


Mettre en œuvre la protection des données à l’ère de l’IA pour une gouvernance responsable
- Information governance
- 1 min
Point clé à retenir: Les étiquettes de sensibilité et les classificateurs intelligents constituent le socle de la gouvernance responsable de l’IA.Ils automatisent l’identification et la protection des données sensibles à grande échelle, réduisent les erreurs humaines et accélèrent la mise en conformité. Associés à des politiques dynamiques et proactives, ils sécurisent les informations sur l’ensemble des canaux, limitent les risques et garantissent le respect des exigences réglementaires. Commencez par une phase de découverte et un déploiement progressif ciblé sur les zones à haut risque, puis faites évoluer la gouvernance au rythme des avancées technologiques.
L’intelligence artificielle transforme les opérations des entreprises à une vitesse fulgurante, et les organisations s’efforcent de suivre le rythme. Des outils comme Copilot promettent des gains d’efficacité et des réductions de coûts, mais ils introduisent également de nouveaux risques. Au cœur de ces risques se trouvent vos données les plus sensibles.
S’engager dans une démarche d’adoption responsable de l’IA nécessite une feuille de route claire. Le cadre Copilot Readiness en 10 étapes a été conçu pour accompagner les organisations à chaque phase clé du déploiement de Copilot, de manière sécurisée et efficace. Après la troisième étape, consacrée à la montée en compétence des équipes grâce à des formations aux prompts adaptées aux fonctions métier, la quatrième étape porte sur un enjeu essentiel : la mise en place d’un cadre stratégique de protection des données. Cette approche va bien au delà du simple respect des exigences de conformité. Il s’agit d’instaurer la confiance, de promouvoir des pratiques d’IA éthiques et de bâtir une organisation résiliente, capable de s’adapter et de prospérer dans la durée.
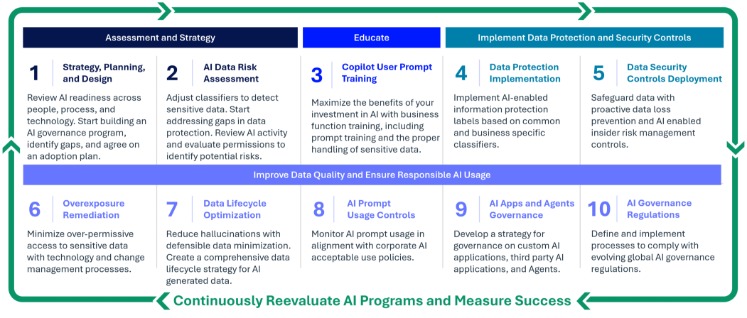
Comprendre les classificateurs et les étiquettes de sensibilité : le socle de la protection moderne des données
À mesure que les organisations adoptent l’IA et des outils de collaboration basés sur le cloud, la protection des informations sensibles devient à la fois plus complexe et plus essentielle que jamais. Mais par où commencer pour renforcer sa posture de protection des données ? La réponse réside dans la capacité à bien connaître ses données, grâce aux classificateurs intelligents et aux étiquettes de sensibilité.
Que sont les classificateurs et pourquoi sont ils essentiels ?
Imaginez devoir trier des volumes considérables de documents, d’e mails et de conversations contenant à la fois des mises à jour anodines et des informations clients confidentielles, des données réglementées ou des informations personnellement identifiables (PII). Les classificateurs sont des assistants intelligents qui effectuent ce tri pour vous. Ils identifient et catégorisent automatiquement les contenus en fonction de leur contexte ou de schémas spécifiques. Cela garantit que les informations sensibles ne restent jamais sans surveillance et que la classification accompagne les fichiers, où qu’ils se trouvent.
Avec Microsoft Purview, vous n’êtes pas limité à des règles rigides. Les classificateurs avancés et entraînables exploitent la puissance de l’IA pour comprendre des concepts au sein de textes non structurés. Ainsi, même lorsque les données ne suivent pas de modèle prédéfini, elles peuvent être identifiées et protégées. Qu’il s’agisse de classificateurs intégrés ou de modèles que vous créez vous même, ils s’adaptent aux besoins spécifiques de votre organisation.
Les types d’informations sensibles (Sensitive Information Types – SIT) s’appuient sur la détection de modèles et l’empreinte documentaire pour identifier avec précision et sécuriser les données réglementées. Lorsque la précision est essentielle, Exact Data Match (EDM) permet de faire correspondre les identifiants métier uniquement avec les enregistrements appropriés, réduisant ainsi les faux positifs et maintenant les efforts de protection des données sur ce qui compte réellement. Ces classificateurs peuvent être entraînés à l’aide de mécanismes de retour d’information, puis affinés au fil du temps en fonction des besoins.
Libérer le potentiel des étiquettes de sensibilité
La classification de l’information n’est qu’une première étape. La véritable valeur d’un cadre de sécurité réside dans la capacité à exploiter ces classifications de manière concrète. Les étiquettes de sensibilité agissent comme des marqueurs numériques qui accompagnent vos fichiers, e mails et espaces de collaboration. Elles indiquent comment chaque élément doit être classifié, qu’il s’agisse de « Public », « Interne », « Confidentiel » ou « Restreint », conformément aux normes de votre organisation et aux exigences réglementaires. Celles ci incluent des cadres tels que HIPAA, le RGPD, la loi indienne DPDP ou toute autre obligation de conformité sectorielle. Ainsi, les étiquettes de sensibilité restent pertinentes pour tous les secteurs, notamment l’éducation, la santé, l’industrie manufacturière, le commerce de détail, la finance, la technologie et les administrations publiques.
Microsoft Purview permet l’application automatique ou manuelle d’étiquettes de sensibilité sur les données, sur des plateformes telles que SharePoint, OneDrive, Outlook et Teams, en activant instantanément les protections associées. Les modes de simulation permettent de tester les politiques en toute sécurité, tandis que les analyses à la demande garantissent que les fichiers plus anciens sont également protégés. Cette automatisation est essentielle dans l’environnement IA actuel, en constante évolution.
Les étiquettes de sensibilité ne sont pas de simples indicateurs visuels ; elles permettent l’application de contrôles de prévention des pertes de données (DLP), étendent la protection aux appareils Windows ainsi qu’aux types de fichiers intégrés, et facilitent la gestion des accès dans les espaces collaboratifs comme Teams et SharePoint, sans compromettre la productivité ni la collaboration. Dans les scénarios de protection des données liés à l’IA, notamment avec Copilot et Azure AI Search, ces étiquettes apportent une couche de défense supplémentaire, garantissant la sécurité des informations sensibles même lorsque les équipes exploitent des technologies avancées. Ensemble, les classificateurs et les étiquettes constituent le socle d’une stratégie de gouvernance de l’information, permettant aux organisations d’automatiser la classification et la protection des données à grande échelle.
Guide étape par étape pour mettre en œuvre la protection des données liée à l’IA
Première étape : Découvrir
Évaluez l’usage de l’IA en identifiant l’ensemble des outils et intégrations d’IA utilisés au sein de votre organisation. Appuyez vous sur Microsoft Purview Data Security Posture Management (DSPM) pour suivre les flux de données et mettre en lumière les risques d’exposition. Documentez les scénarios à haut risque, tels que des prompts d’IA tentant d’accéder à des données sensibles.
Deuxième étape : Protéger
Définissez votre stratégie de labellisation en créant une taxonomie d’étiquettes de sensibilité (par exemple : Public, Interne, Confidentiel et Restreint) alignée sur les exigences de conformité et les besoins de l’organisation. Configurez des conseils de stratégie (policy tips) afin d’accompagner les utilisateurs lors de l’application manuelle des étiquettes.
Activez l’étiquetage automatique via des stratégies côté service pour SharePoint, OneDrive et Exchange, afin de classifier les données au repos. Utilisez le mode simulation pour valider la couverture, puis étendez l’application des étiquettes à Teams, aux Groupes et aux Sites.
Troisième étape : Prioriser
Configurez des stratégies DLP pour l’IA faisant référence aux étiquettes de sensibilité afin de surveiller et de contrôler les déplacements de données. Commencez en mode audit uniquement pour collecter des informations, puis appliquez progressivement des restrictions sur les chargements, les actions dans le navigateur et les prompts d’IA.
Quatrième étape : Gouverner
Assurez un suivi et une optimisation continus en examinant les rapports et évaluations de conformité dans Microsoft Purview afin d’en mesurer l’efficacité. Ajustez les classificateurs et les étiquettes en fonction des retours d’expérience. Étendez la couverture aux terminaux et intégrez les services d’IA tels que Copilot et Azure AI Search pour mettre en œuvre des contrôles d’accès basés sur les étiquettes.
Prérequis fondamentaux pour la protection des données liée à l’IA
Une protection efficace des données liées à l’IA repose sur une surveillance continue, associée à une sensibilisation claire des collaborateurs afin de garantir la conformité et une adoption fluide. Appuyez vous sur les quatre approches présentées ci dessus comme socle de votre démarche. Le calendrier de mise en œuvre de la protection des données varie en fonction de la taille et du niveau de maturité de votre organisation. Il est recommandé de commencer par les zones à haut risque et d’utiliser des outils de détection précoce pour obtenir de la visibilité et réduire les risques, même avant un déploiement complet.
La gouvernance responsable de l’IA commence par les données
Mettre en œuvre la protection des données à l’ère de l’IA est un impératif stratégique qui exige de l’anticipation, de la flexibilité et un engagement fort en faveur d’une gouvernance responsable.
Si vos informations sensibles ne sont pas encore pleinement protégées, inutile de céder à la panique : il est temps d’agir. Commencez par évaluer où se trouvent vos données et comment elles sont utilisées. Puis mettez en place un cadre structuré combinant découverte, classification et politiques proactives.
Recherchez un partenaire disposant d’une expertise éprouvée en gouvernance de l’IA et en conformité réglementaire. Un prestataire de confiance vous aidera à automatiser la protection des données à grande échelle et à vous accompagner dans des déploiements progressifs, garantissant un processus fluide et maîtrisé. Le bon accompagnement permet à votre organisation non seulement de respecter les exigences réglementaires, mais aussi de renforcer la confiance et la résilience sur le long terme.
Pour en savoir plus sur Epiq Responsible AI et la démarche Copilot Readiness.

Jon Kessler, Vice président et directeur général, Gouvernance de l’information
En tant que vice président et directeur général de la gouvernance de l’information au sein de la division Legal Solutions d’Epiq, Jon dirige une équipe internationale dédiée à l’accompagnement des clients dans l’exploitation de la valeur de Microsoft Purview à travers des services d’IA responsable et de préparation à Copilot. Sous sa direction, l’équipe a été reconnue Microsoft Compliance Partner of the Year en 2023 et finaliste en 2022, 2024 et 2025.

Swapnil Sawant, Spécialiste senior en sécurité des données, Gouvernance de l’information
Swapnil est un professionnel expérimenté de la sécurité de l’information, fort de plus de dix ans d’expérience dans les secteurs du conseil, des solutions logicielles, de l’industrie manufacturière et de la banque. Spécialisé dans la protection des données liée à l’IA, il accompagne les organisations dans l’élaboration de stratégies adaptées à l’évolution des besoins clients.
Cet article est destiné à fournir des informations générales et non des conseils ou des avis juridiques.