

.png)
Sécurisez les workflows d’IA avec une protection fondée sur la classification
- eDiscovery
- 1 min
Point clé à retenir: Les organisations qui veulent une IA sûre et fiable doivent démarrer par une classification rigoureuse des données et des contrôles qui protègent à la fois les requêtes et les réponses de l’IA. En s’appuyant sur des étiquettes de sensibilité pour piloter la prévention des pertes de données et les autres contrôles, elles garantissent que les applications d’IA n’utilisent que des données autorisées et que les réponses générées héritent des protections appropriées.
À mesure que les volumes de données augmentent et que l’IA s’intègre aux workflows quotidiens, les organisations doivent mieux maîtriser leurs données pour éviter de nouveaux risques, notamment l’exposition involontaire d’informations.
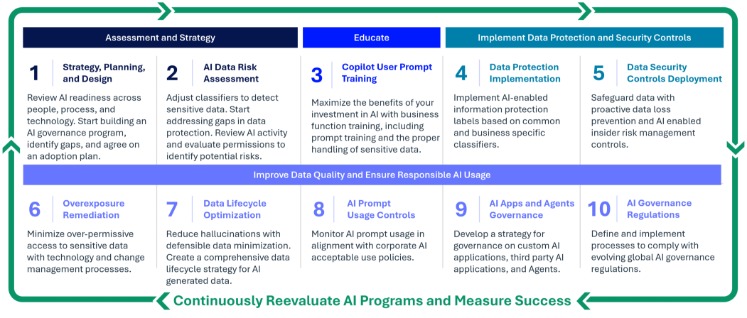
La cinquième étape du Copilot Readiness Framework se concentre sur les contrôles de sécurité des données et transforme la classification d’un simple marquage statique en une protection active. Après avoir posé une base solide à l’étape quatre consacrée à la classification des données, les organisations peuvent désormais convertir les étiquettes de sensibilité en mesures de protection concrètes et applicables. En prolongeant cette logique pilotée par les étiquettes, cette étape fait évoluer l’approche, de l’identification des données sensibles vers le contrôle actif de leur circulation.
Cette étape montre comment la classification devient le moteur de la prévention des pertes de données et garantit que les règles définies précédemment s’appliquent de manière cohérente, aussi bien aux workflows traditionnels qu’aux interactions avec l’IA.
Utiliser la classification pour piloter la prévention des pertes de données
Avec les étiquettes de sensibilité et les classificateurs solidement en place depuis l’étape quatre, vous disposez d’une couche d’intelligence capable d’identifier de manière fiable les contenus sensibles dans l’ensemble de l’environnement. La prévention des pertes de données garantit que les protections accompagnent les données partout où elles circulent, y compris dans les interactions avec l’IA. Les mécanismes DLP traditionnels protègent déjà les données en mouvement dans les emails, le stockage cloud et les outils collaboratifs.
La classification renforce la DLP en alignant l’application des contrôles sur votre taxonomie d’étiquettes et en transformant ces étiquettes en règles qui déclenchent des alertes, des justifications ou des blocages. Comme l’IA peut interagir avec toutes les données auxquelles un utilisateur ou un agent est autorisé à accéder, leur protection devient encore plus critique. La DLP appliquée à l’IA repose sur la même logique pour sécuriser à la fois la requête soumise par l’utilisateur et la réponse générée lors des interactions avec l’IA.
Par exemple, une DLP traditionnelle peut bloquer l’envoi d’un email contenant des numéros de carte bancaire ou exiger une justification de l’utilisateur. De même, si une personne tente de téléverser un tableur contenant des données à caractère personnel, des données de santé protégées ou des informations métier confidentielles vers une application personnelle, la DLP peut interrompre l’action et afficher un message de politique qui encourage des pratiques plus sûres.
Dans les workflows d’IA, des requêtes étiquetées Confidentiel ou Restreint peuvent déclencher des alertes DLP, des demandes de justification ou des blocages. Si une réponse d’IA expose des données protégées, la DLP peut empêcher la copie, le téléchargement ou le partage, en appliquant à l’IA les mêmes protections que pour les workflows traditionnels. Une fois les données classifiées de manière cohérente, la DLP devient le mécanisme qui fait respecter ces classifications dans les applications traditionnelles comme dans les applications d’IA.
Bonnes pratiques pour le déploiement de la prévention des pertes de données
Une fois la classification en place, le déploiement de la DLP nécessite une approche réfléchie qui équilibre protection et productivité. Ces bonnes pratiques aident les équipes à mettre en œuvre les contrôles de manière structurée et à faible risque, à renforcer la sensibilisation des utilisateurs, à aligner l’application des règles sur les besoins métiers réels et à garantir que les protections s’étendent de façon cohérente aux workflows traditionnels comme aux interactions avec l’IA.
Commencer par la visibilité en mode audit
En mode audit, vous activez le suivi pour comprendre les comportements, les flux d’information et les zones de risque. Cette visibilité précède toute application de règles et permet de s’assurer que les futures politiques ne perturbent pas la productivité.
Application progressive des contrôles
L’application progressive introduit les contrôles par étapes afin de laisser aux équipes le temps d’apprendre, de s’adapter et de renforcer la sensibilisation des utilisateurs avant tout blocage. Elle commence par l’information, puis demande une justification en cas de comportement à risque, et n’impose des blocages qu’une fois l’impact compris et validé.
Aligner les contrôles sur les exigences réglementaires et les besoins métiers
Chaque secteur impose des contrôles spécifiques. Dans les services financiers, les organisations doivent identifier et protéger les dossiers de transaction, les informations financières ou les données clients. Dans le secteur de la santé, les équipes doivent détecter les données de santé protégées dans les requêtes adressées à des outils d’IA non autorisés et n’autoriser Copilot que lorsque les données sont masquées et que les accès sont strictement limités. En alignant ces contrôles sur les obligations réglementaires, les organisations favorisent un usage de l’IA conforme et maîtrisé.
Impliquer les parties prenantes dès le depart
Associer très tôt les équipes juridiques, conformité, sécurité et les responsables métiers permet de définir des politiques alignées sur les workflows réels. Leur contribution aide à concevoir des règles adaptées aux modes de travail, à limiter les résistances et à éviter toute surprise lors de l’application des contrôles.
Considérer les politiques comme des contrôles évolutifs
Une gouvernance efficace de l’IA ne se définit pas une seule fois. Elle évolue avec les nouveaux risques et les modes de travail. Les équipes doivent analyser les tendances de violation, recueillir les retours des utilisateurs et surveiller les nouveaux comportements de l’IA susceptibles d’introduire des risques. Ces enseignements orientent l’ajustement des contrôles et garantissent un alignement durable des politiques.
Protéger les appareils avec la prévention des pertes de données au niveau des postes
Toutes les données ne naissent pas dans le cloud et n’y restent pas. La DLP au niveau des postes étend les protections fondées sur la classification aux appareils des utilisateurs et offre aux équipes visibilité et contrôle. Cela couvre des situations comme la copie de réponses d’IA sur des clés USB, le téléversement de jeux de données sensibles vers des outils d’IA externes, ou encore l’impression et la capture d’écran de réponses protégées. Les informations sensibles restent gouvernées à chaque interaction, même lorsque les collaborateurs utilisent des outils d’IA en dehors du cloud. La classification et la DLP permettent aux organisations d’exploiter l’IA en toute confiance tout en bloquant les usages à risque.
Étendre la protection avec la gestion des risques internes
La DLP protège les données sensibles en circulation, tandis que la gestion des risques internes permet de détecter et de traiter des comportements à risque qui ne déclenchent pas toujours des violations de règles classiques mais signalent néanmoins une exposition accrue. Elle s’appuie sur des indicateurs comme des schémas d’accès inhabituels, des téléchargements massifs, des tentatives d’exfiltration ou des activités utilisateur à haut risque afin d’identifier rapidement les menaces émergentes. Cette capacité est particulièrement critique lorsque l’IA accélère la vitesse et le volume des interactions avec les données.
En combinant une DLP pilotée par les étiquettes avec les enseignements issus de la gestion des risques internes, les organisations obtiennent une vision plus complète de la circulation des informations sensibles et des zones où des risques internes peuvent émerger. Cette approche unifiée renforce la gouvernance, soutient les obligations de conformité et garantit que les contrôles évoluent au rythme d’un environnement de travail dopé à l’IA.
Ensemble, la DLP, les contrôles au niveau des postes et la gestion des risques internes constituent une défense en profondeur qui consolide cette étape du Copilot Readiness Framework et assure la protection des informations sensibles, quel que soit le mode d’interaction des utilisateurs ou des systèmes d’IA.
Conclusion pour des workflows d’IA sécurisés
Adopter l’IA de manière responsable repose sur des fondamentaux solides. Classifiez les données de façon cohérente et laissez ces étiquettes piloter l’application des contrôles au sein de la protection des informations, de la prévention des pertes de données et des outils de gouvernance élargis. Vous créez ainsi un environnement où l’IA fonctionne de manière sûre par conception, sans dépendre de contrôles manuels ni de revues a posteriori.
Innovez avec l’IA tout en respectant les exigences réglementaires, contractuelles et éthiques. Renforcez votre capacité à faire de l’IA un levier de transformation, soutenu par des contrôles qui protègent vos informations les plus sensibles.
Pour en savoir plus sur l’IA responsable et la préparation à Copilot.

Manikandadevan Manokaran, consultant senior en sécurité des données
Consultant senior en sécurité des données chez Epiq, Manikandadevan, dit Mani, accompagne les organisations dans l’adoption de Purview AI afin de renforcer la sécurité, la conformité et la protection des données. Consultant résolument orienté client, il cumule plus de seize ans d’expérience sur les technologies Microsoft. Il est spécialisé dans la migration vers le cloud, la sécurité et la conformité. Mani est animé par une forte passion pour aider les organisations à moderniser leurs environnements de données grâce à des solutions d’IA intelligentes.

Paul Renehan, vice-président conseil
Dirigeant expérimenté, Paul Renehan cumule plus de vingt ans d’expérience en gouvernance des données, protection de l’information et eDiscovery, avec un accent croissant sur la préparation des organisations aux exigences accélérées de l’intelligence artificielle. En tant que vice-président conseil, il dirige une équipe de spécialistes chargés de moderniser les stratégies de gouvernance et de protection des données à l’échelle de l’entreprise, afin de garantir des écosystèmes d’information sécurisés, conformes, prêts pour l’IA et capables de générer de la valeur métier.
Cet article est destiné à fournir des informations générales et non des conseils ou des avis juridiques.