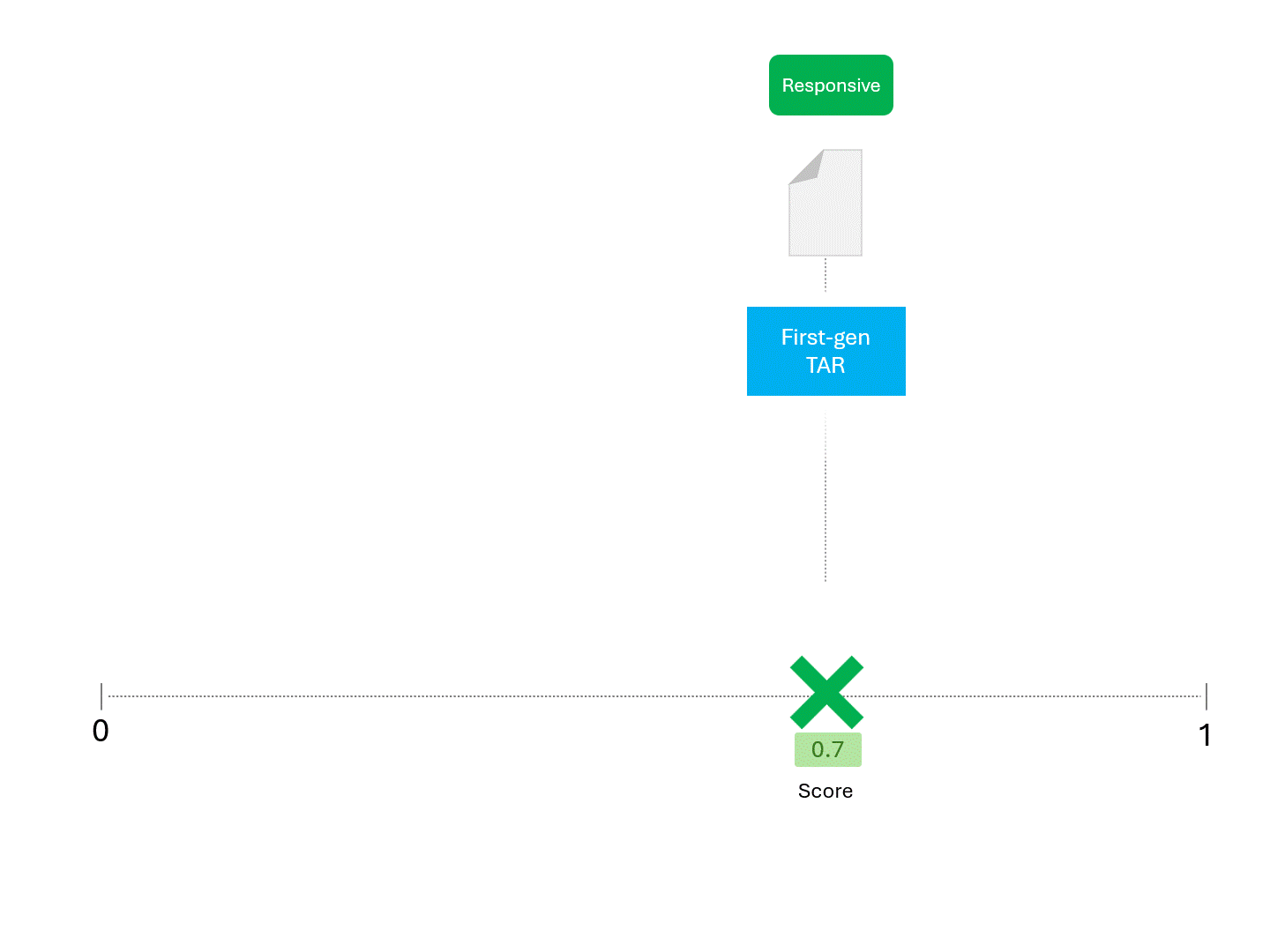
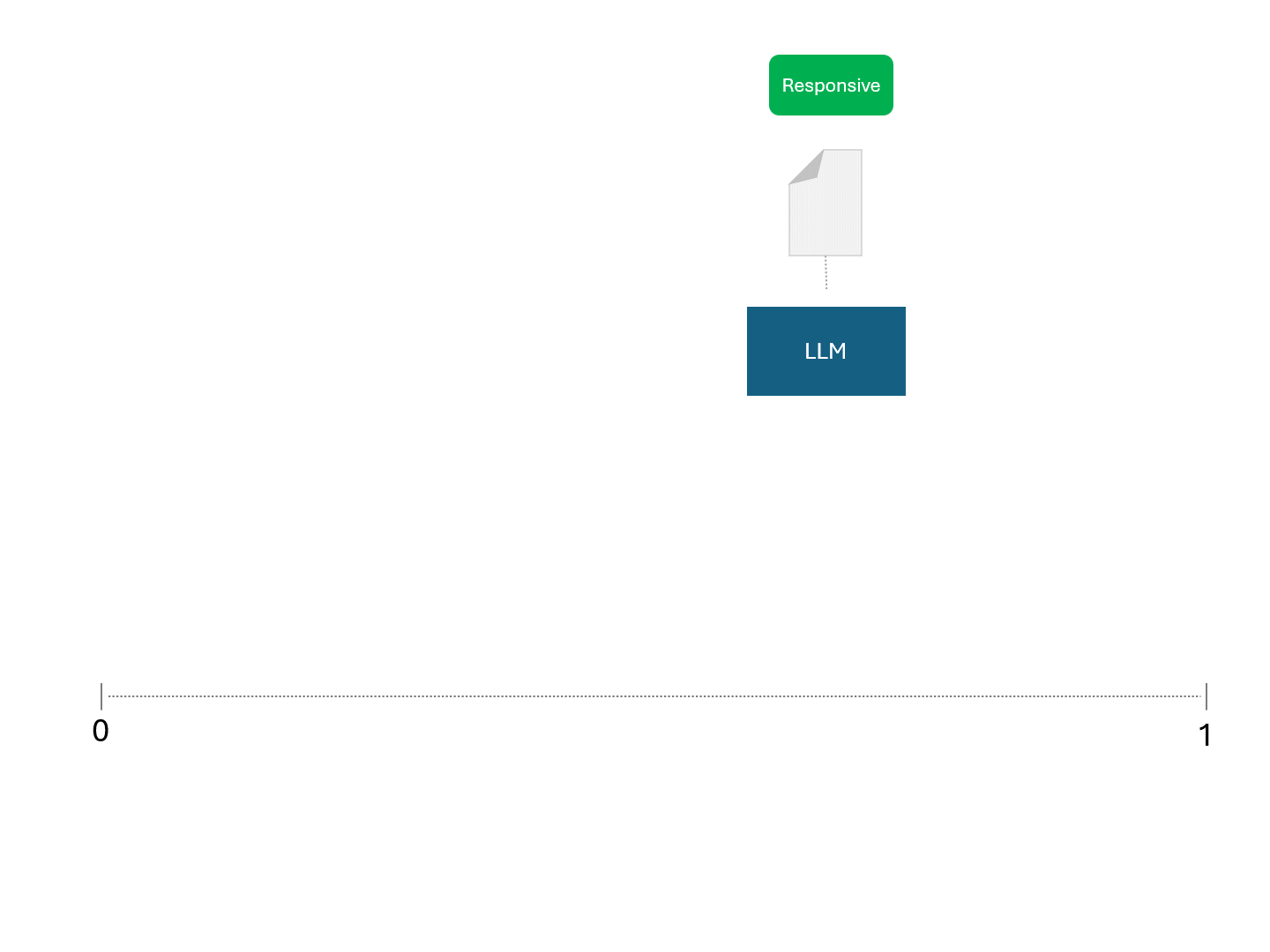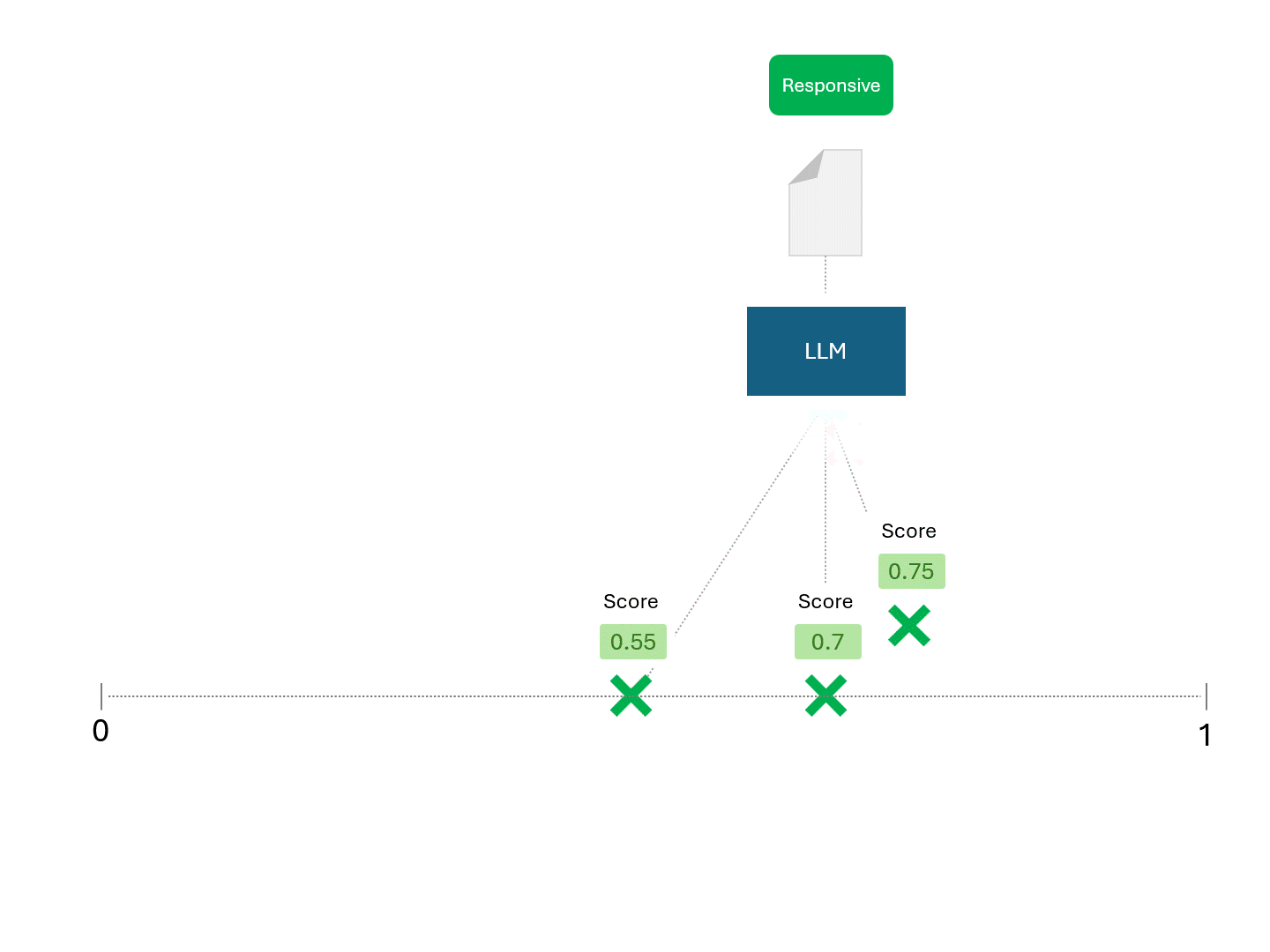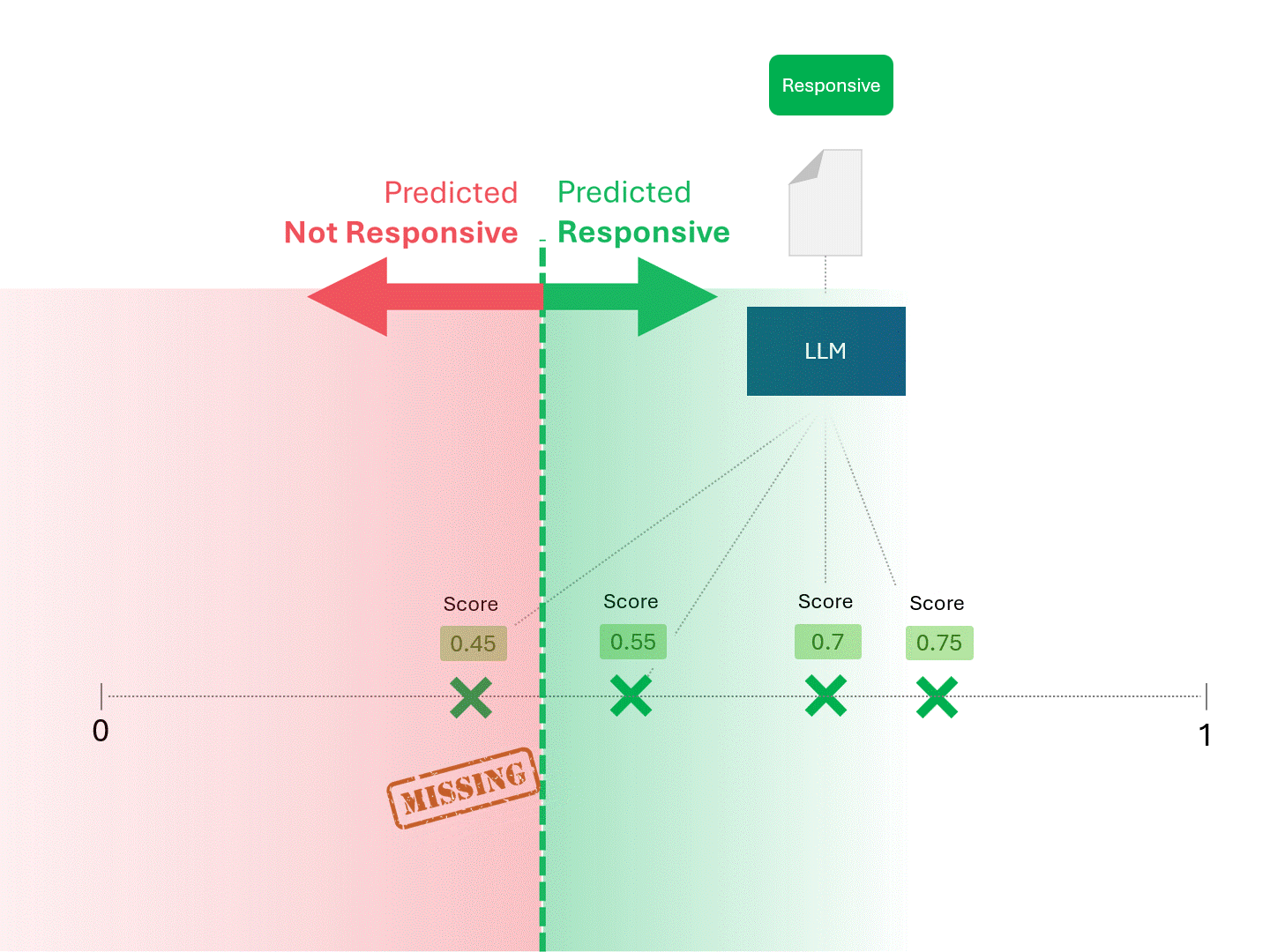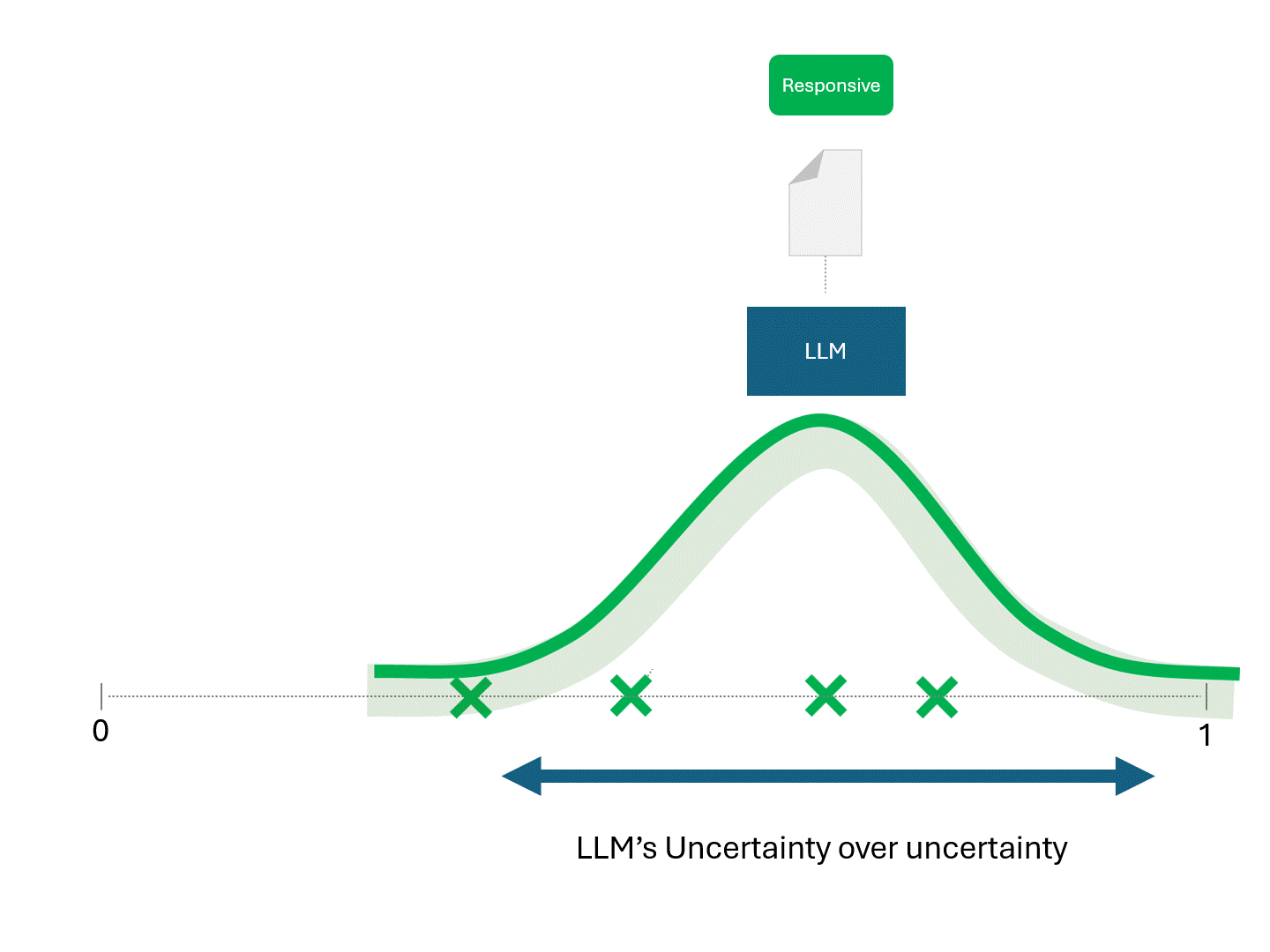
Sobald unser Modell (TAR 1.0, TAR 2.0, CAL oder LLM) eine Punktzahl angibt, ordnen wir die Beispiele ein und ziehen eine Abschneidelinie:

Wir entscheiden über die Reaktionsfähigkeit für jedes Dokument, indem wir eine Linie ziehen, um zu trennen, was das Modell als reaktionsfähig und nicht reaktionsfähig bezeichnen würde. Die sich daraus ergebende Trennung würde gelegentlich Fehler aufweisen, sei es falsch-positive oder falsch-negative.
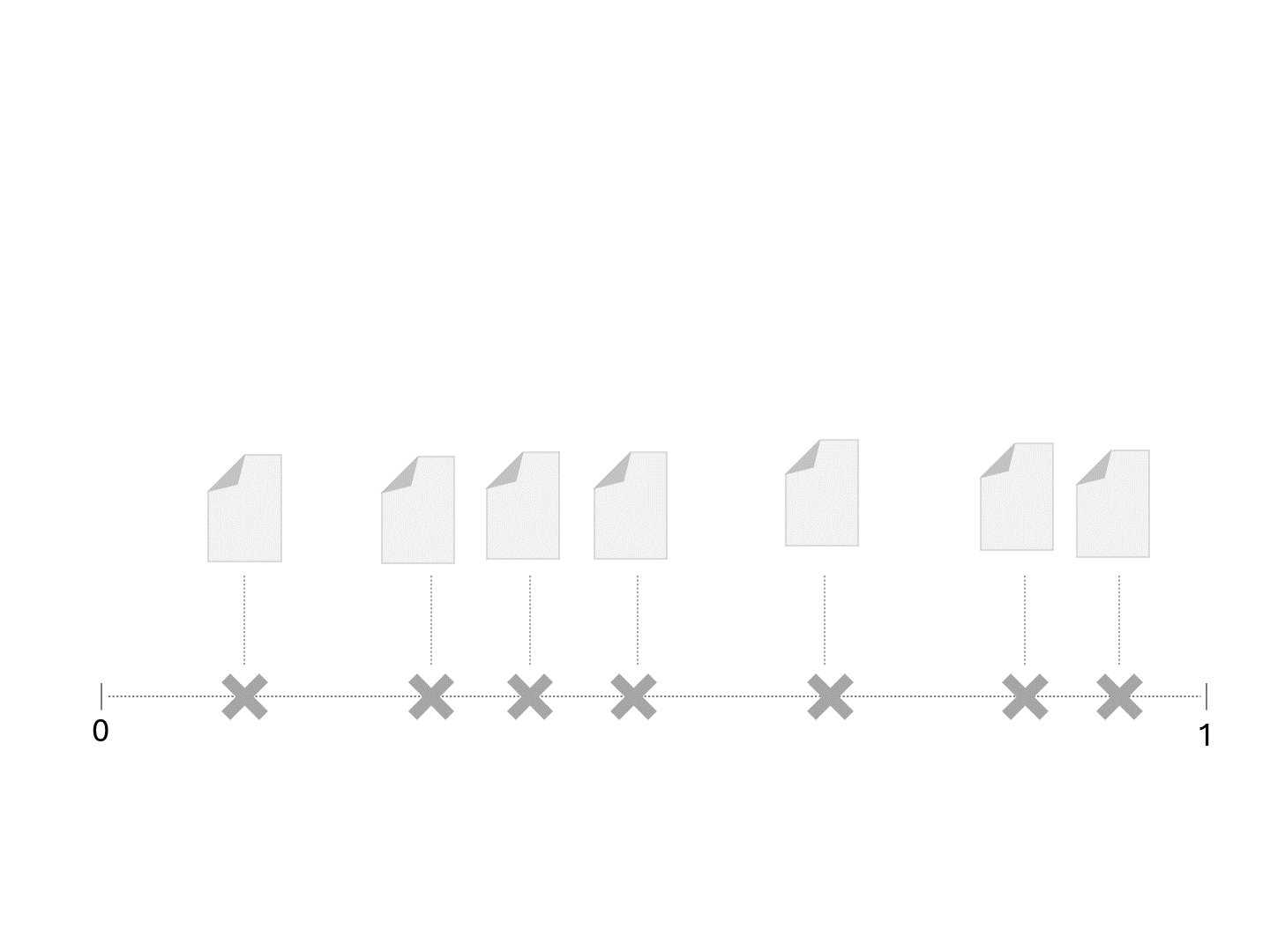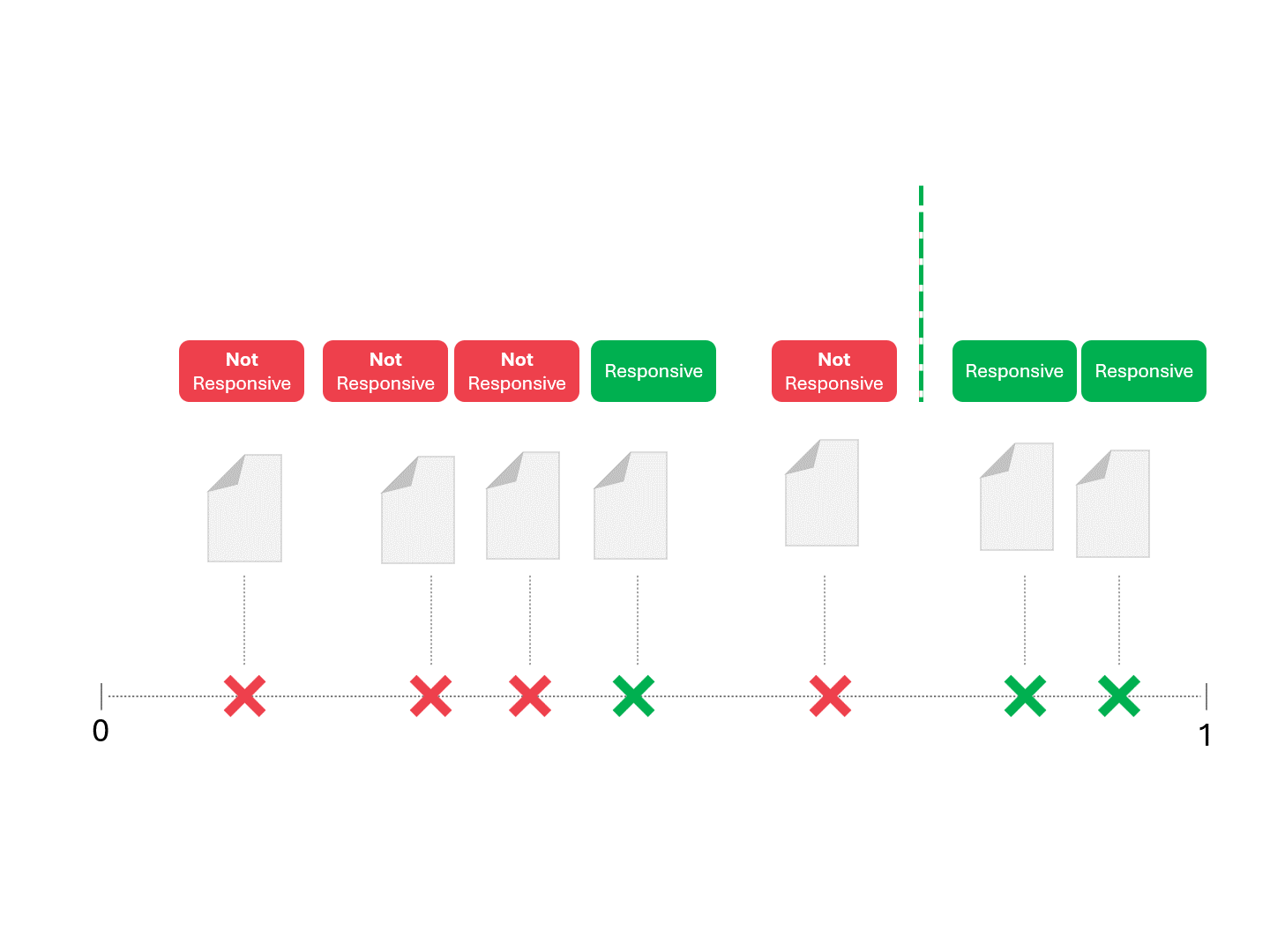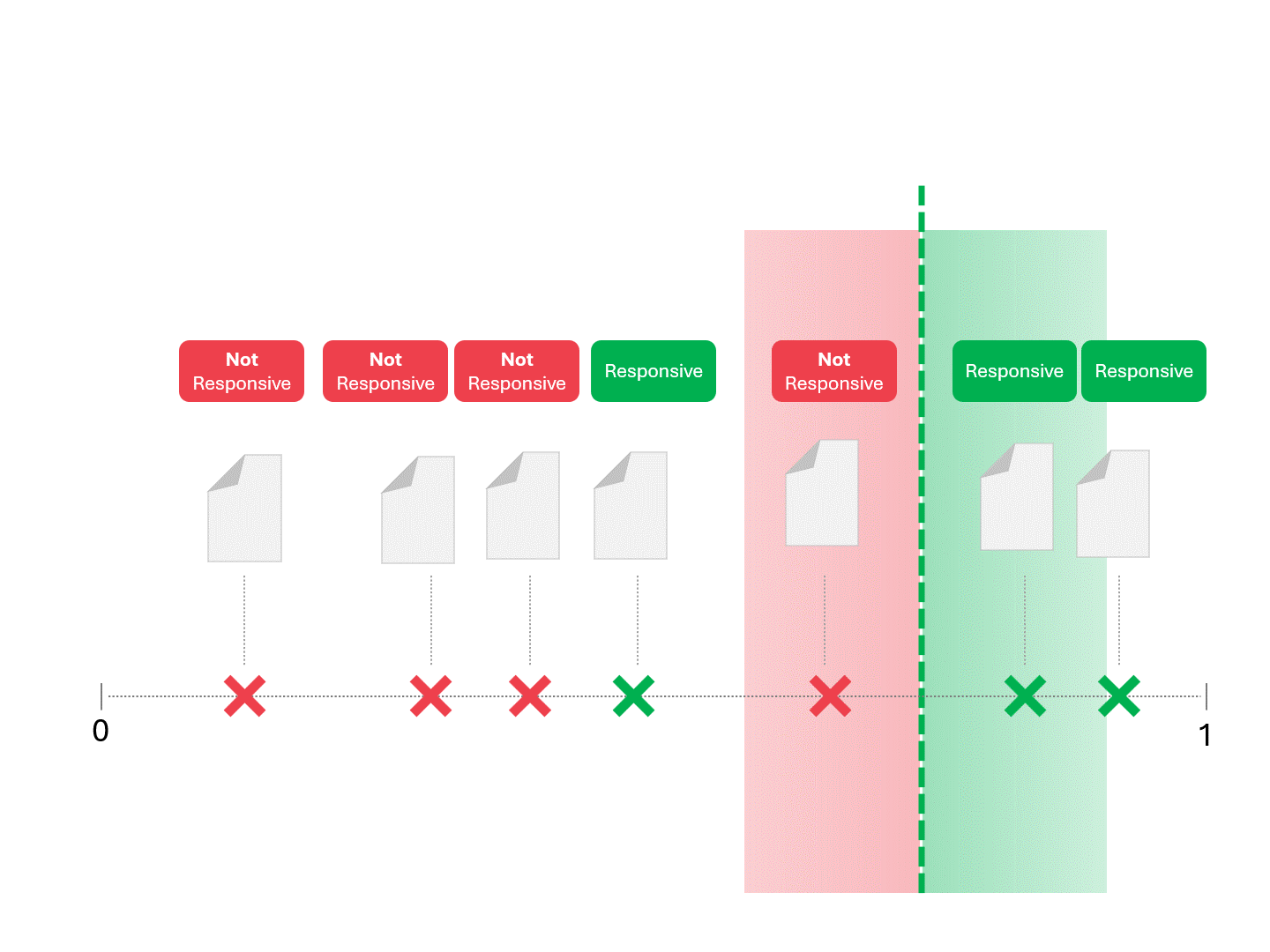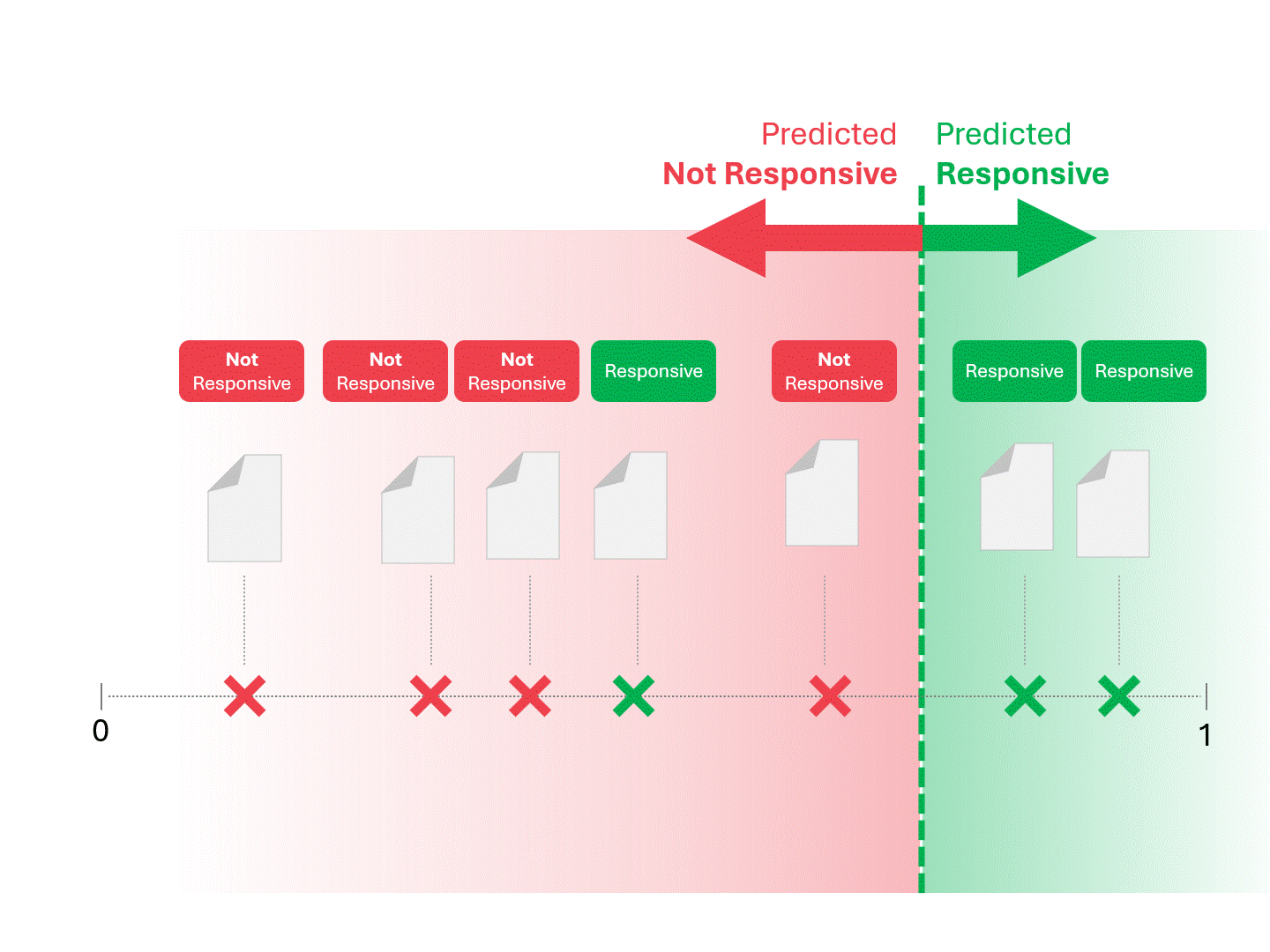
Wenn wir den Schwellenwert für die Bewertung ändern, erhalten wir unterschiedliche Ergebnisse und Fehlerquoten. Beispielsweise kann die Inklusivität zu mehr falsch-positiven Ergebnissen führen, aber zu weniger falsch-negativen, ein Kompromiss, den wir bei der Verwendung eines maschinellen Lernmodells in Kauf nehmen müssen. Es gibt keine richtige Antwort, sondern es handelt sich um ein Werturteil.
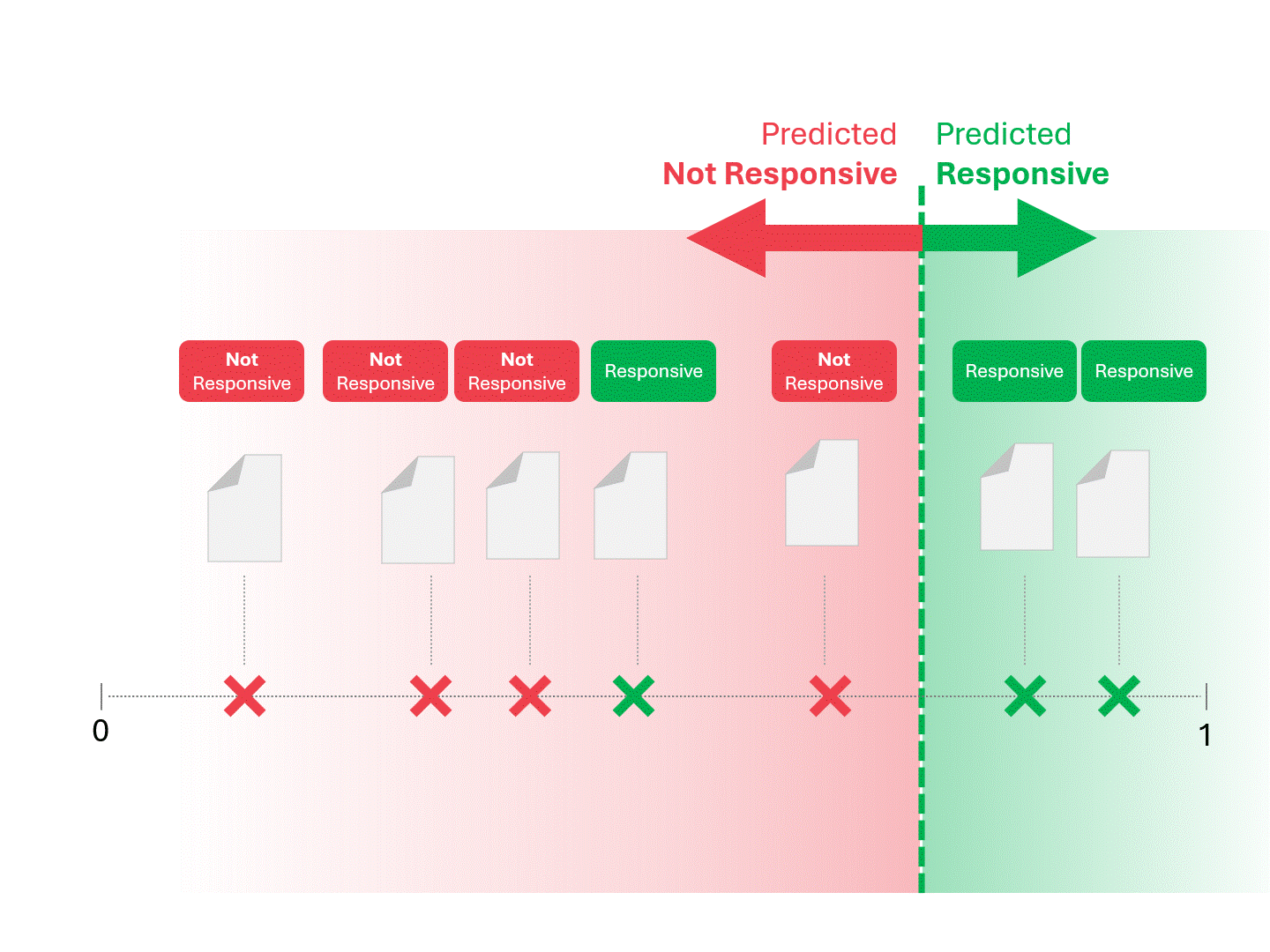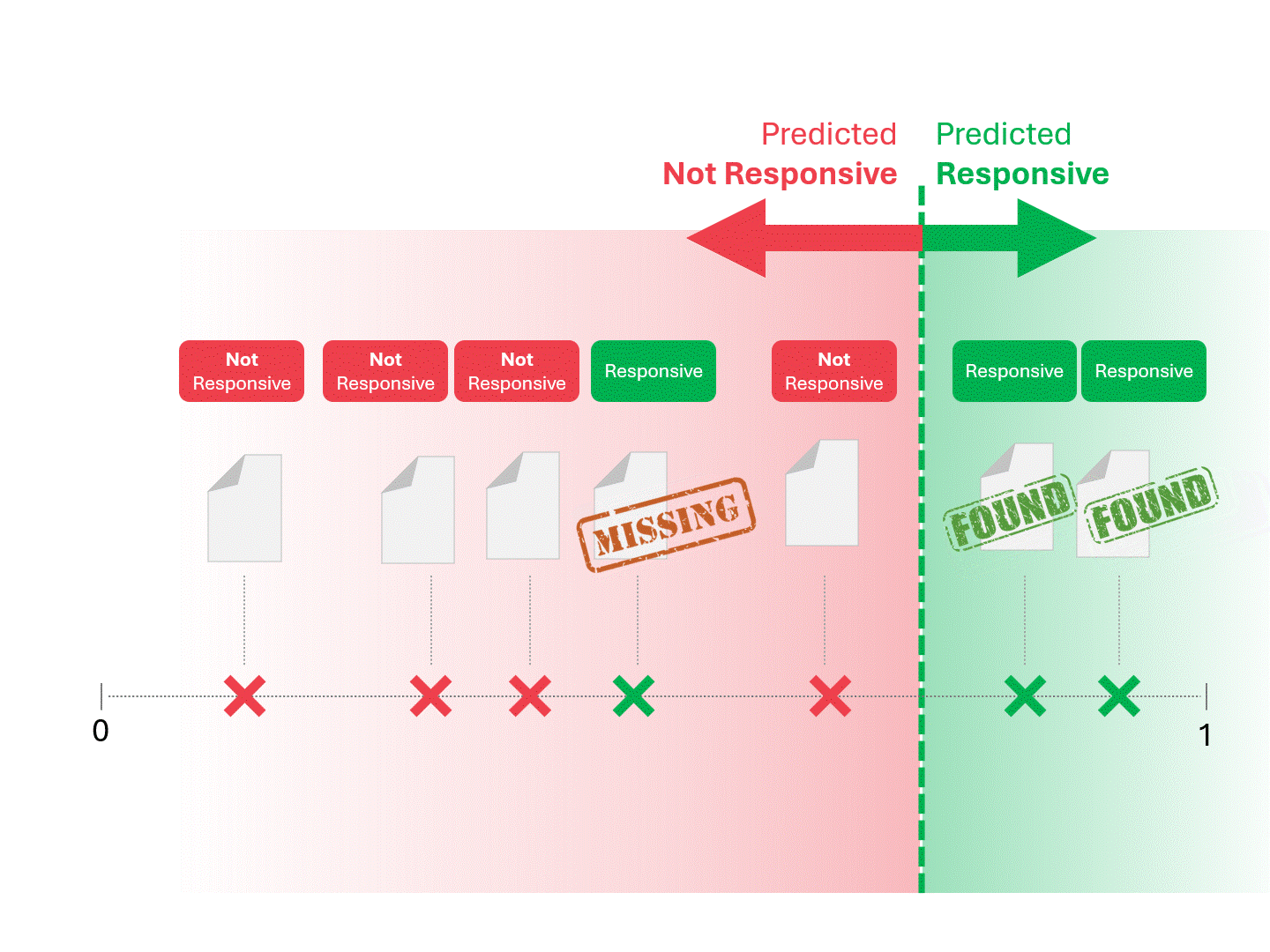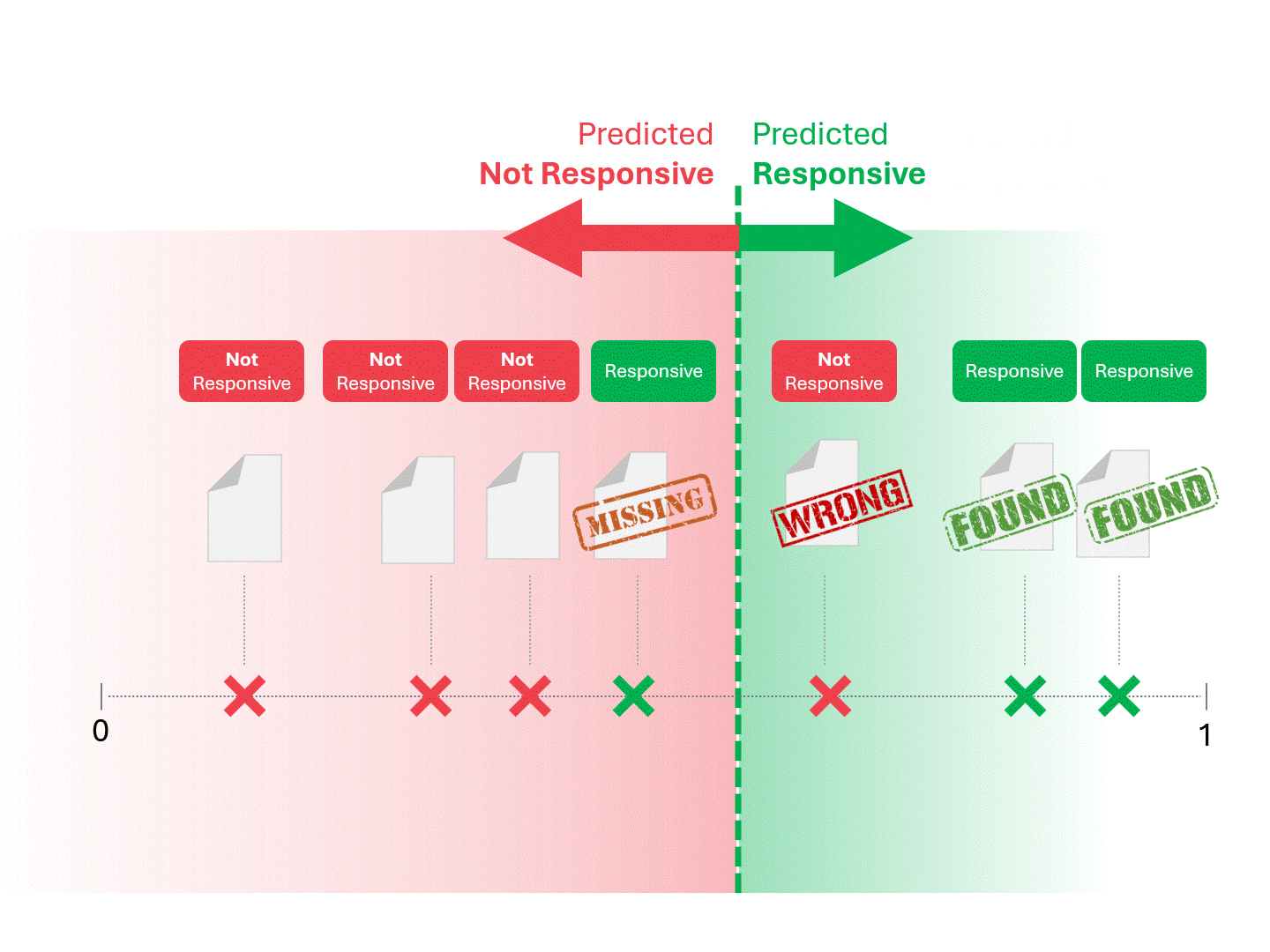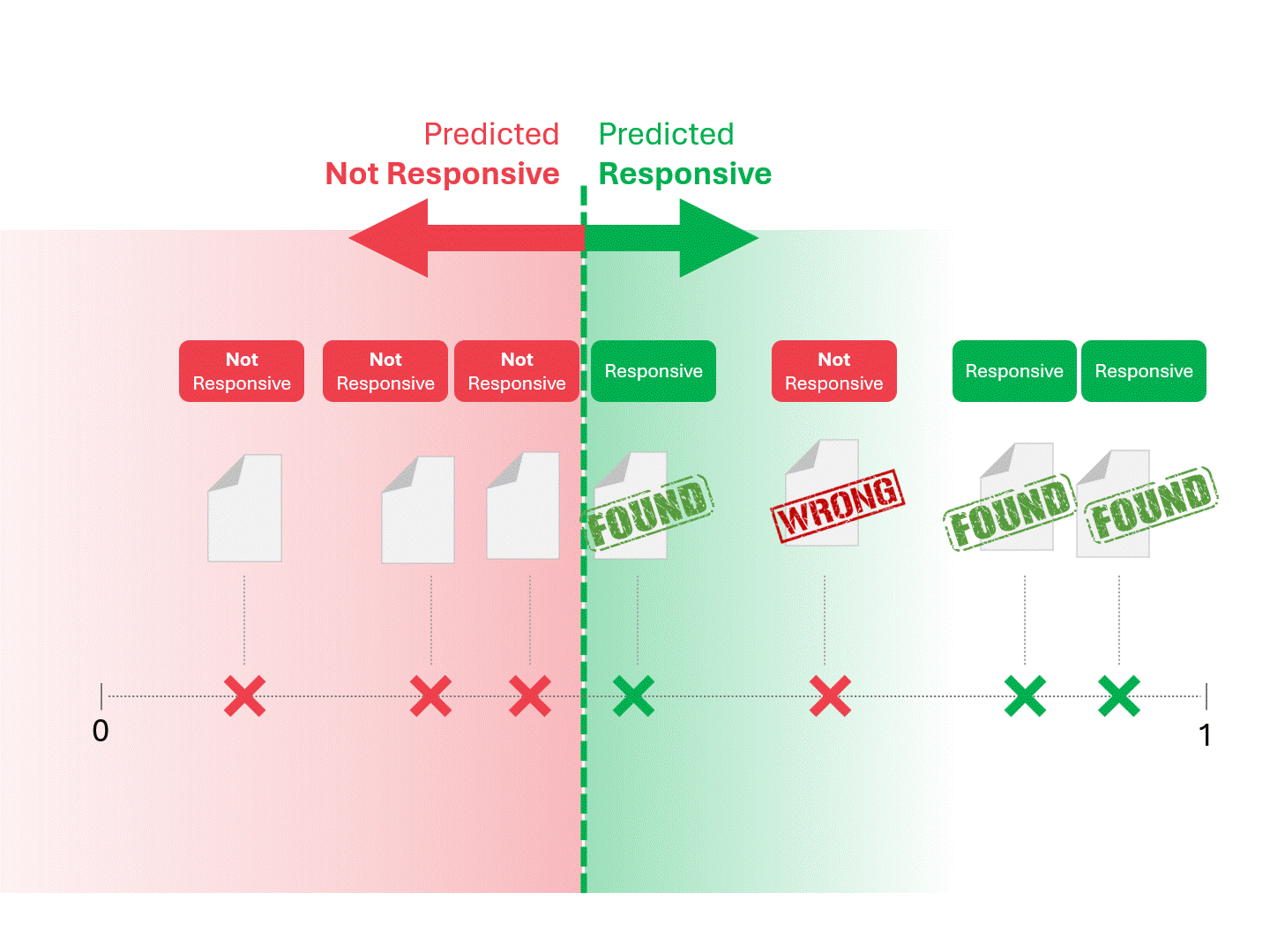
Das oben beschriebene Verfahren ist schon so lange Standard, wie es TAR gibt. Solange ein Modell uns eine wie auch immer geartete Punktzahl liefert, kann die oben beschriebene Methode verwendet werden, um Vorhersagen zu treffen.
Der einzige Unterschied zwischen TAR-Modellen und LLMs besteht darin, dass die mit einem LLM erzielten Ergebnisse nicht deterministisch sind. Die wiederholte Anwendung desselben Modells auf dieselben exakten Daten würde zu unterschiedlichen Ergebnissen und damit zu einer anderen Rangfolge führen.
Wenn wir zum Beispiel ein TAR-Modell wiederholt nach einer Punktzahl fragen, würden wir so etwas wie das Folgende erwarten:
Einen LLM um eine Bewertung zu bitten, würde dagegen etwa so aussehen:
Da unterschiedliche Ergebnisse zu unterschiedlichen Rankings führen würden, würden Sie jedes Mal, wenn Sie einen LLM um Prognosen bitten, auch unterschiedliche Leistungskennzahlen wie Recall und Precision erwarten.
Was ist die Lösung?
Wir haben bereits erwähnt, dass die einzige Möglichkeit, die Konsistenz der Vorhersagen eines Modells zu erhöhen, darin besteht, entweder die Vorhersagen selbst oder die Punktzahlen zu mitteln, z. B. indem das LLM wiederholt nach der Punktzahl für dasselbe Dokument gefragt wird und dann die Ergebnisse gemittelt werden. Bei einer ausreichenden Anzahl von Abfragen würde der Mittelwert gegen den wahren Vorhersagewert konvergieren und sich stabilisieren, so dass er näher an der Deterministik als bei herkömmlichen Modellen liegt.
Das Problem bei dieser Methode ist, dass es unpraktisch ist, eine Abfrage an ein LLM viele Male zu wiederholen, insbesondere bei etwas wie GPT-4, wo die Kosten oft unerschwinglich sind.
Was sind die Konsequenzen?
Schauen wir uns an, was passiert, wenn wir uns einfach auf die Konfidenzausgabe eines LLM verlassen, wie sie ist.
Um die Folgen zu veranschaulichen, vergleichen wir die Precision-Recall-Kurve für das deterministische Modell und das Modell mit Rauschen in seinen Vorhersagen, wie ein LLM.
Um dies zu simulieren, nehmen wir einen hypothetischen Satz von Scores und fügen ihnen etwas Rauschen hinzu. Dann vergleichen wir die Precision-Recall-Kurven:
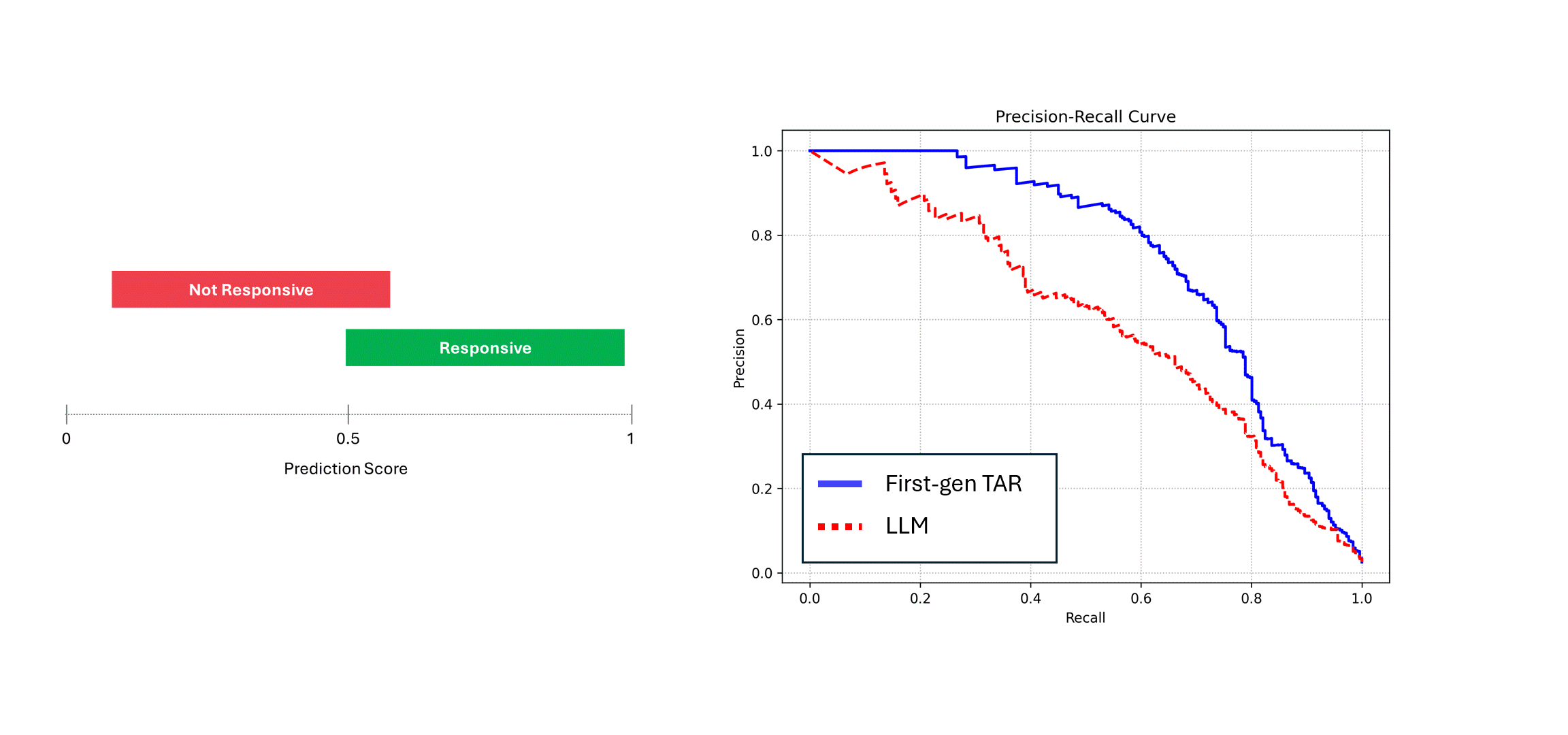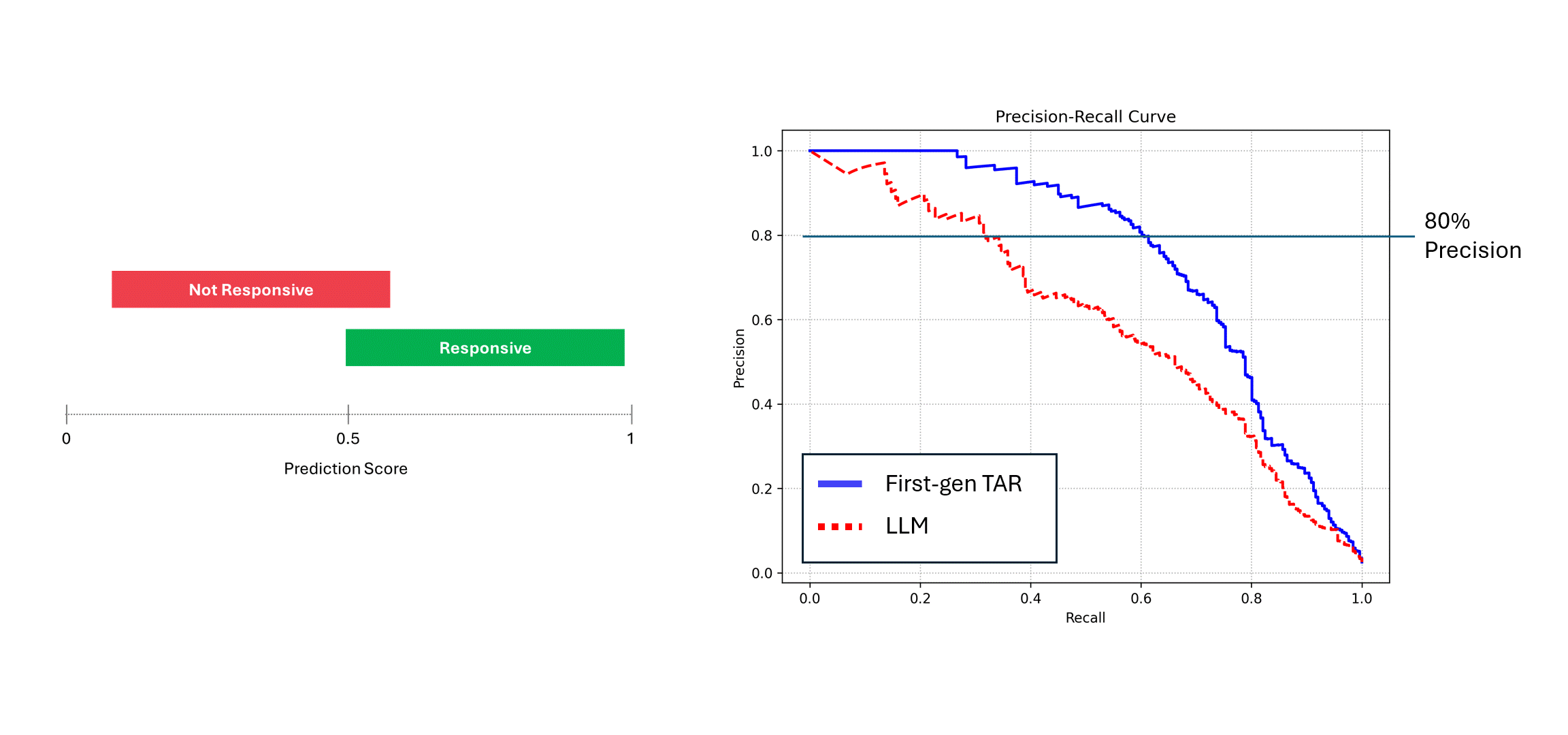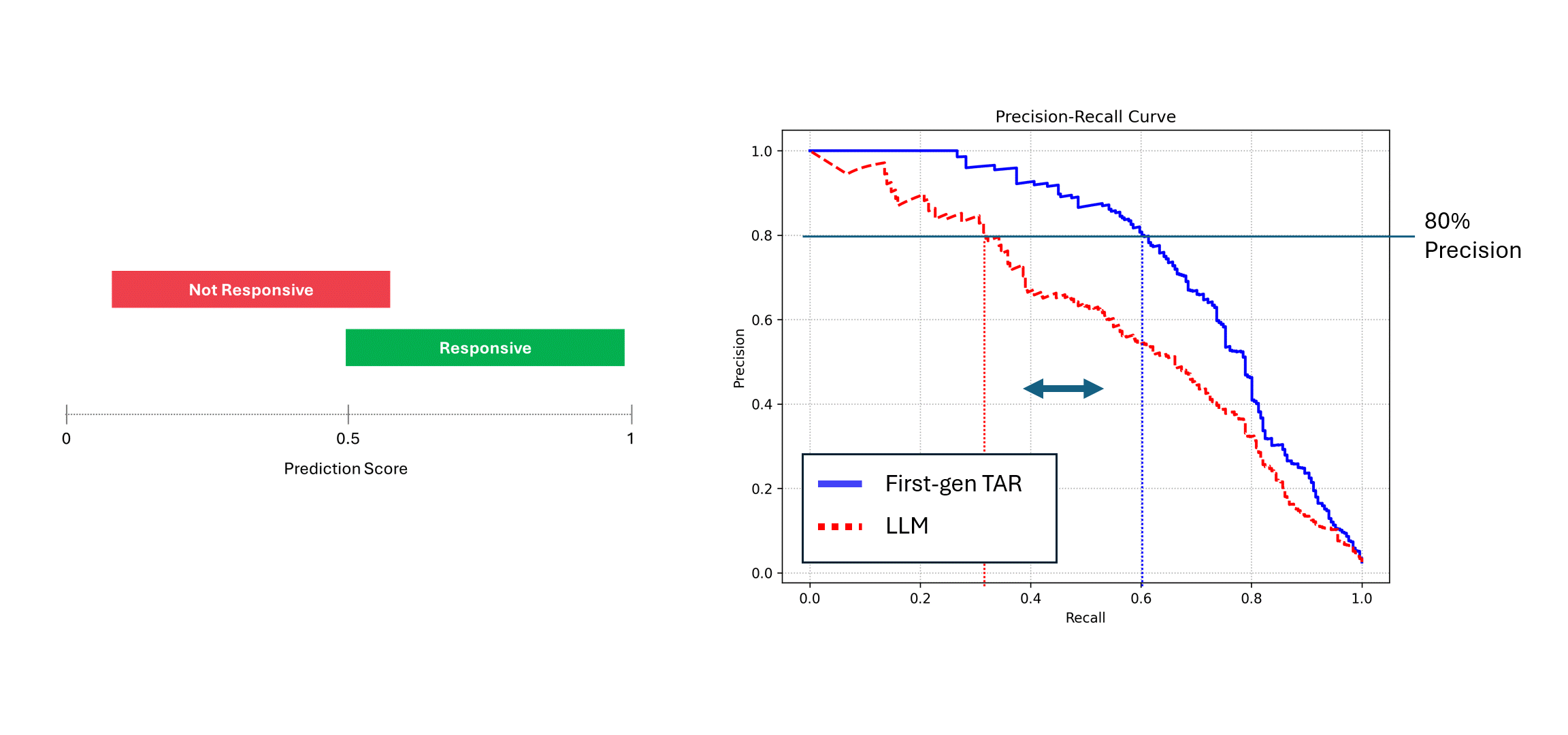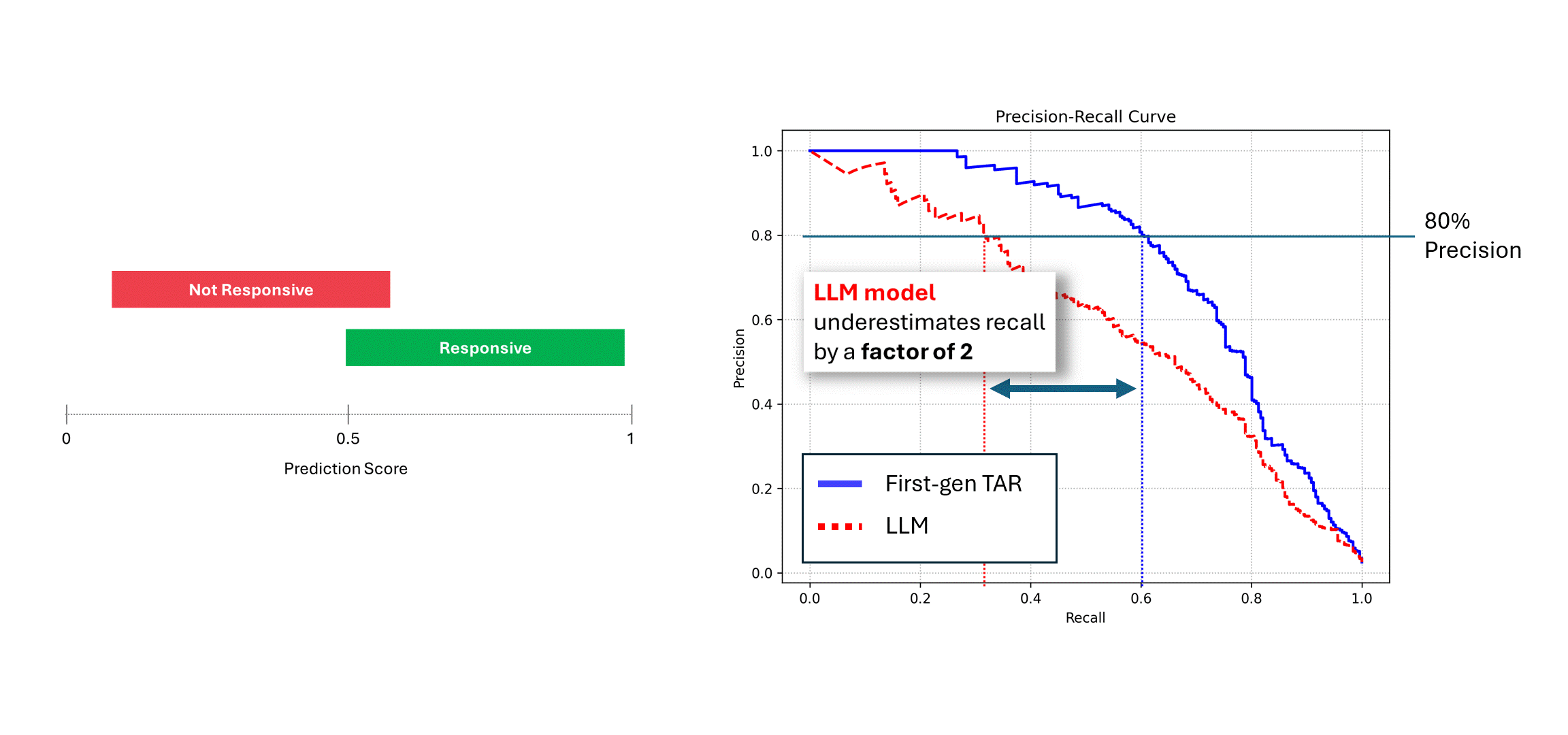
Wenn das verrauschte Modell (d. h. ein LLM) mehrfach auf denselben Daten ausgeführt wird und seine Ergebnisse gemittelt werden, dann nähern sich seine Precision und Recall der eines deterministischen Modells an, d. h. die blaue Kurve. Verlässt man sich jedoch auf einen einzigen Durchlauf seiner Vorhersagen (die rote Kurve), leidet die Leistung, da die wahre Leistung des Modells immer unterschätzt wird. Im obigen Beispiel kann die Leistung bis zur Hälfte des tatsächlichen Wertes angegeben werden.
Was sind die praktischen Auswirkungen?
Wenn Sie sich in der Praxis die Kurve für die Genauigkeit und den Abruf eines LLM ansehen (die rote Kurve oben), werden Sie nur eine unzureichende Leistung feststellen, ohne die Ursache zu kennen. Instinktiv versucht man, die Leistung des Modells zu verbessern, indem man vielleicht die Eingabeaufforderungen optimiert oder Beispiele hinzufügt.
In diesem Fall wäre all diese Mühe umsonst. Die Leistungslücke ist nicht darauf zurückzuführen, dass das Modell selbst nicht gut genug ist, sondern darauf, dass seine nicht-deterministische Natur die Leistung des Modells unterschätzt. Die einzige Möglichkeit, diese Leistungslücke zu schließen, besteht darin, den LLM mehrmals um Bewertungen zu bitten und seine Vorhersagen zu mitteln.
Angesichts der Tatsache, dass Sie Ihr Modell aus Kosten- und Zeitgründen nicht 10-mal auf jedem Dokument ausführen werden, gibt es Lösungen, um sicherzustellen, dass die Leistung des Modells genau angegeben wird? Die Antwort lautet ja - wir werden uns in unserem nächsten Blogbeitrag damit befassen. Bleiben Sie dran!

Igor Labutov, Vizepräsident, Epiq AI Labs
Igor Labutov ist Vizepräsident bei Epiq und Co-Leiter der Epiq AI Labs. Igor Labutov ist Informatiker mit einem starken Interesse an der Entwicklung von Algorithmen für maschinelles Lernen, die aus der natürlichen Überwachung durch den Menschen lernen, z. B. aus der natürlichen Sprache. Er verfügt über mehr als 10 Jahre Forschungserfahrung in den Bereichen Künstliche Intelligenz und maschinelles Lernen. Labutov promovierte an der Cornell University und war als Post-Doc an der Carnegie Mellon University tätig, wo er bahnbrechende Forschungen an der Schnittstelle zwischen menschenzentrierter KI und maschinellem Lernen durchführte. Bevor er zu Epiq kam, war Labutov Mitbegründer von LAER AI, wo er seine Forschungsergebnisse zur Entwicklung neuer Technologien für die Rechtsbranche einsetzte.
Der Inhalt dieses Artikels dient lediglich der allgemeinen Information und stellt keine Rechtsberatung dar.
Subscribe to Future Blog Posts
