


Pourquoi l'évaluation de la confiance avec les LLM est dangereuse
Lorsqu'il s'agit d'évaluer la confiance des MFR, il est essentiel de noter les prédictions. La chose la plus importante n'est pas les scores eux-mêmes, mais le classement résultant que ces scores produisent.
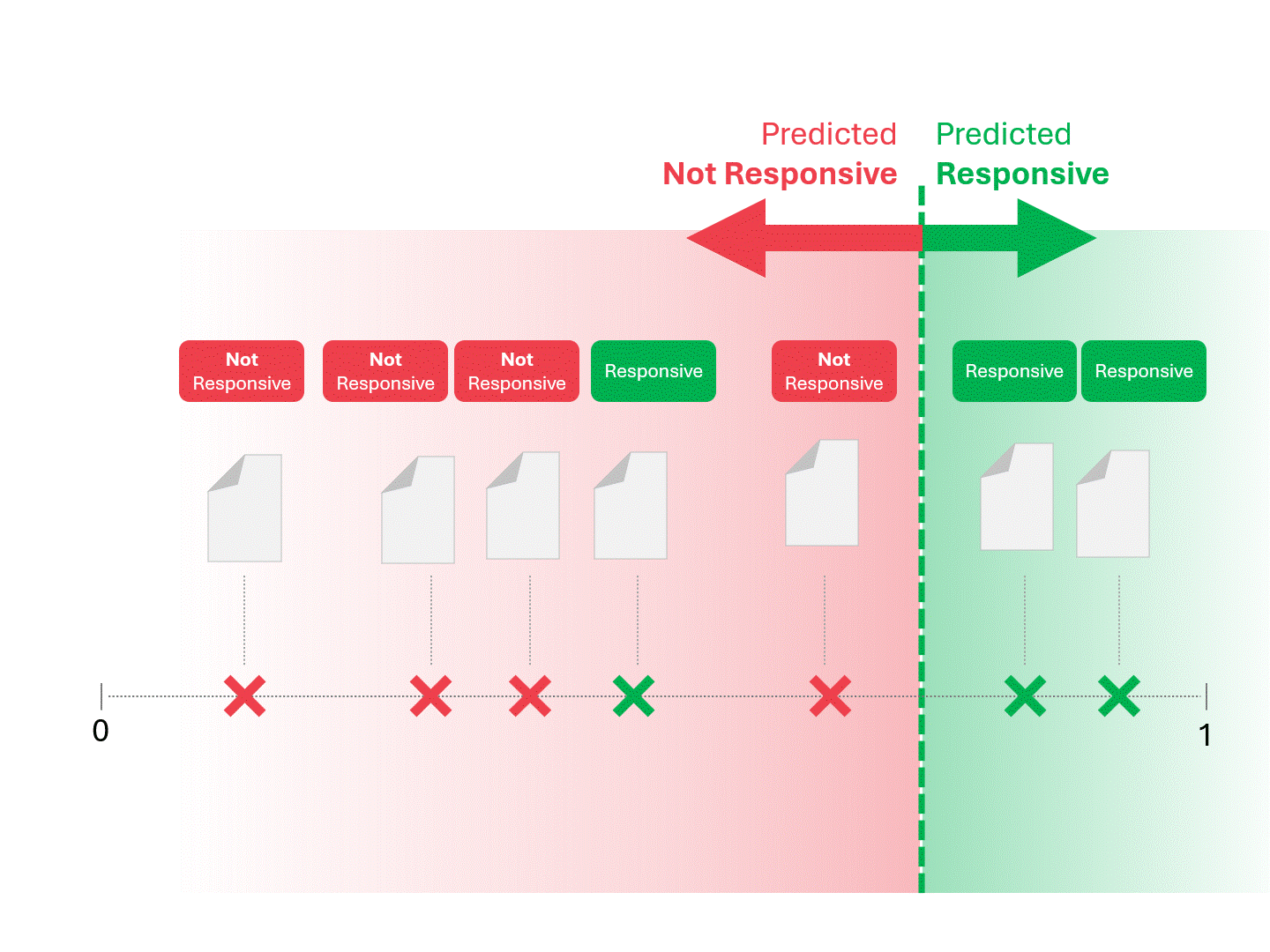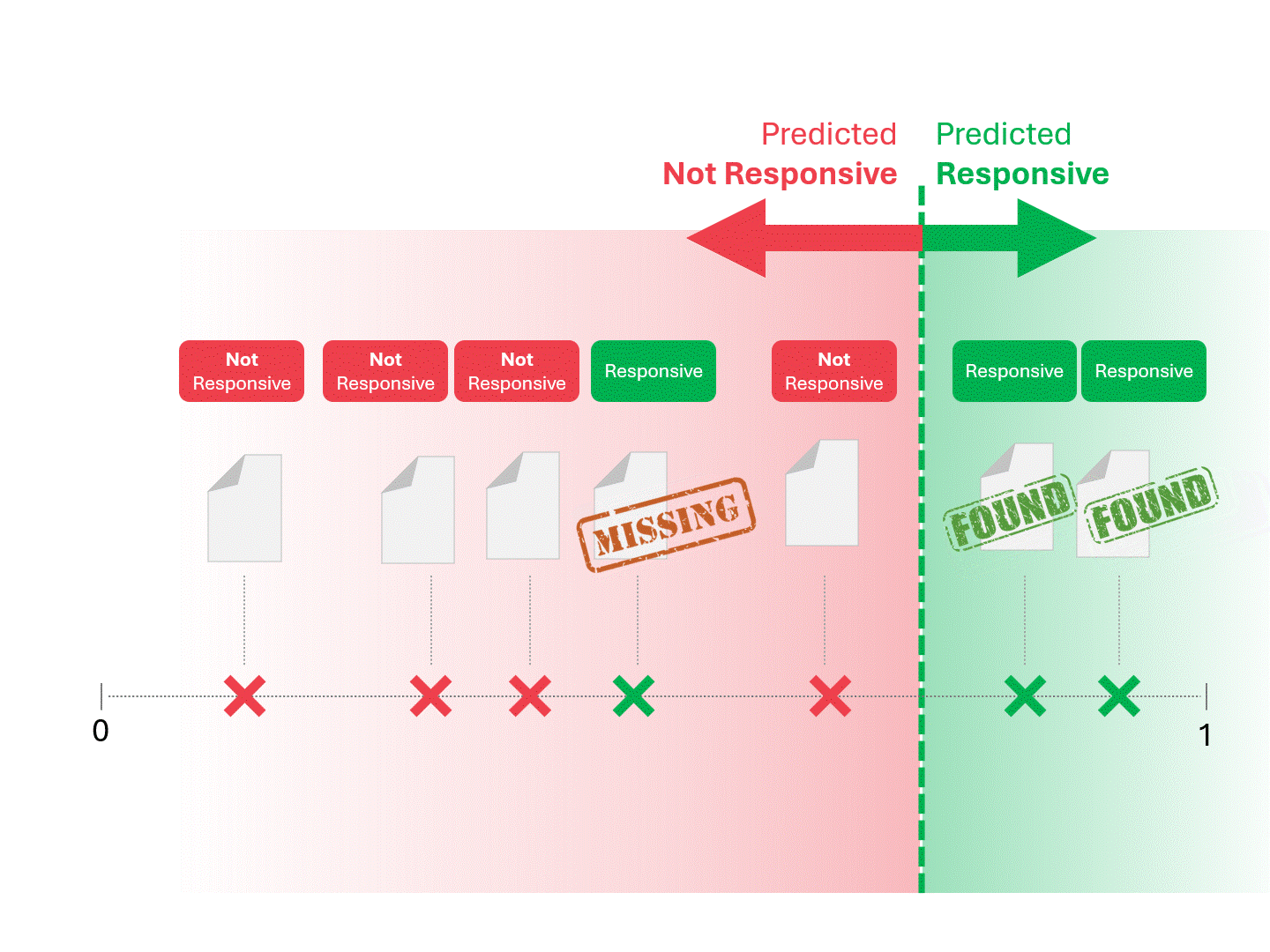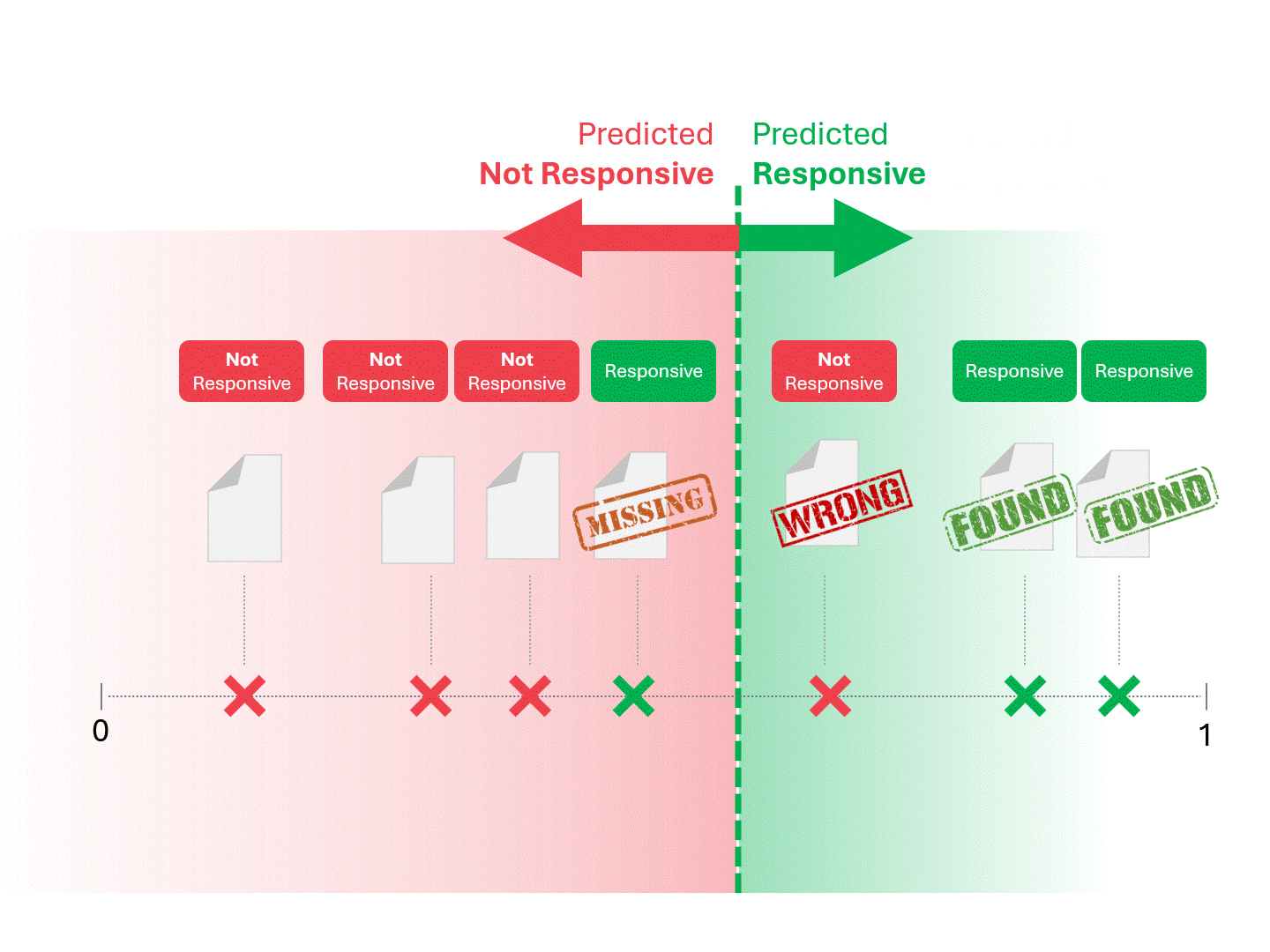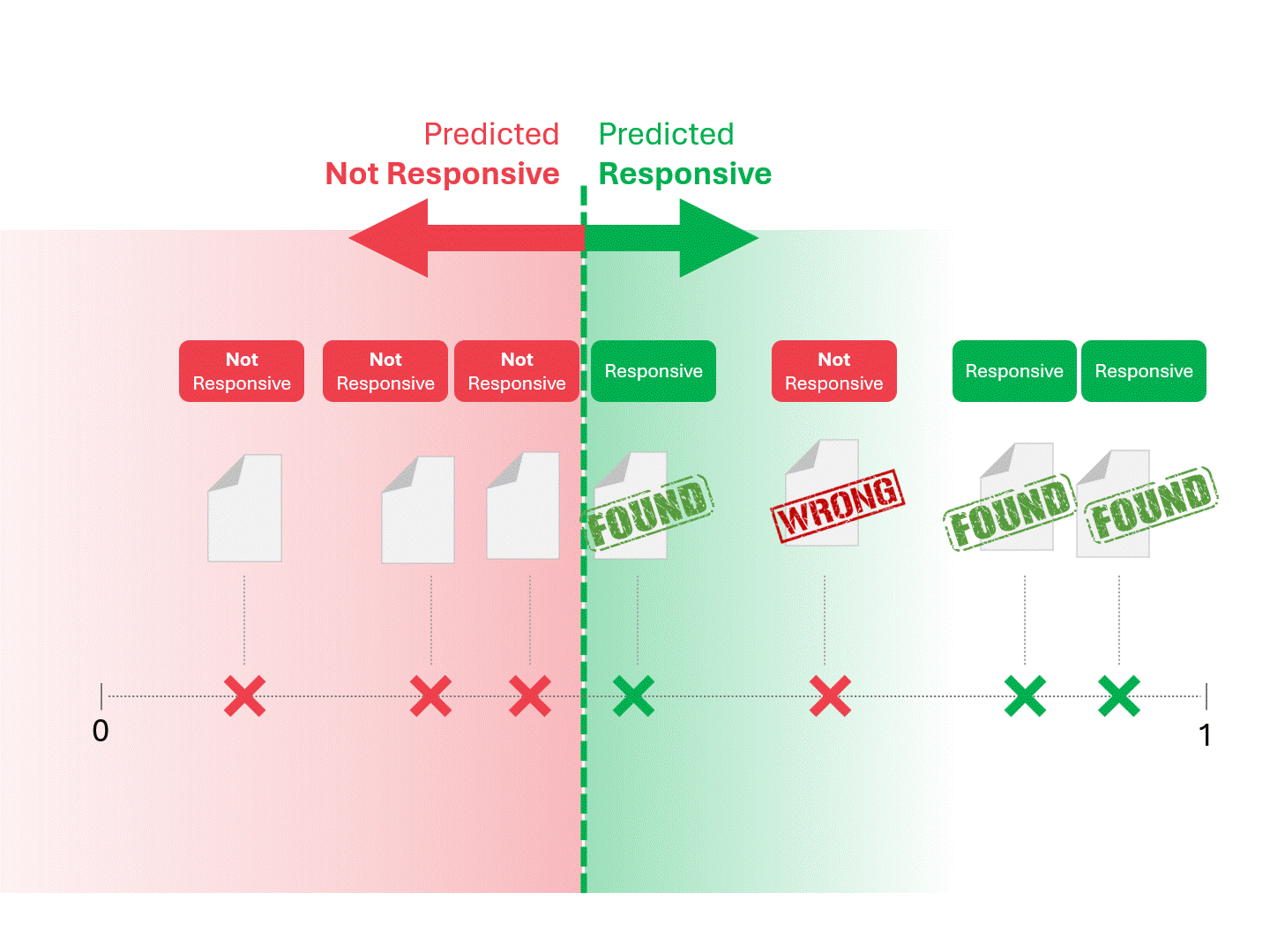
Une fois que notre modèle (TAR 1.0, TAR 2.0, CAL ou LLM) donne un score, nous classons les exemples et traçons une ligne de démarcation :

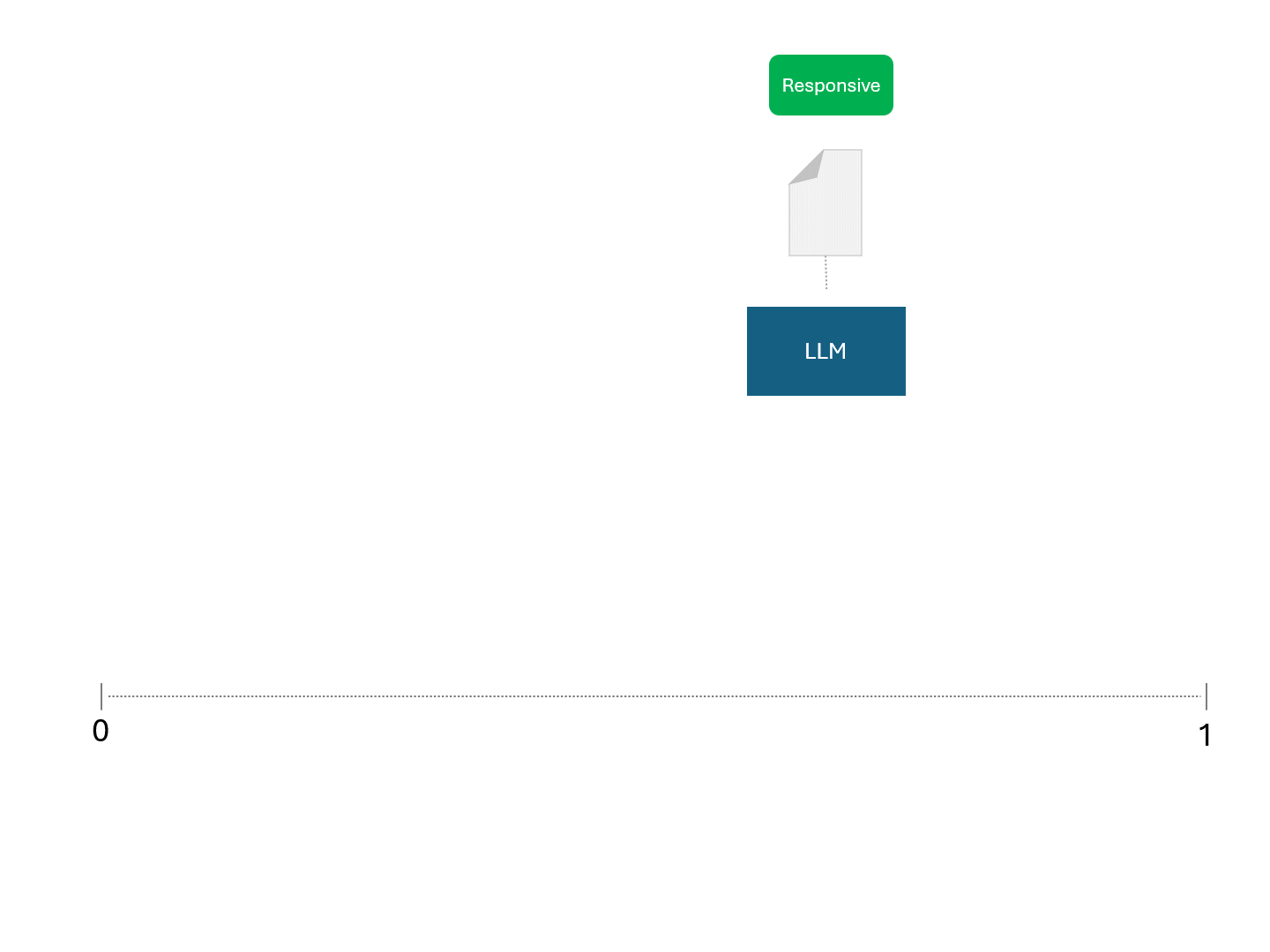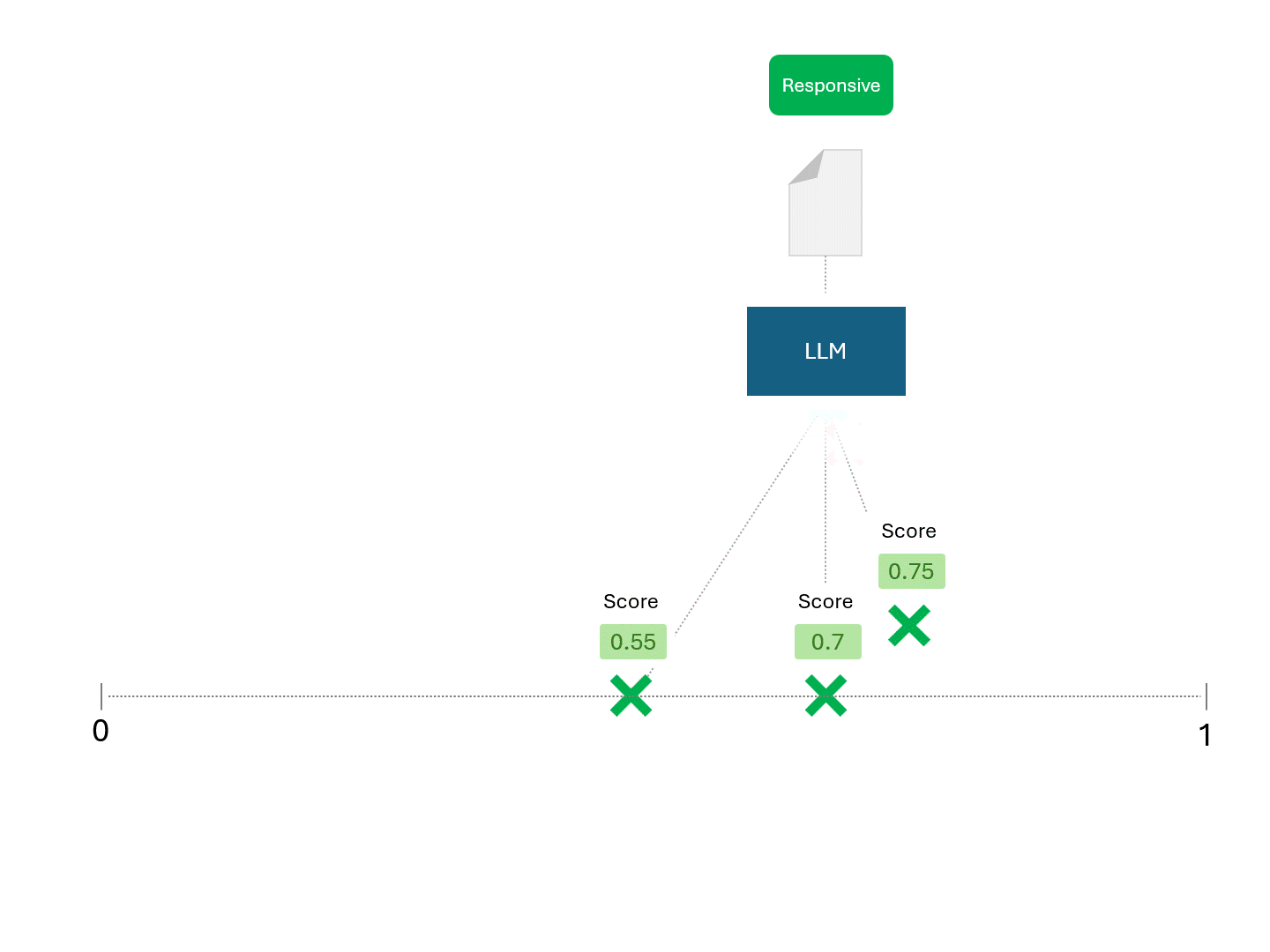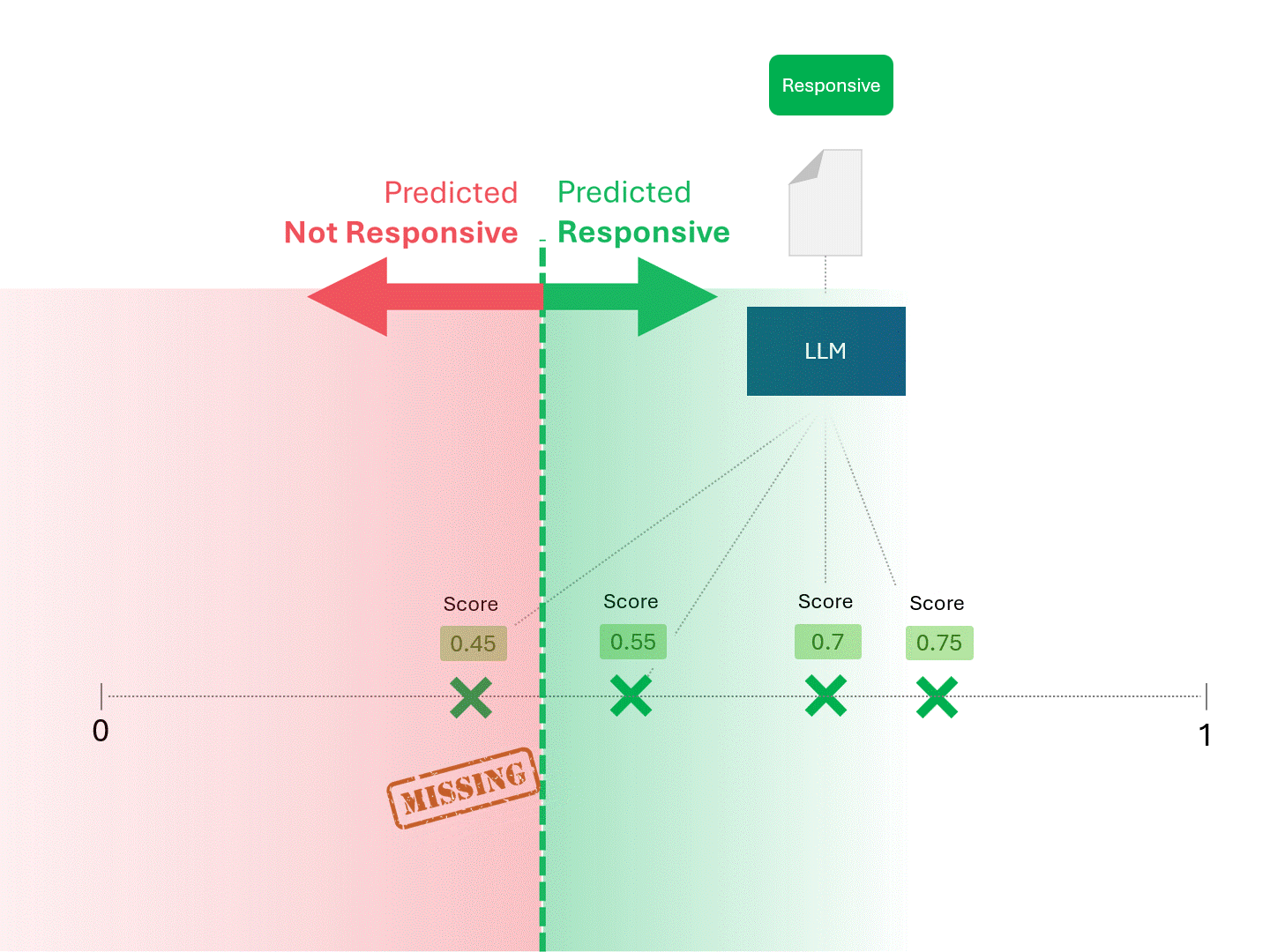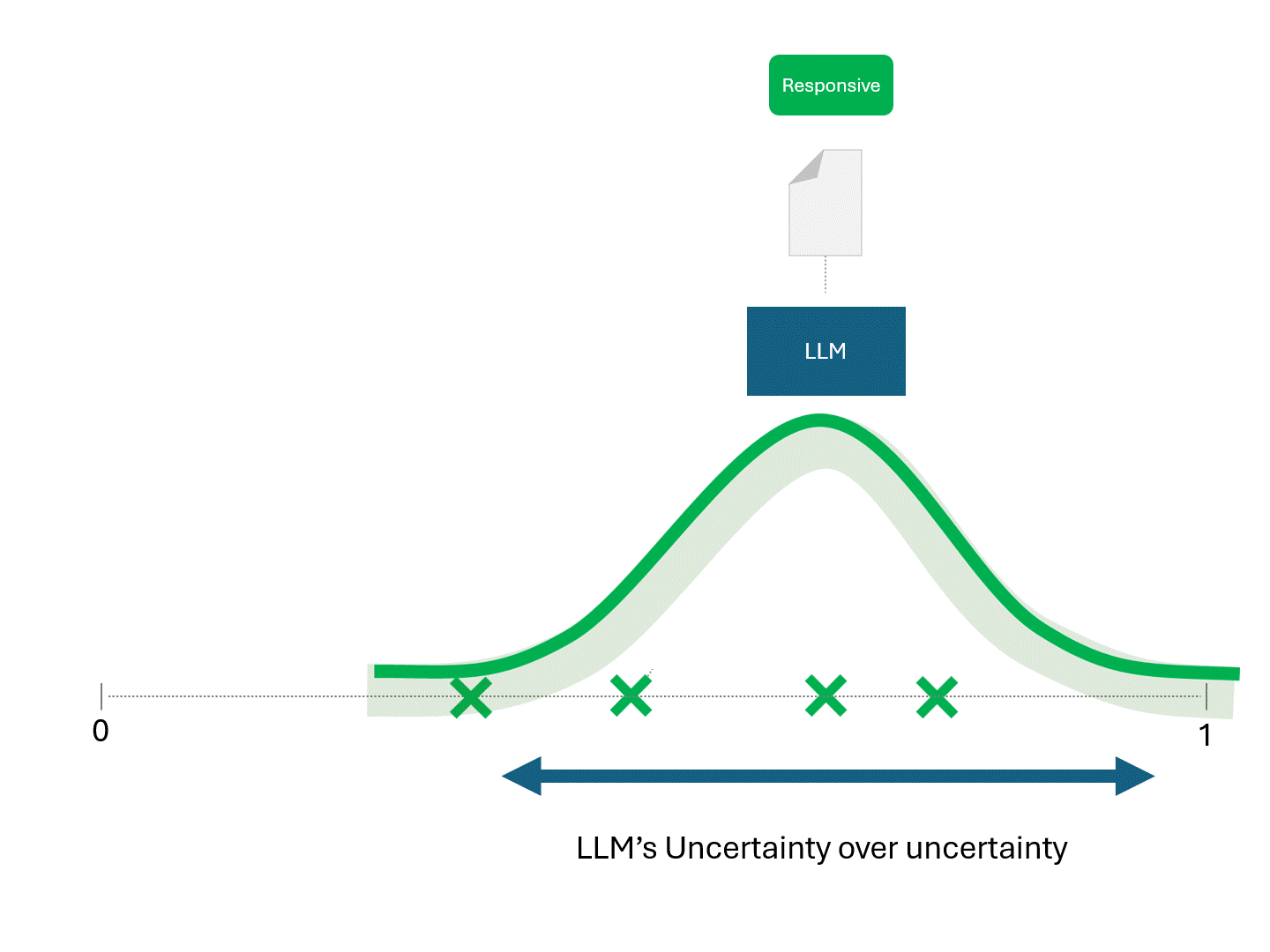
Nous décidons de la réactivité de chaque document en traçant une ligne pour séparer ce que le modèle appellerait « réactif » et « non réactif ». La séparation qui en résulte comporte parfois des erreurs, qu'il s'agisse de faux positifs ou de faux négatifs.
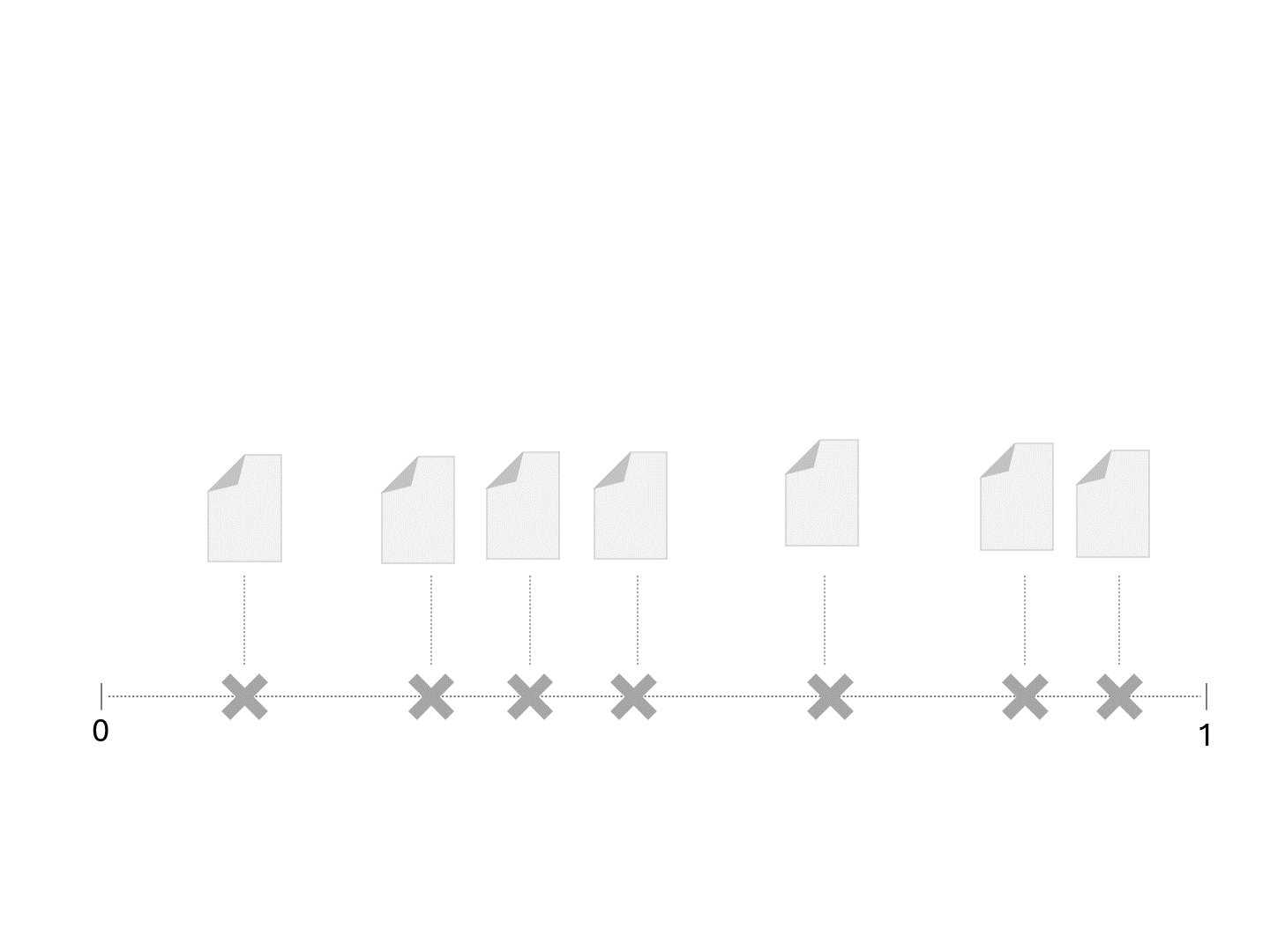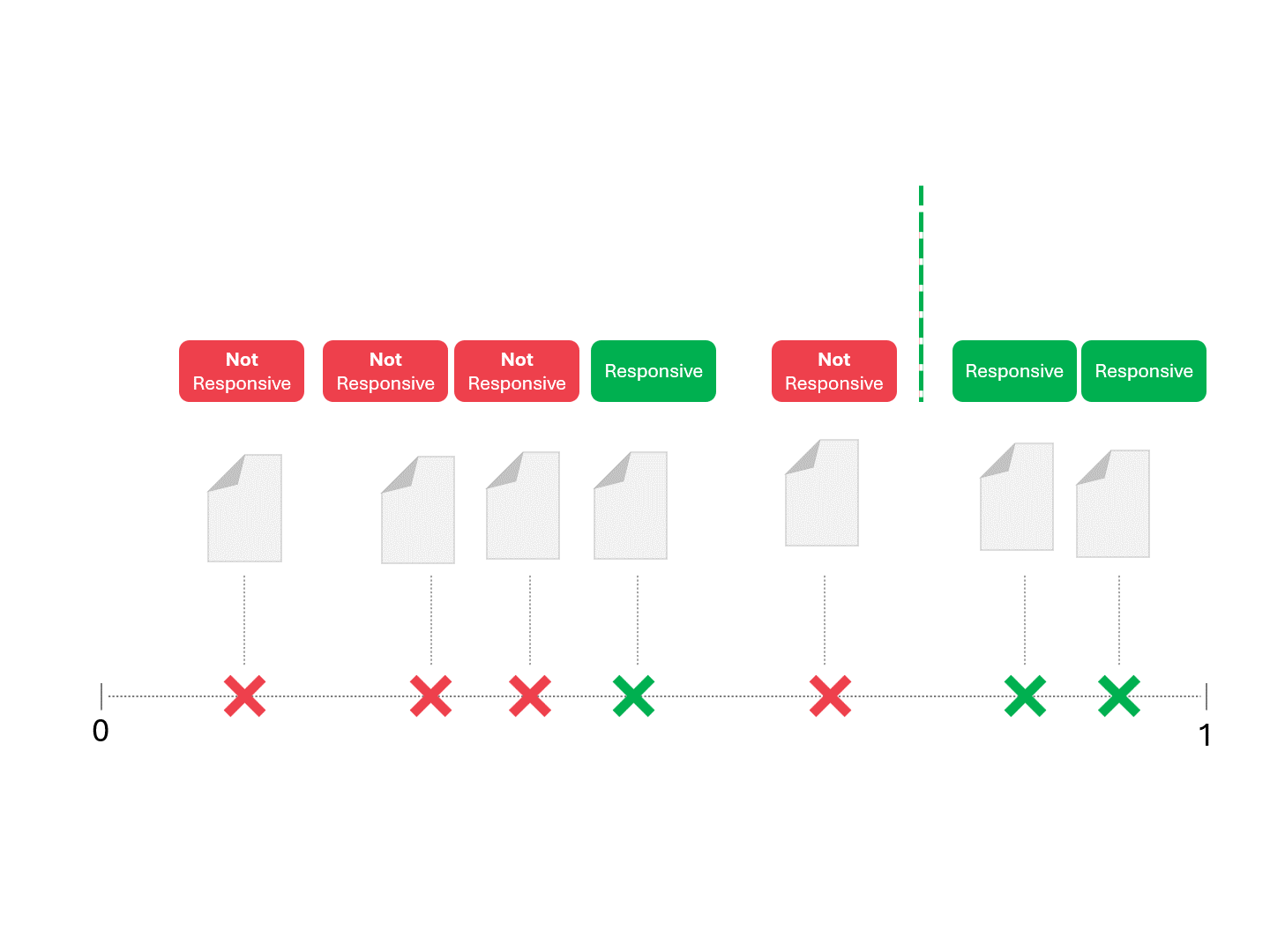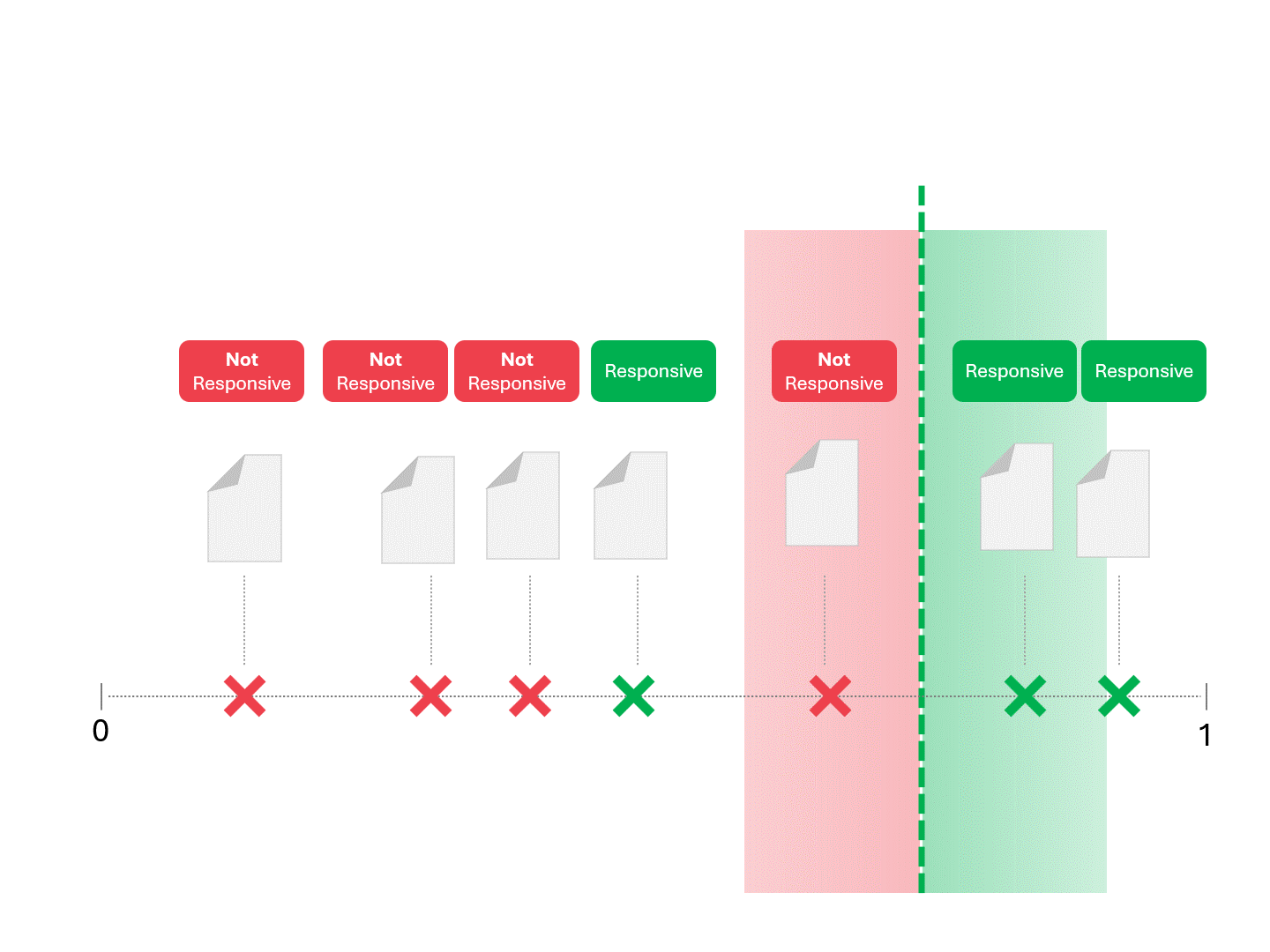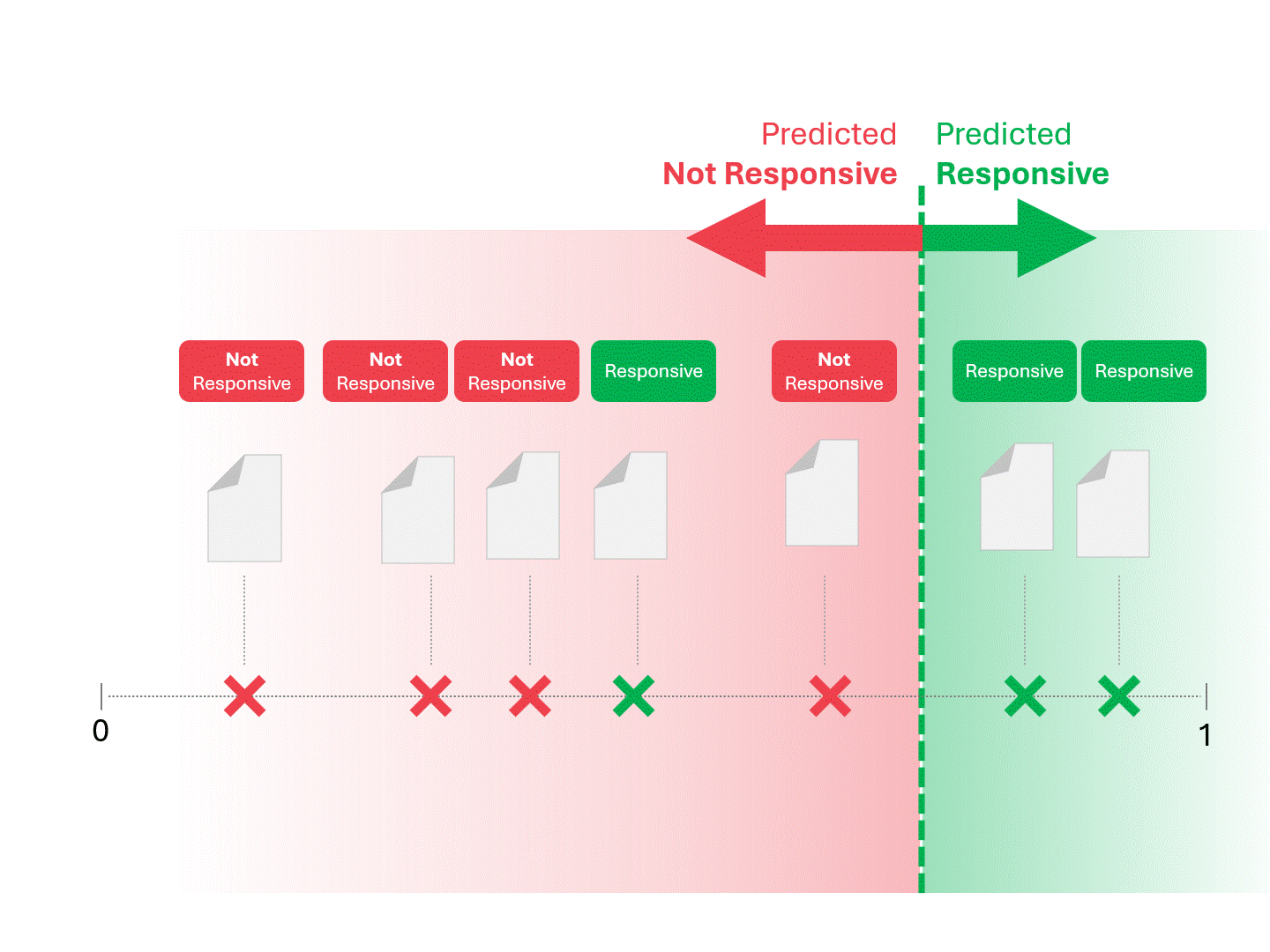
Lorsque nous modifions le seuil de notation, nous obtenons des résultats et des taux d'erreur différents. Par exemple, l'inclusivité peut donner plus de faux positifs mais manquer moins de faux négatifs, un compromis que nous devons accepter dans le cadre de l'utilisation de tout modèle d'apprentissage automatique. Il n'y a pas de réponse correcte, il s'agit plutôt d'un jugement de valeur.
Le processus décrit ci-dessus est standard depuis que TAR existe. Tant qu'un modèle nous donne un score quelconque, la méthode ci-dessus peut être utilisée pour faire des prédictions.
La seule différence entre les modèles TAR et les LLM est que les scores obtenus à partir d'un LLM ne sont pas déterministes. L'exécution répétée du même modèle sur les mêmes données exactes donnerait des scores différents et donc un classement différent.
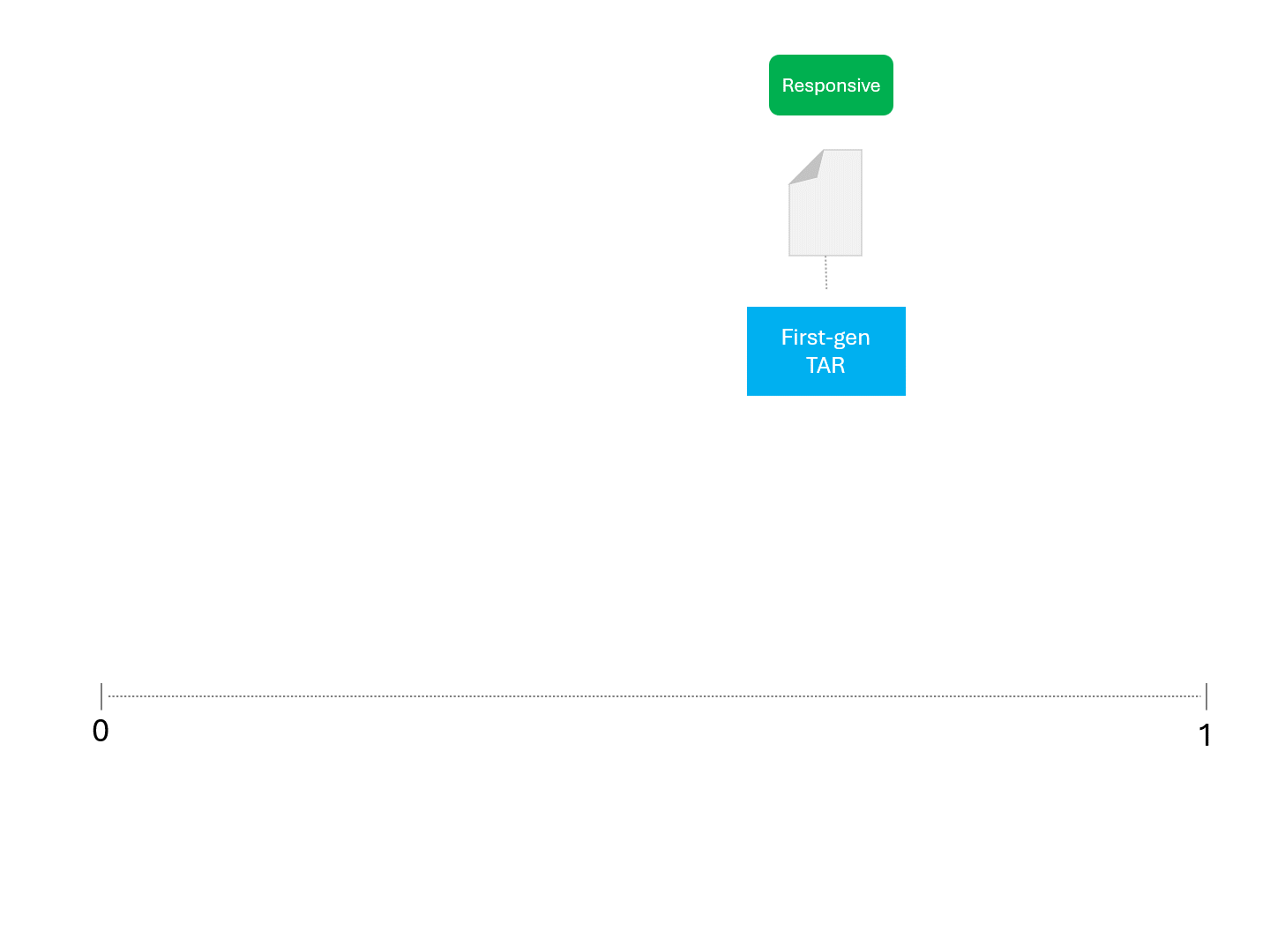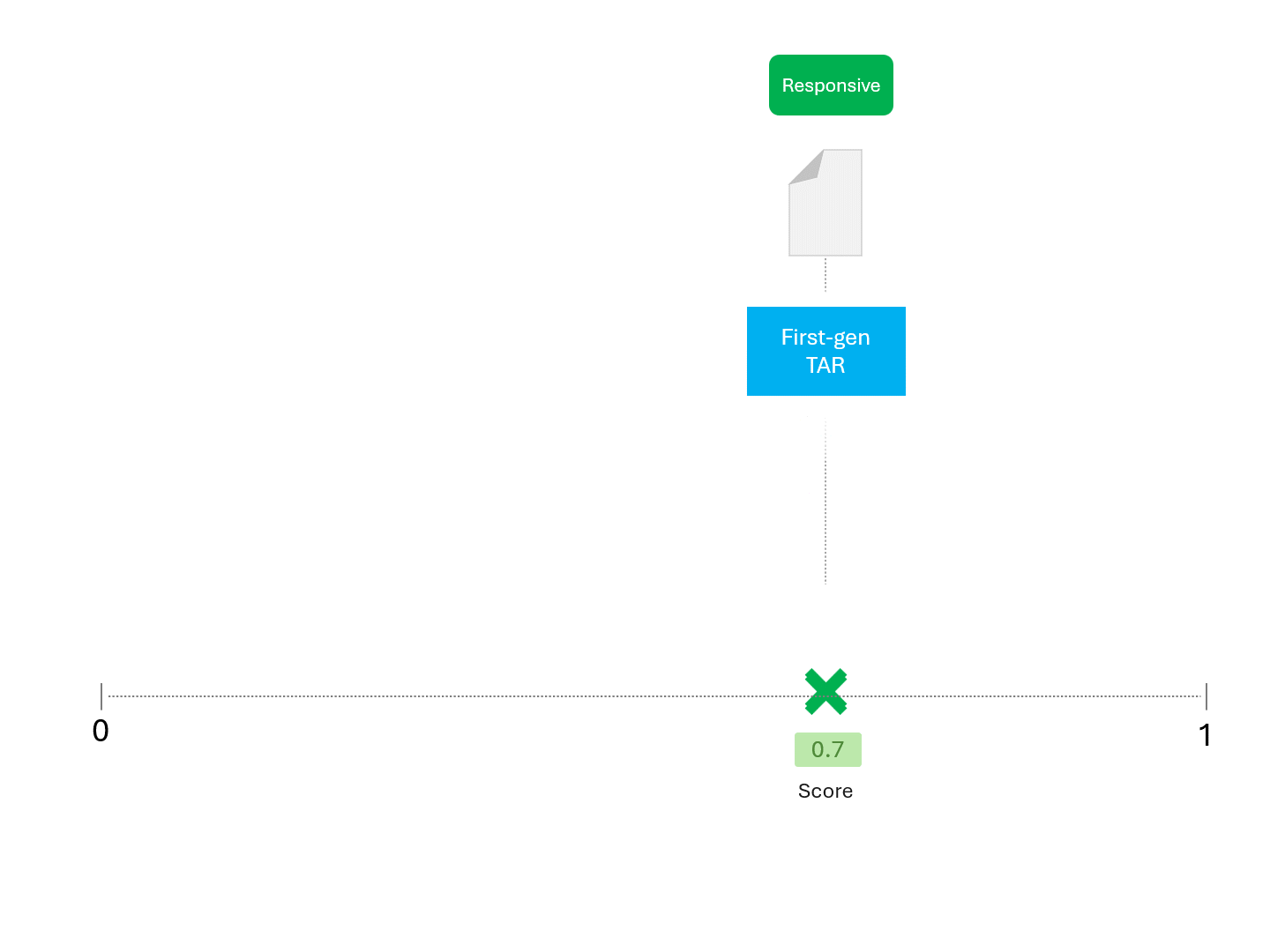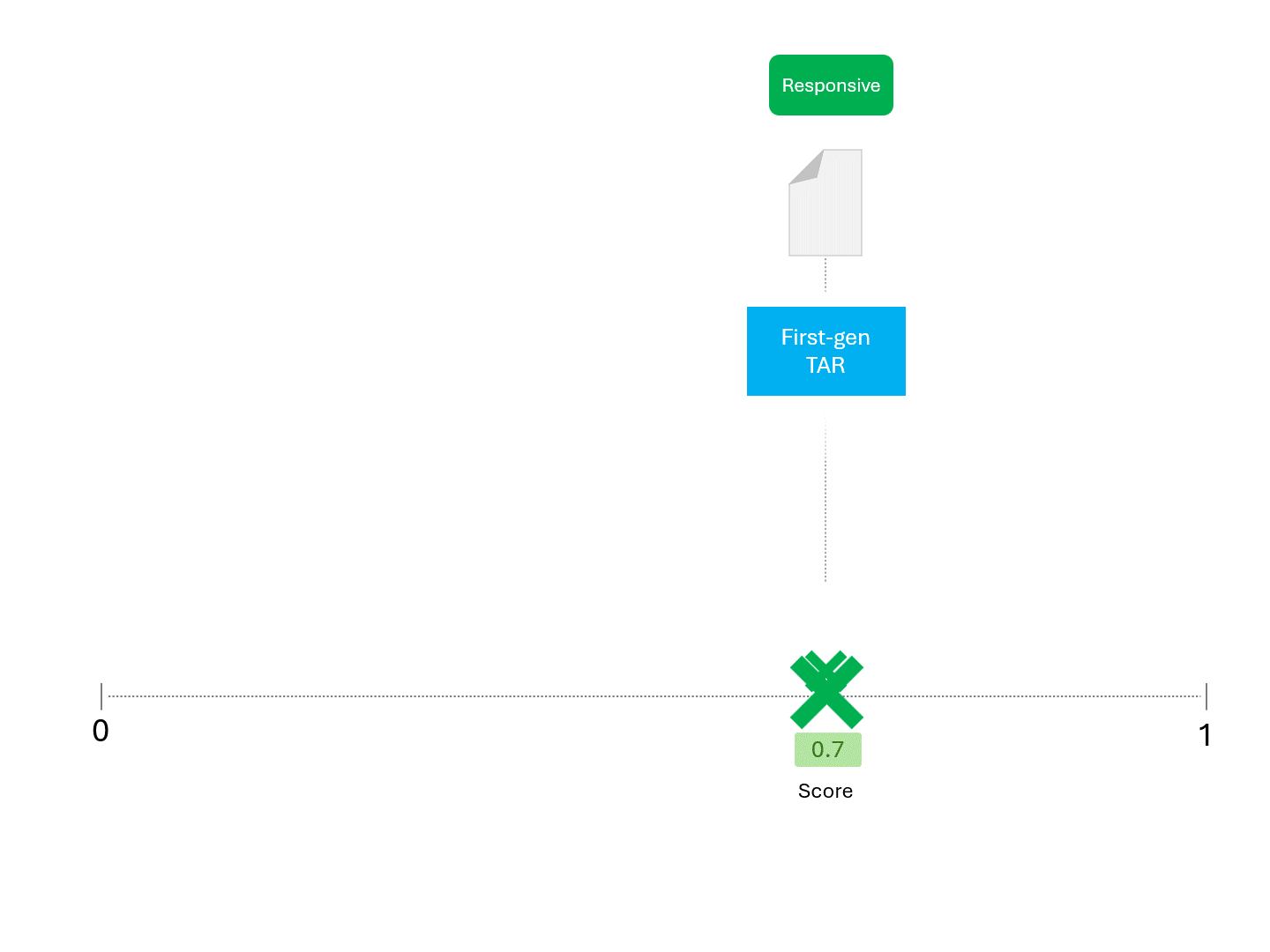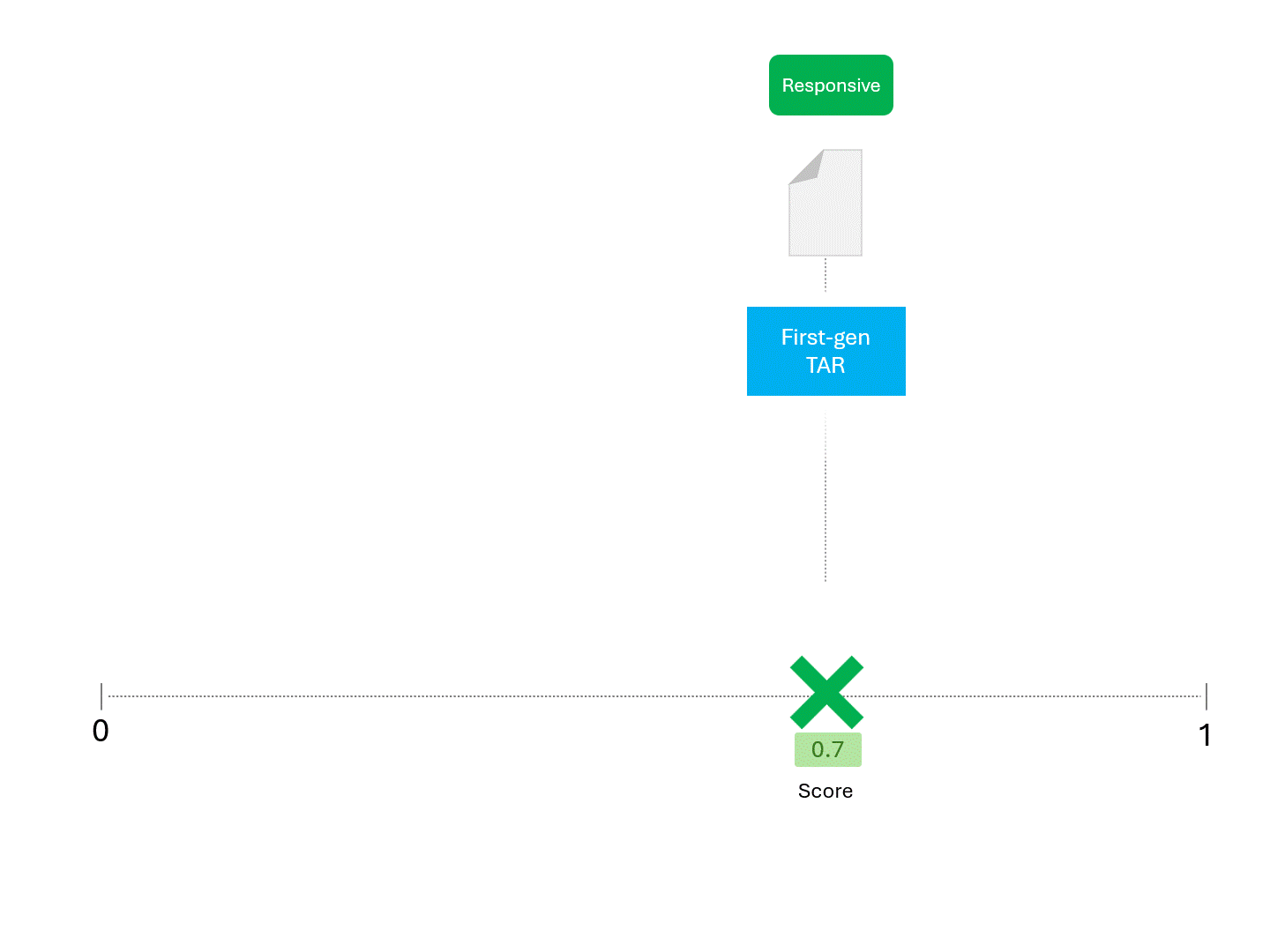
Par exemple, si l'on demande à un modèle TAR d'obtenir un score à plusieurs reprises, on peut s'attendre à quelque chose comme ceci :
En revanche, demander un score à un LLM ressemblerait à ceci :
Étant donné que des scores différents se traduisent par des classements différents, chaque fois que vous demandez à un LLM de faire des prédictions, vous vous attendez également à des mesures de performance différentes, telles que le rappel et la précision.
Quelle est la solution ?
Nous avons mentionné précédemment que la seule façon d'augmenter la cohérence des prédictions d'un modèle est de faire la moyenne des prédictions elles-mêmes ou des scores, par exemple en demandant au LLM à plusieurs reprises le score pour le même document et en faisant ensuite la moyenne des résultats. Avec un nombre suffisant de requêtes, la moyenne convergerait vers le véritable score de prédiction et se stabiliserait, semblant plus proche du déterminisme qu'avec les modèles traditionnels.
TLe problème que pose cette méthode est qu'il n'est pas pratique de répéter plusieurs fois une requête à un LLM, en particulier avec quelque chose comme le GPT-4 où les coûts sont souvent prohibitifs.
Quelles sont les conséquences ?
Examinons ce qui se passe lorsque nous nous fions simplement à la sortie de confiance d'un LLM tel qu'il est.
Pour illustrer les conséquences, nous comparons la courbe Précision-Recall pour le modèle déterministe et le modèle avec du bruit dans ses prédictions, comme un LLM.
Pour simuler cela, nous prenons un ensemble hypothétique de scores et y ajoutons du bruit. Ensuite, nous comparons les courbes de Précision-Recall :
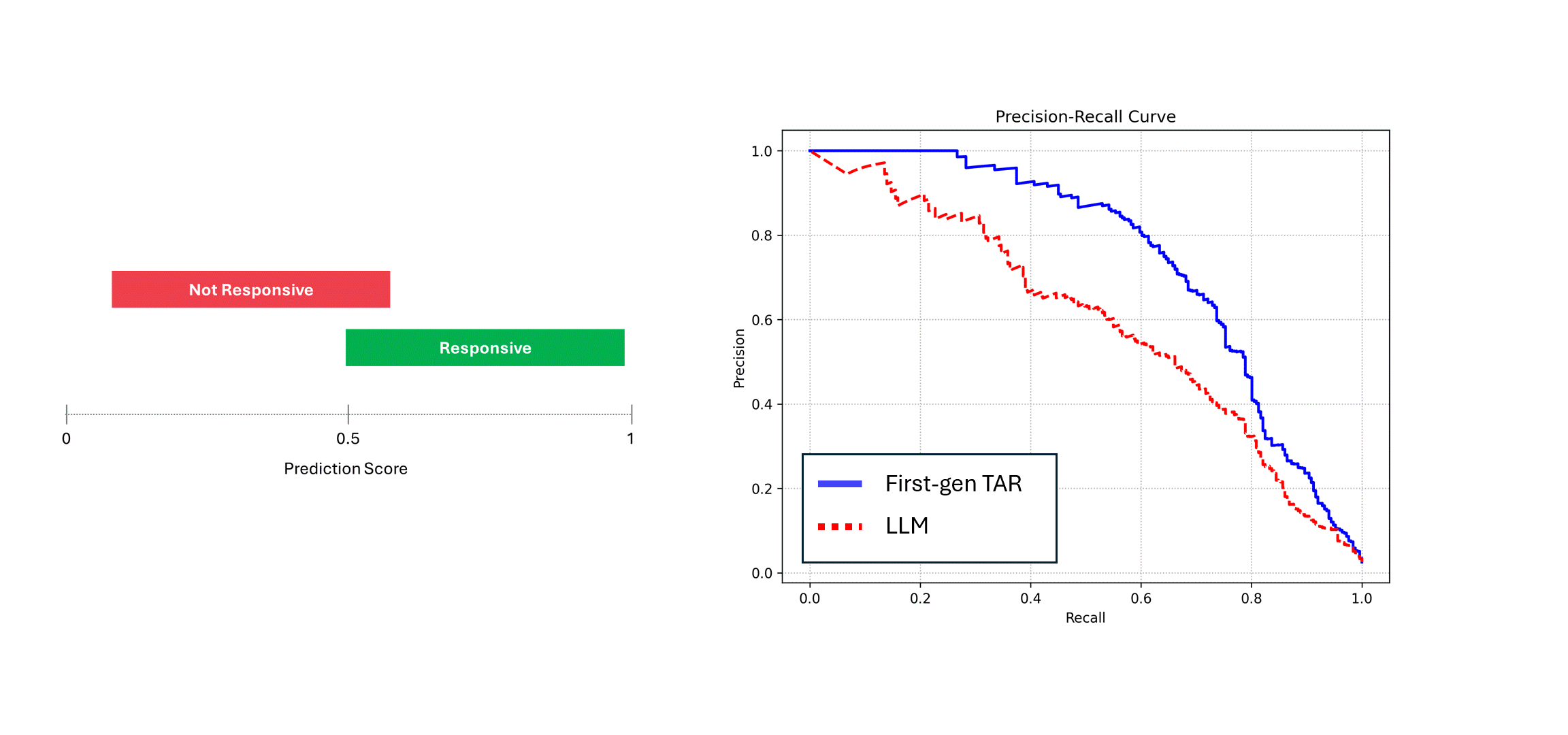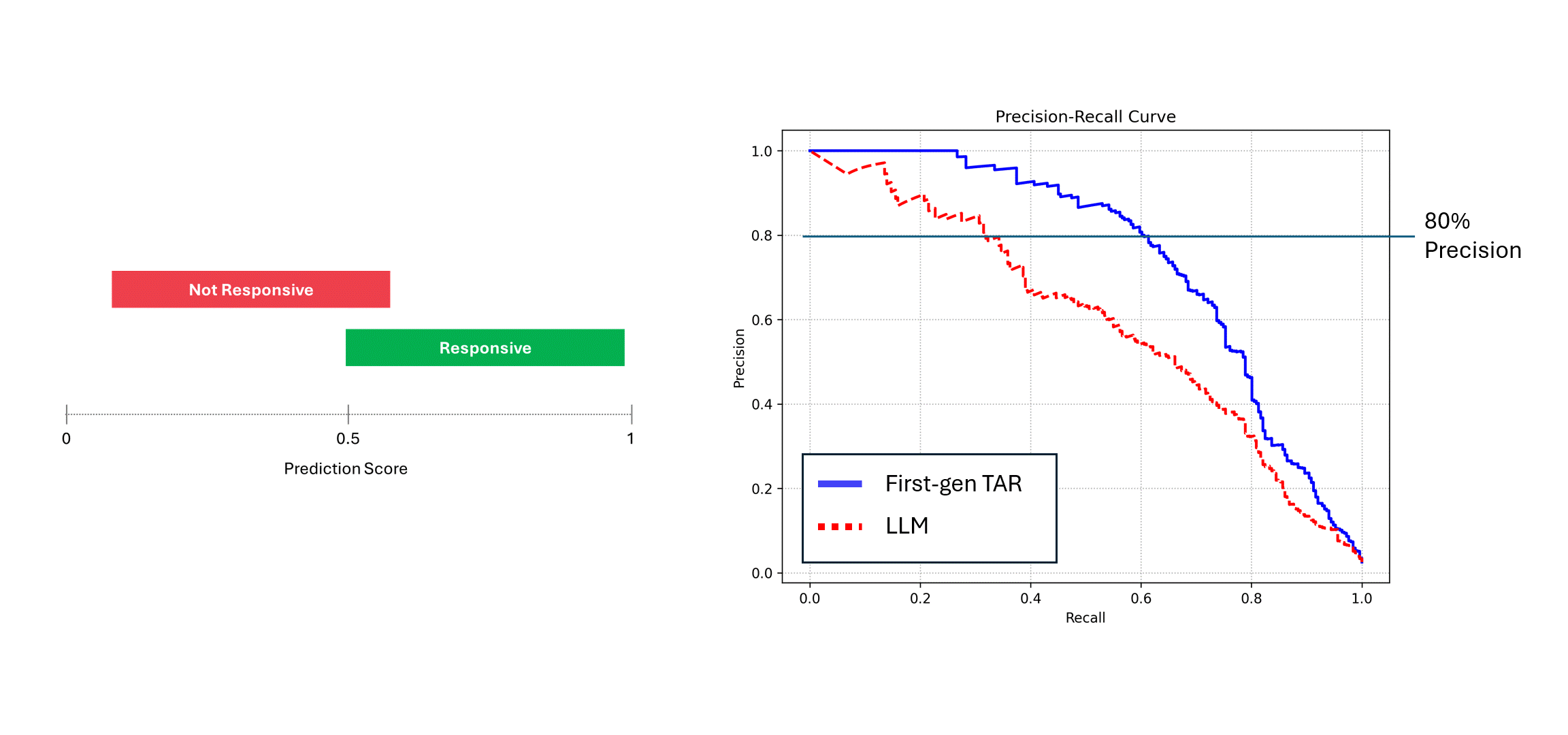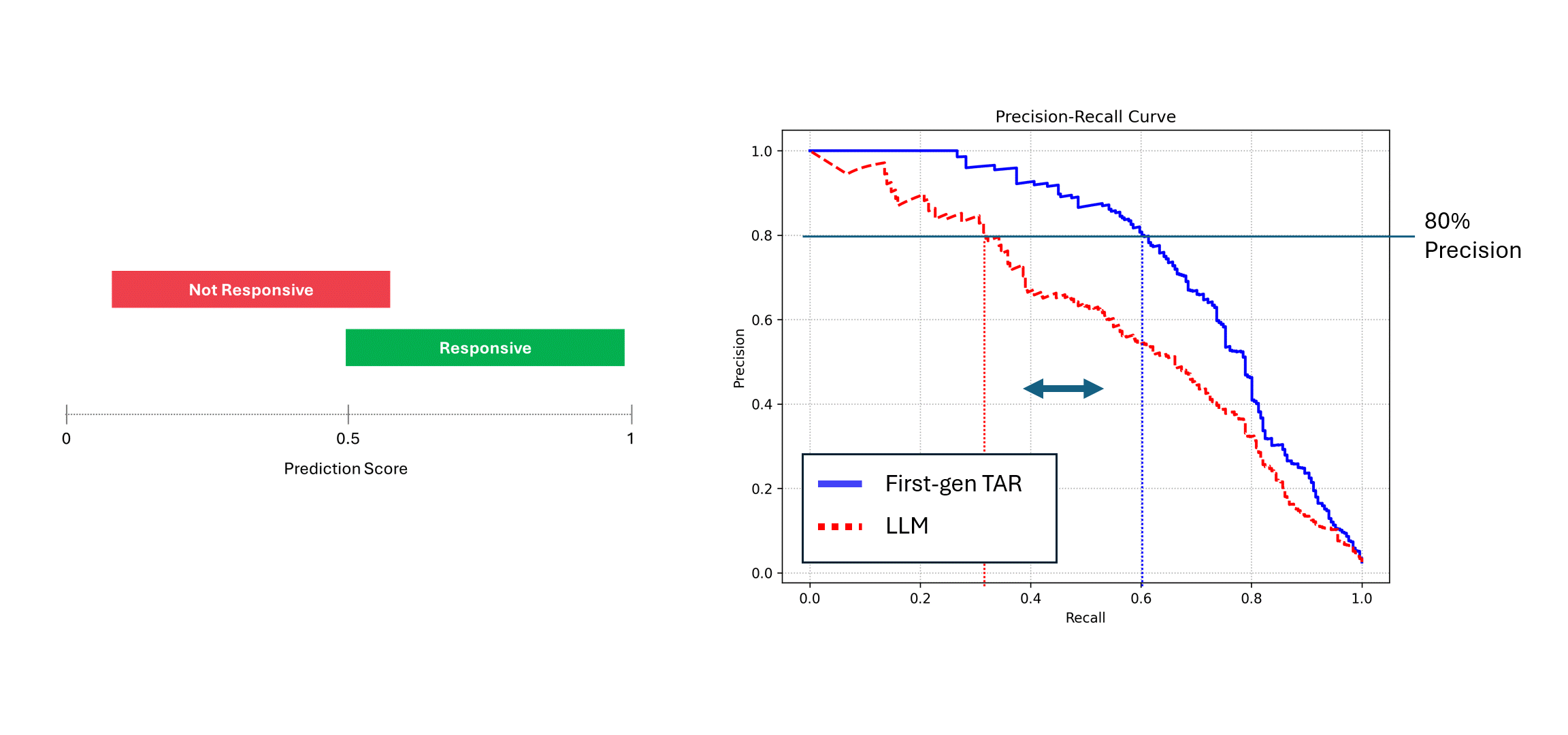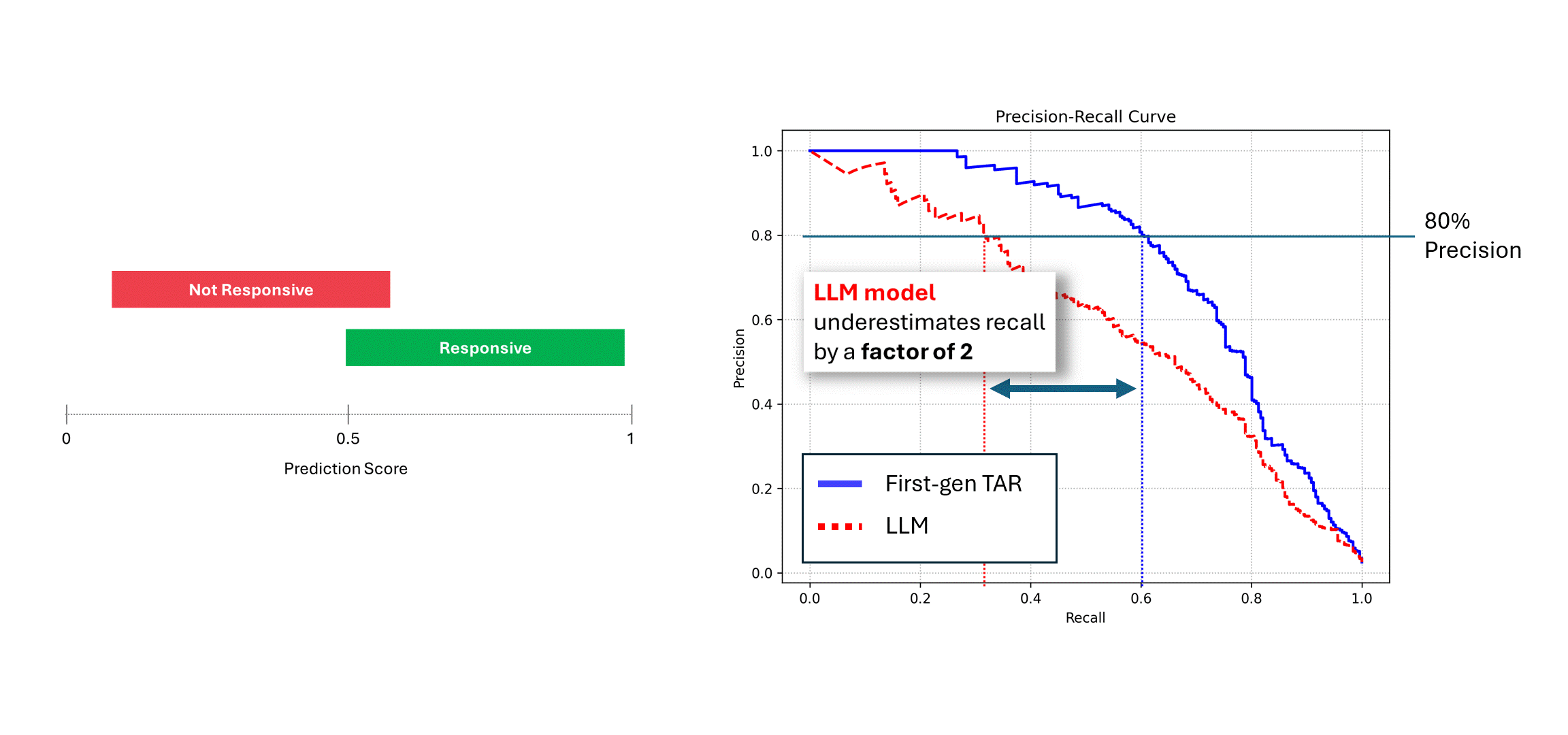
Si le modèle bruyant (c'est-à-dire, un LLM) est exécuté plusieurs fois sur les mêmes données, et ses scores sont moyennés, alors sa précision et son rappel se rapprochent de ceux d'un modèle déterministe, c'est-à-dire, la courbe bleue. Toutefois, si l'on se fie à une seule exécution de ses prédictions (courbe rouge), les performances en pâtissent, car elles sous-estiment toujours les véritables performances du modèle. Dans l'exemple ci-dessus, la performance peut être rapportée à la moitié de ce qu'elle est en réalité.
Quelles sont les implications pratiques ?
Dans la pratique, lorsque vous regardez la courbe Précision-Rappel d'un LLM (la courbe rouge ci-dessus), tout ce que vous verrez est une performance insuffisante, et vous n'en connaîtrez pas la cause. L'instinct est d'améliorer la performance du modèle, peut-être en réglant les invites ou en ajoutant des exemples.
Dans ce cas, tous ces efforts seraient inutiles. L'écart de performance n'est pas dû au fait que le modèle lui-même n'est pas assez bon, mais au fait que sa nature non déterministe sous-estime la performance du modèle. La seule façon de combler cet écart de performance est de demander des scores au LLM plusieurs fois et de faire la moyenne de ses prédictions.
Étant donné que vous n'exécuterez pas votre modèle 10 fois sur chaque document pour des raisons de coût et de temps, existe-t-il des solutions pour s'assurer que la performance du modèle est rapportée avec précision ? La réponse est oui - nous y reviendrons dans notre prochain article de blog. Restez à l'écoute !

Igor Labutov, vice-président, Epiq AI Labs
Igor Labutov est vice-président d'Epiq et codirige Epiq AI Labs. Igor est un informaticien qui s'intéresse particulièrement au développement d'algorithmes d'apprentissage automatique qui apprennent à partir d'une supervision humaine naturelle, telle que le langage naturel. Il a plus de 10 ans d'expérience dans le domaine de l'intelligence artificielle et de l'apprentissage automatique. M. Labutov a obtenu son doctorat à Cornell et a été chercheur post-doctoral à Carnegie Mellon, où il a mené des recherches pionnières à l'intersection de l'intelligence artificielle centrée sur l'homme et de l'apprentissage automatique. Avant de rejoindre Epiq, Labutov a cofondé LAER AI, où il a appliqué ses recherches au développement d'une technologie transformatrice pour l'industrie juridique.
Cet article est destiné à fournir des informations générales et non des conseils ou des avis juridiques.