

Angle

LLMとの信頼性スコアが危険な理由
LLMからの信頼度評価に関しては、予測スコアが不可欠である。最も重要なのはスコアそのものではなく、これらのスコアが結果として生み出すランキングである。
我々のモデル(TAR 1.0、TAR 2.0、CAL、LLM)がスコアを出したら、我々は例をランク付けし、カットオフラインを引く:

私たちは、モデルが「レスポンシブ」と呼ぶものと「レスポンシブでない」と呼ぶものに線を引いて分けることにより、各文書のレスポンシブを決定します。その結果、偽陽性や偽陰性などのエラーが発生することがあります。
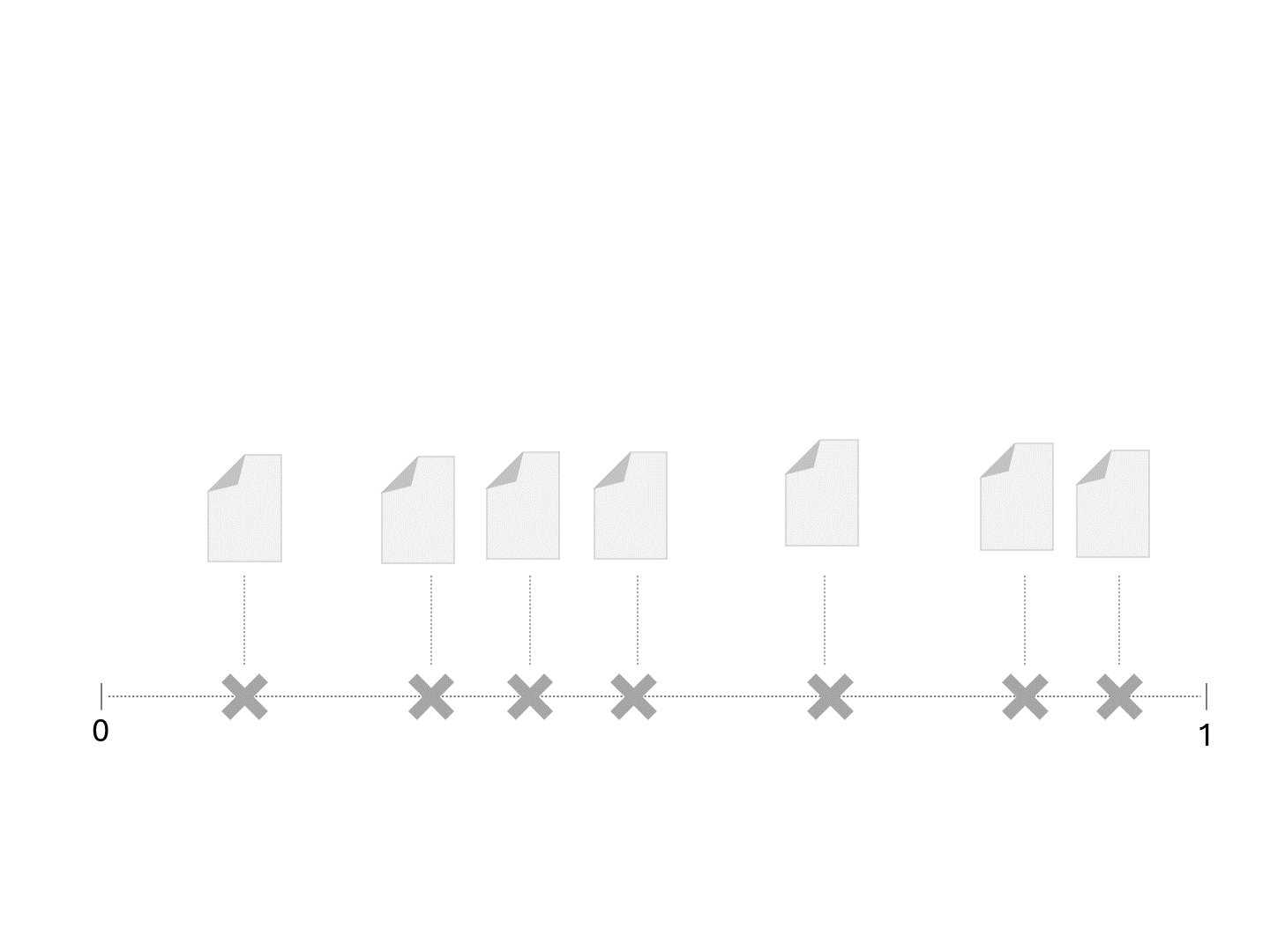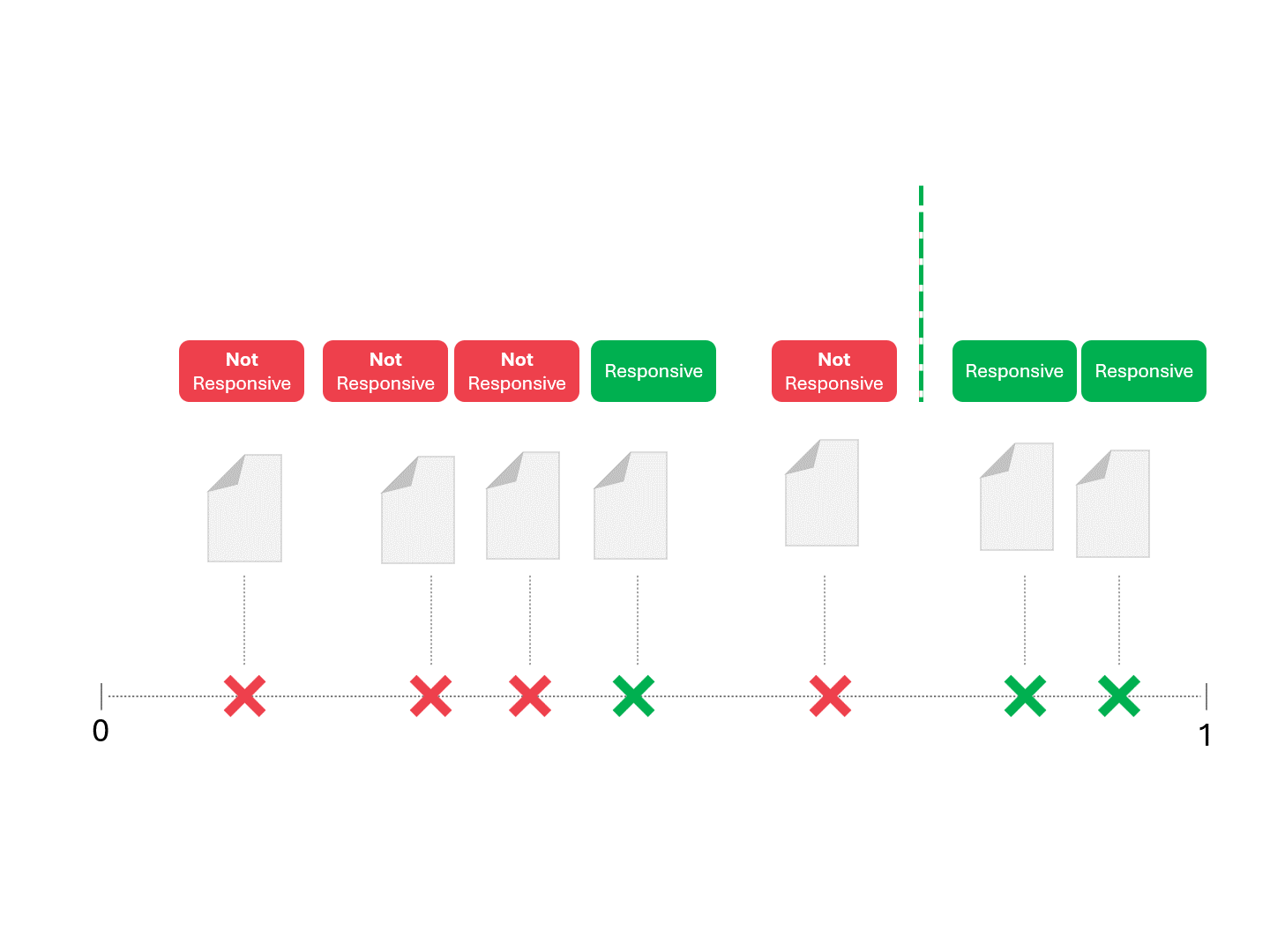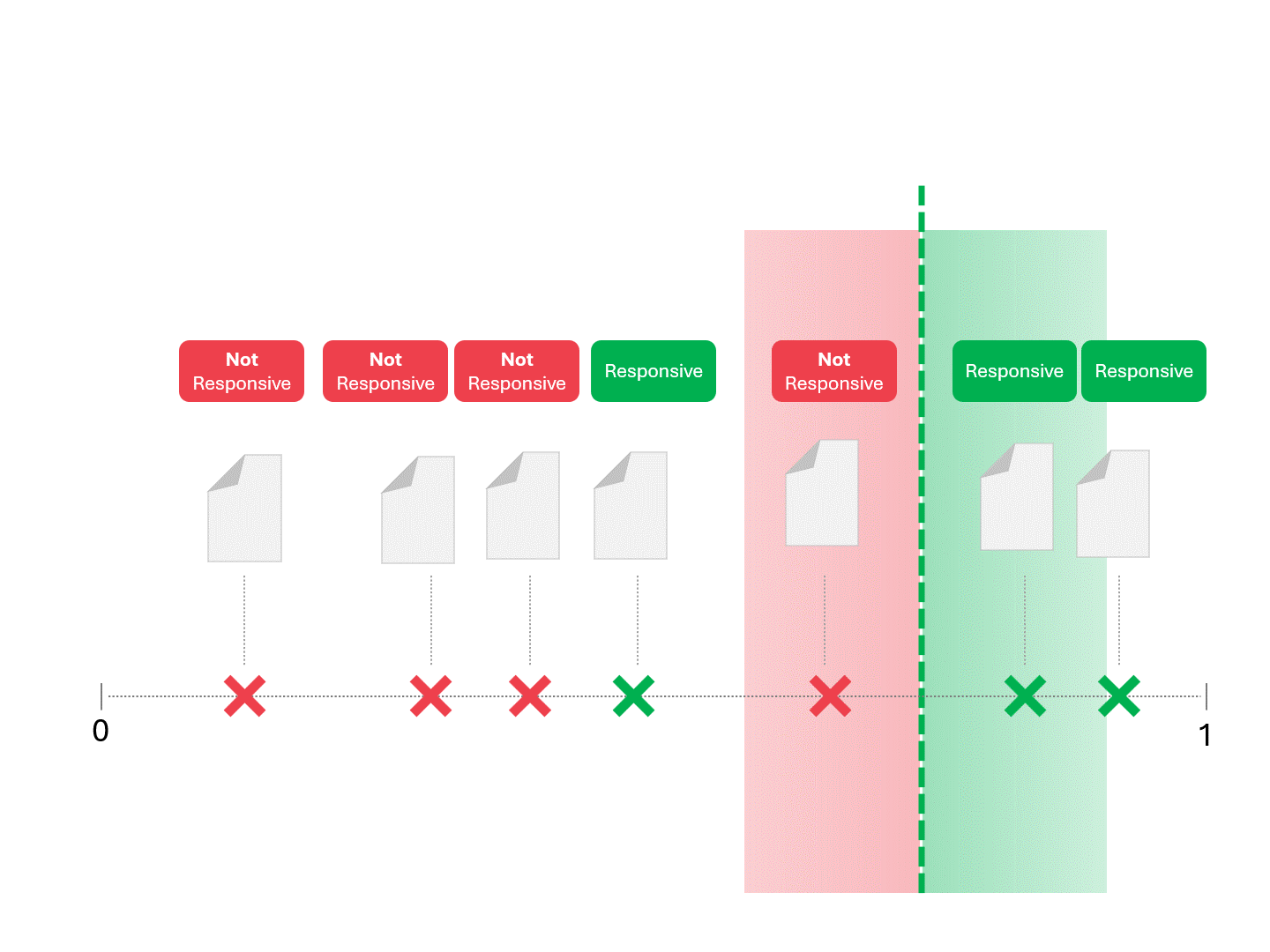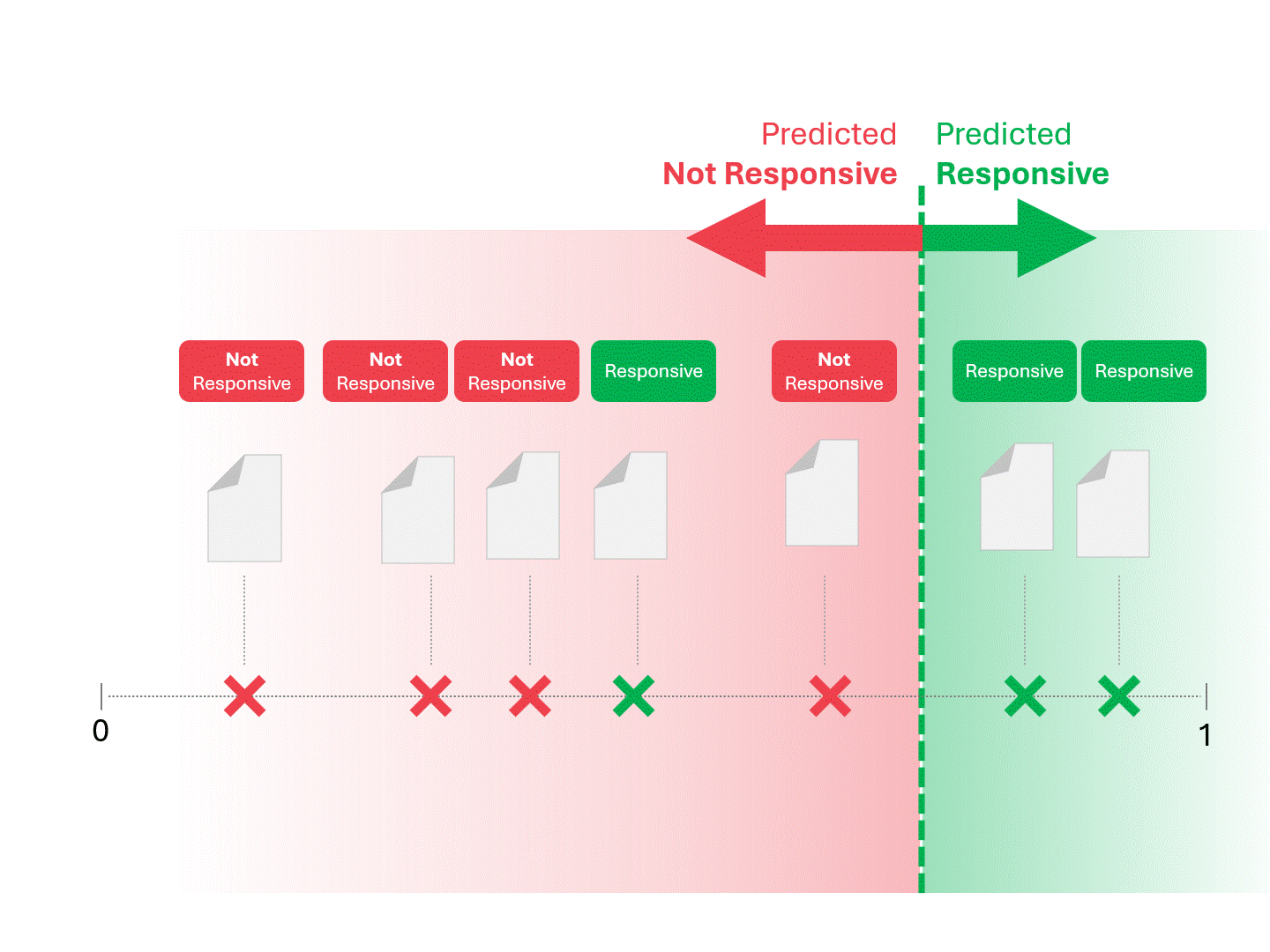
スコアリングのしきい値を変えると、異なる結果とエラー率が得られる。例えば、包括的であれば偽陽性が増えるかもしれないが、偽陰性を見逃すことは少なくなる。正解はなく、価値判断となる。
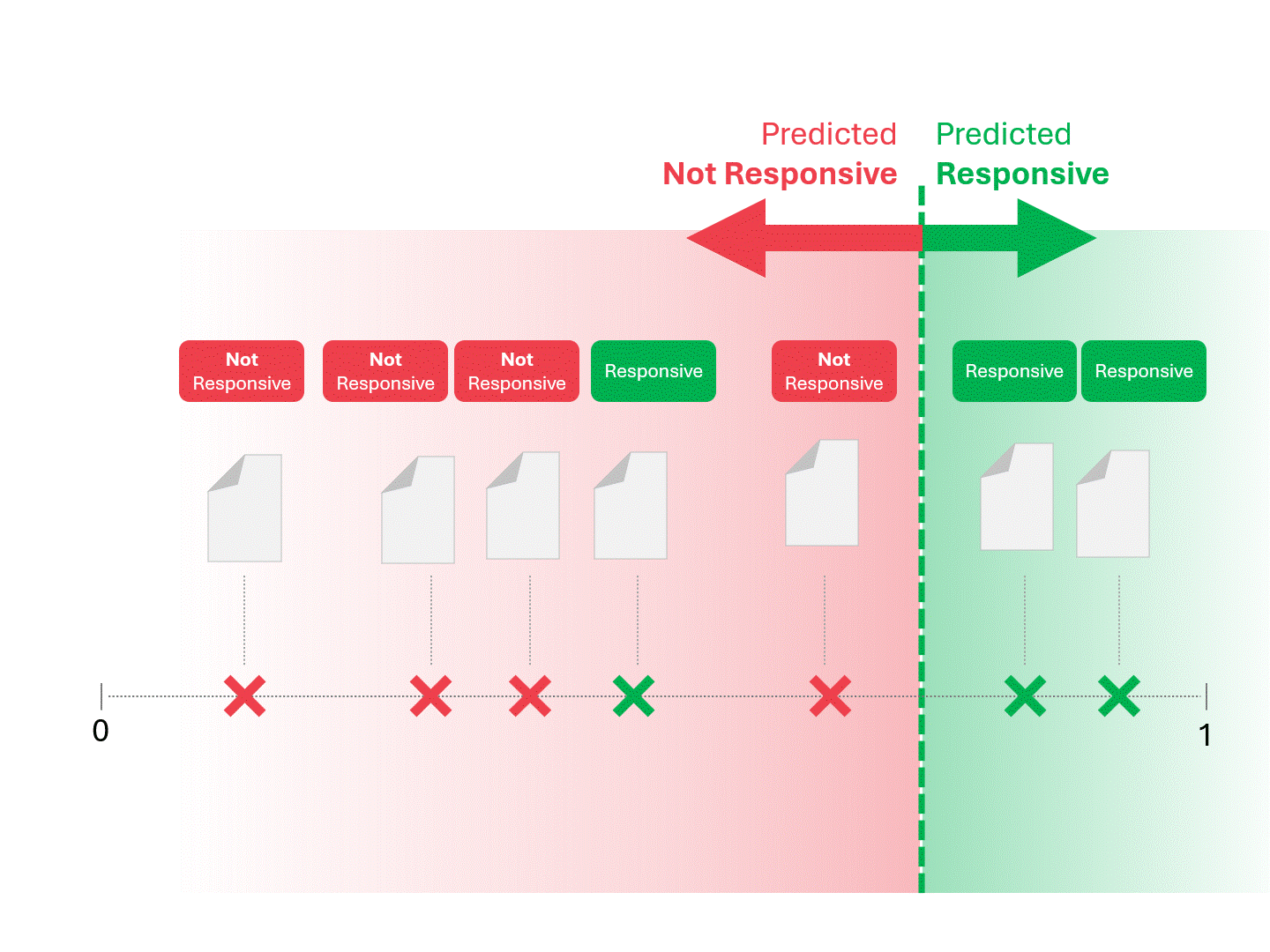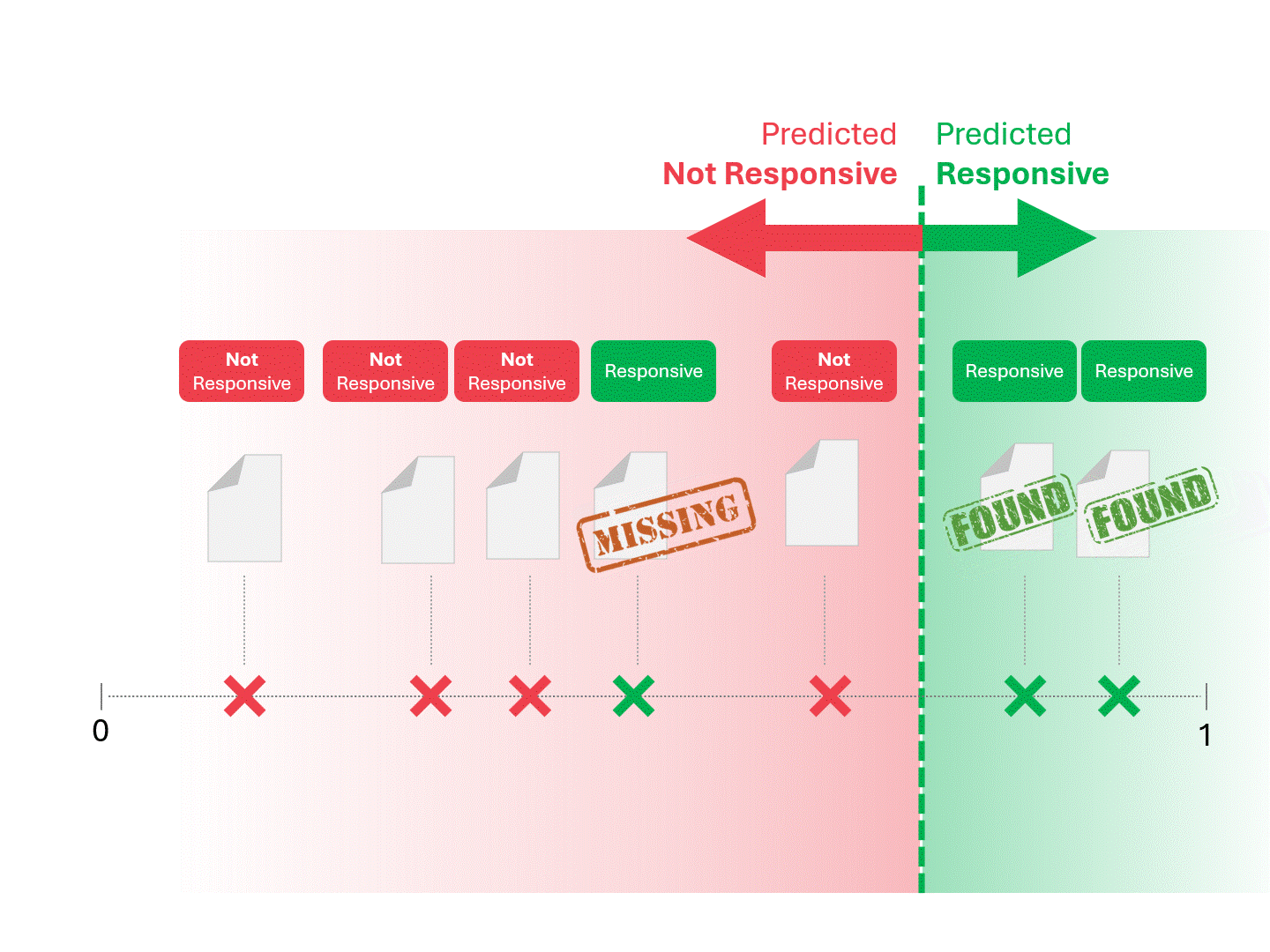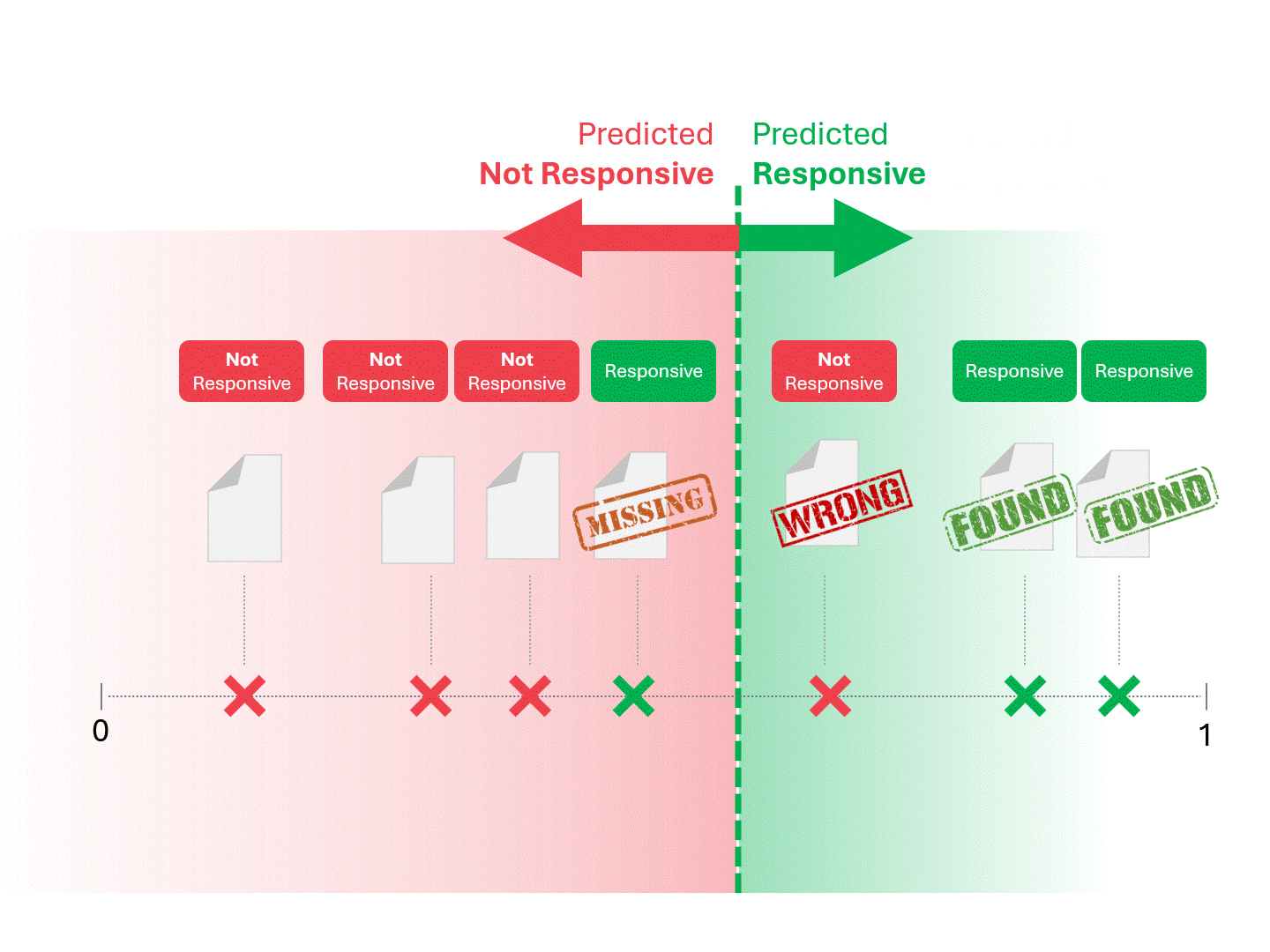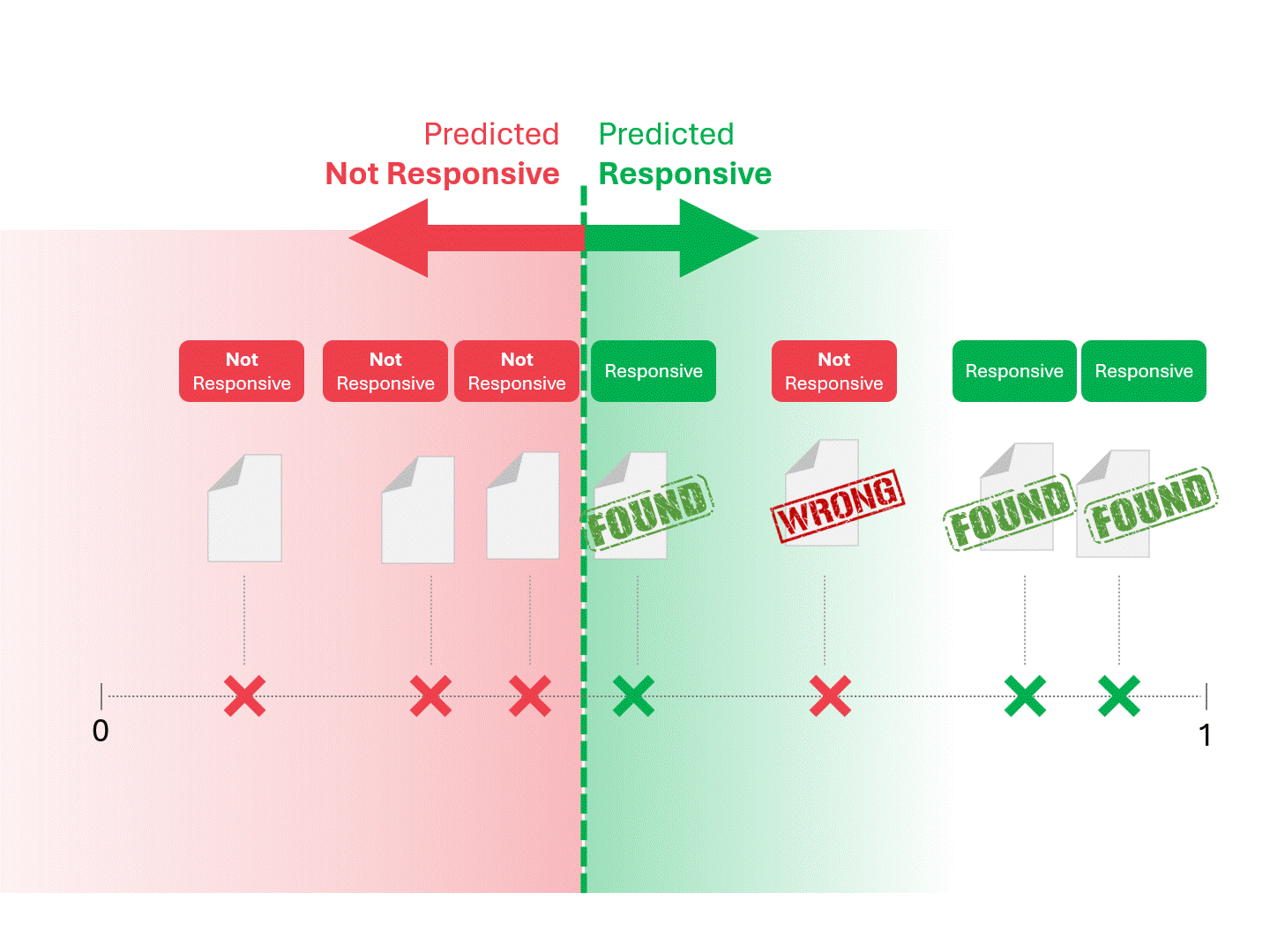
上記のプロセスは、TARが存在する限り標準的なものである。モデルが何らかのスコアを出す限り、上記の方法で予測を行うことができる。
TARモデルとLLMの唯一の違いは、LLMから得られるスコアは決定論的ではないということです。全く同じデータに対して同じモデルを繰り返し実行すれば、異なるスコアが得られ、したがって異なる順位が得られる。
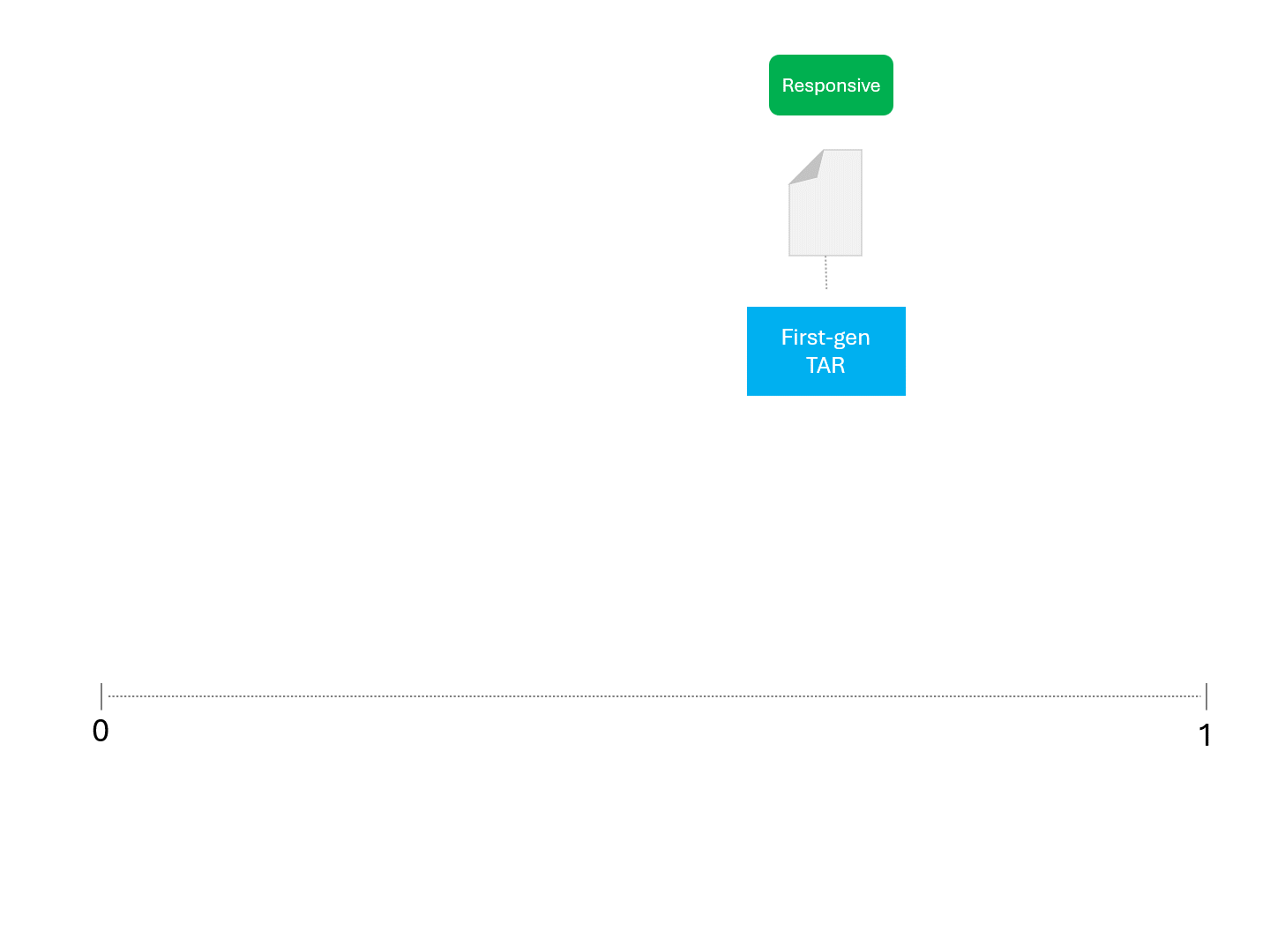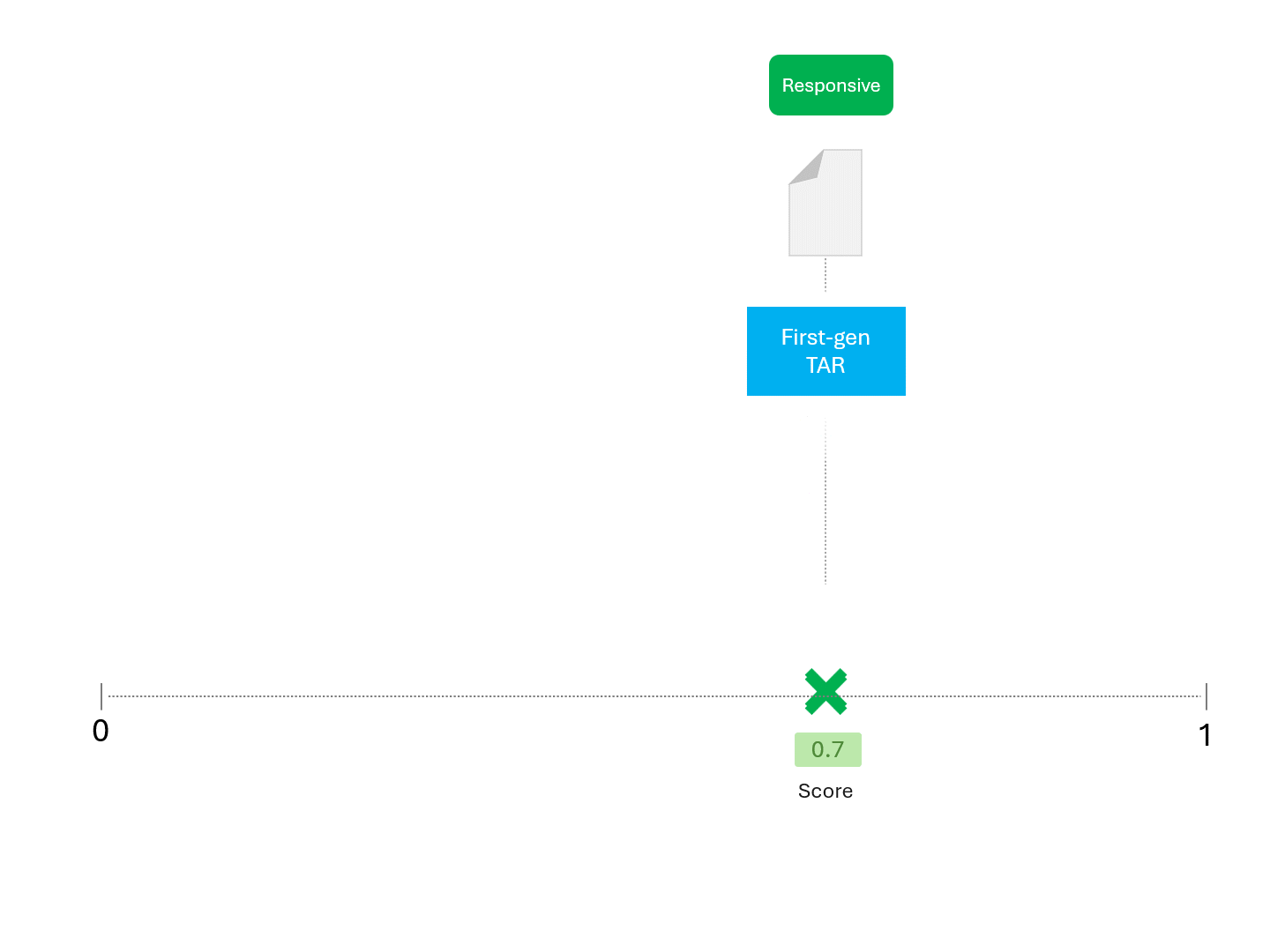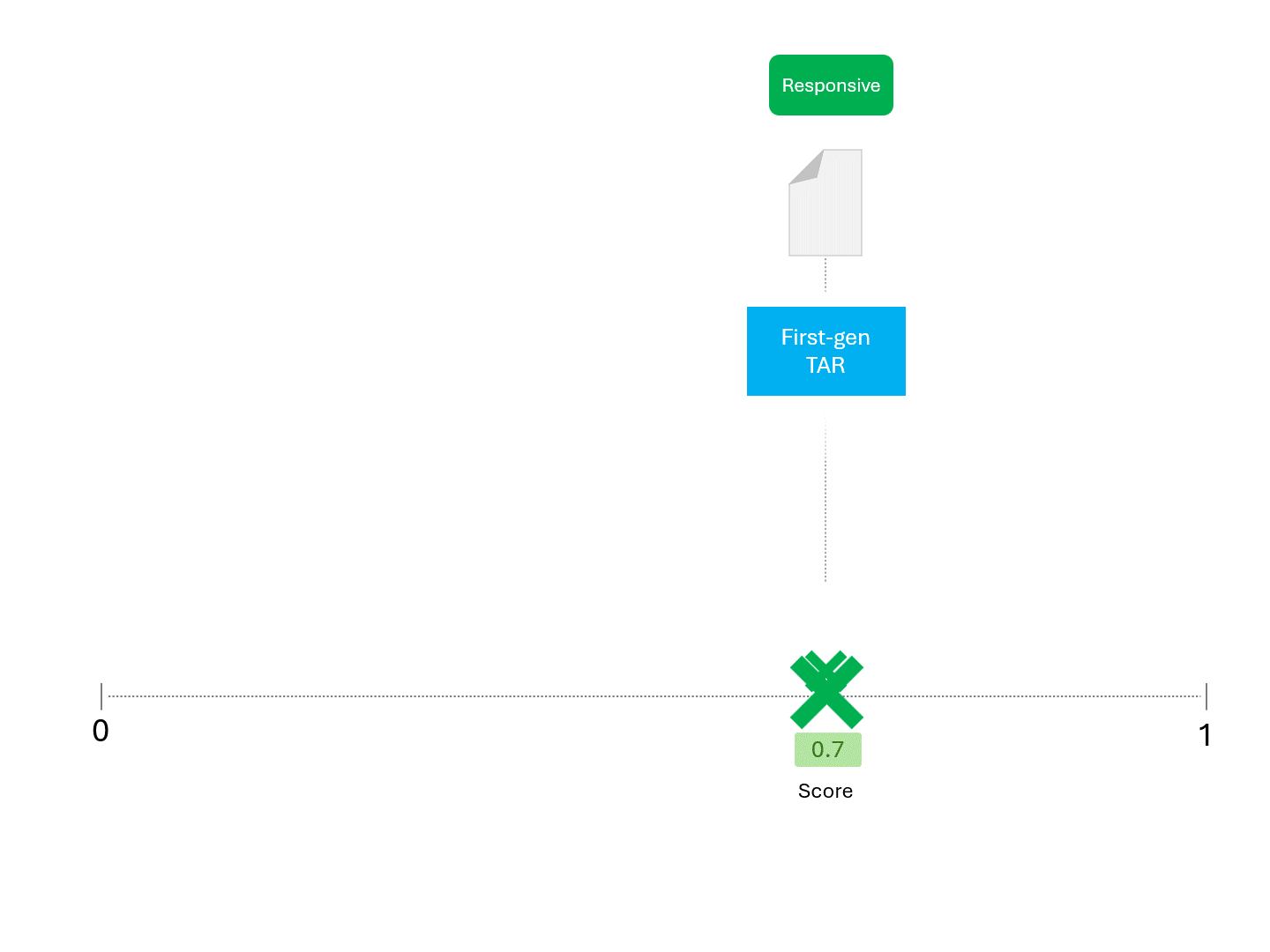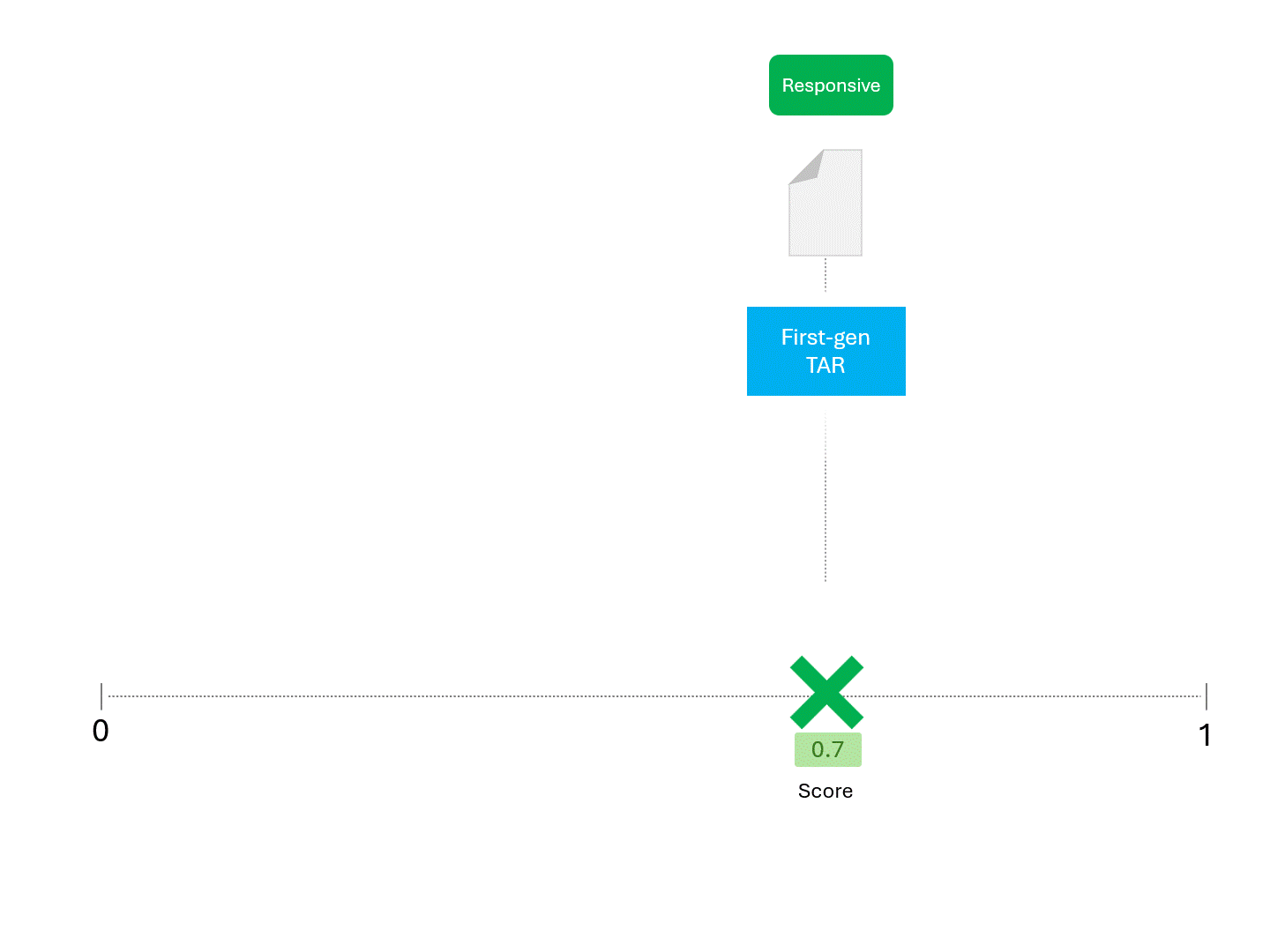
例えば、TARモデルに繰り返しスコアを求める場合、次のようなことが予想される:
一方、LLMにスコアを求めると次のようになる:
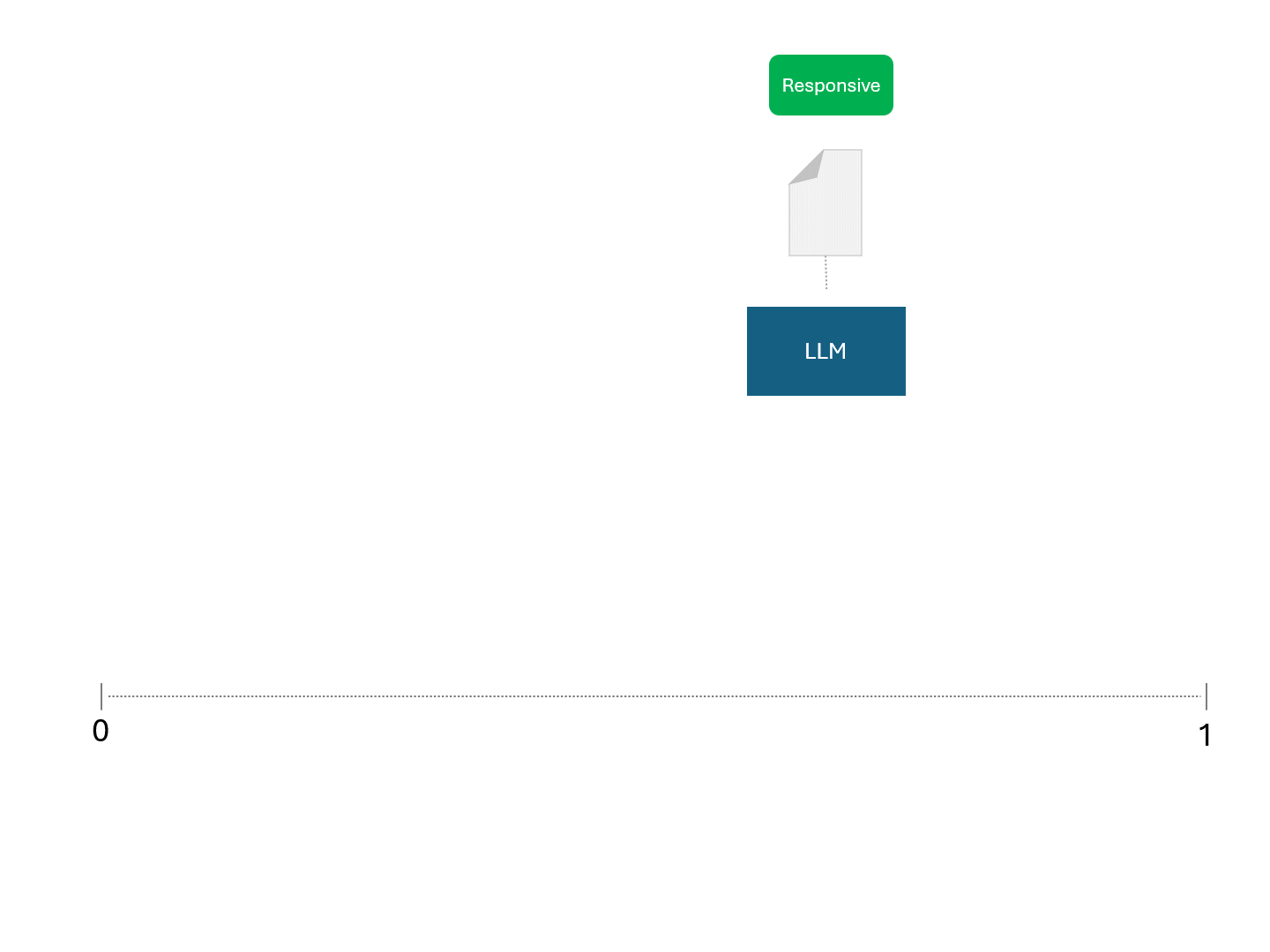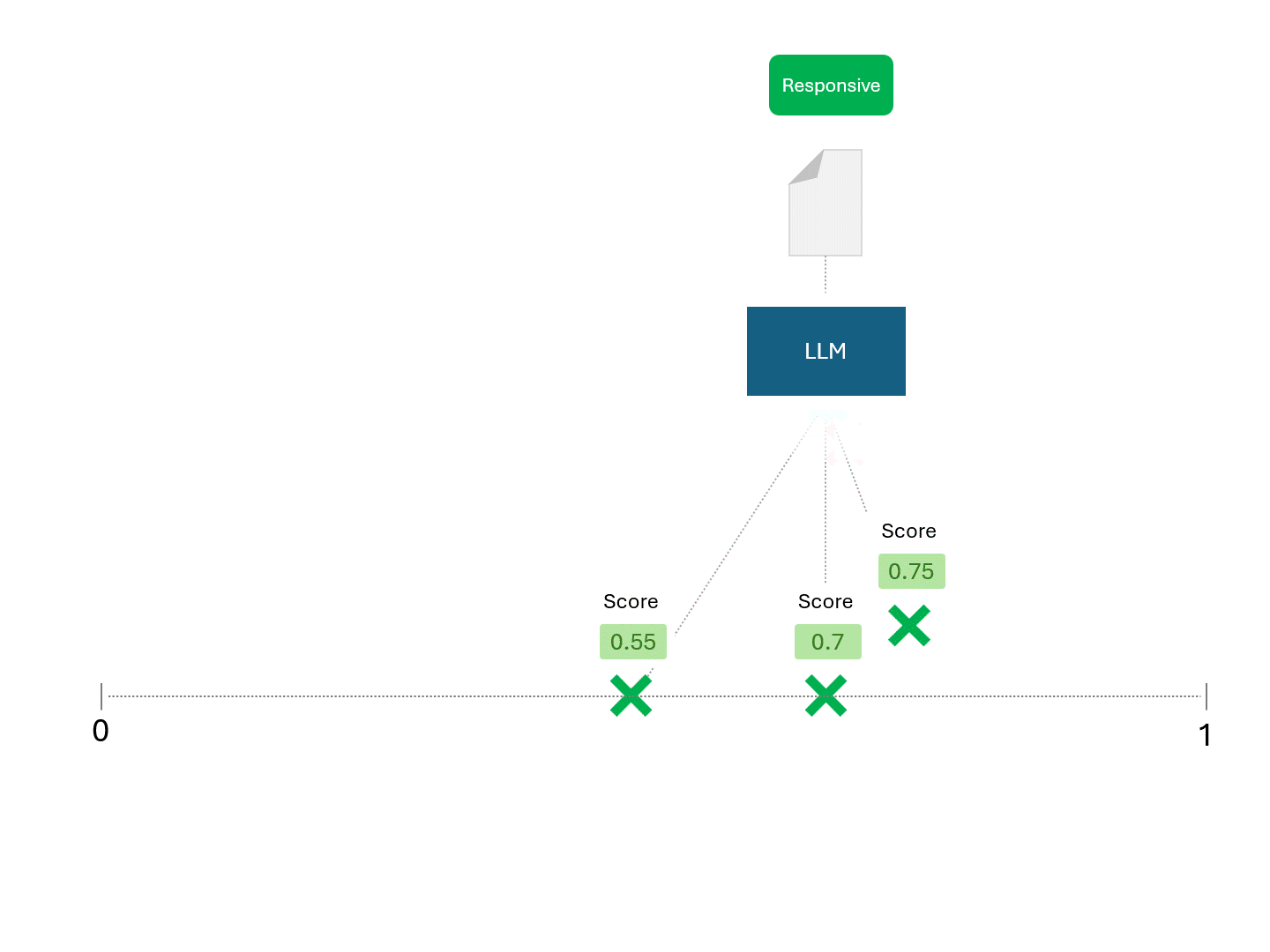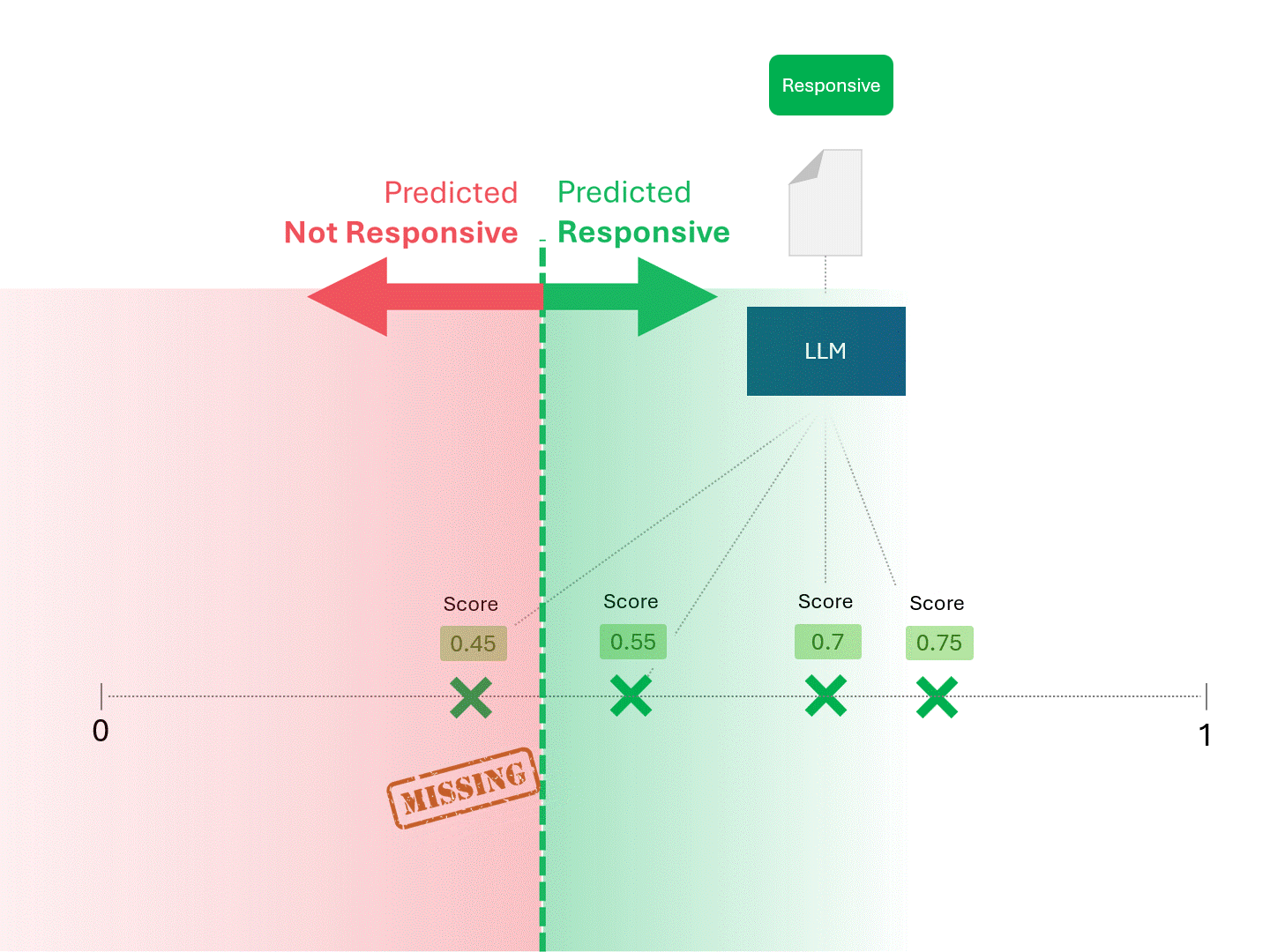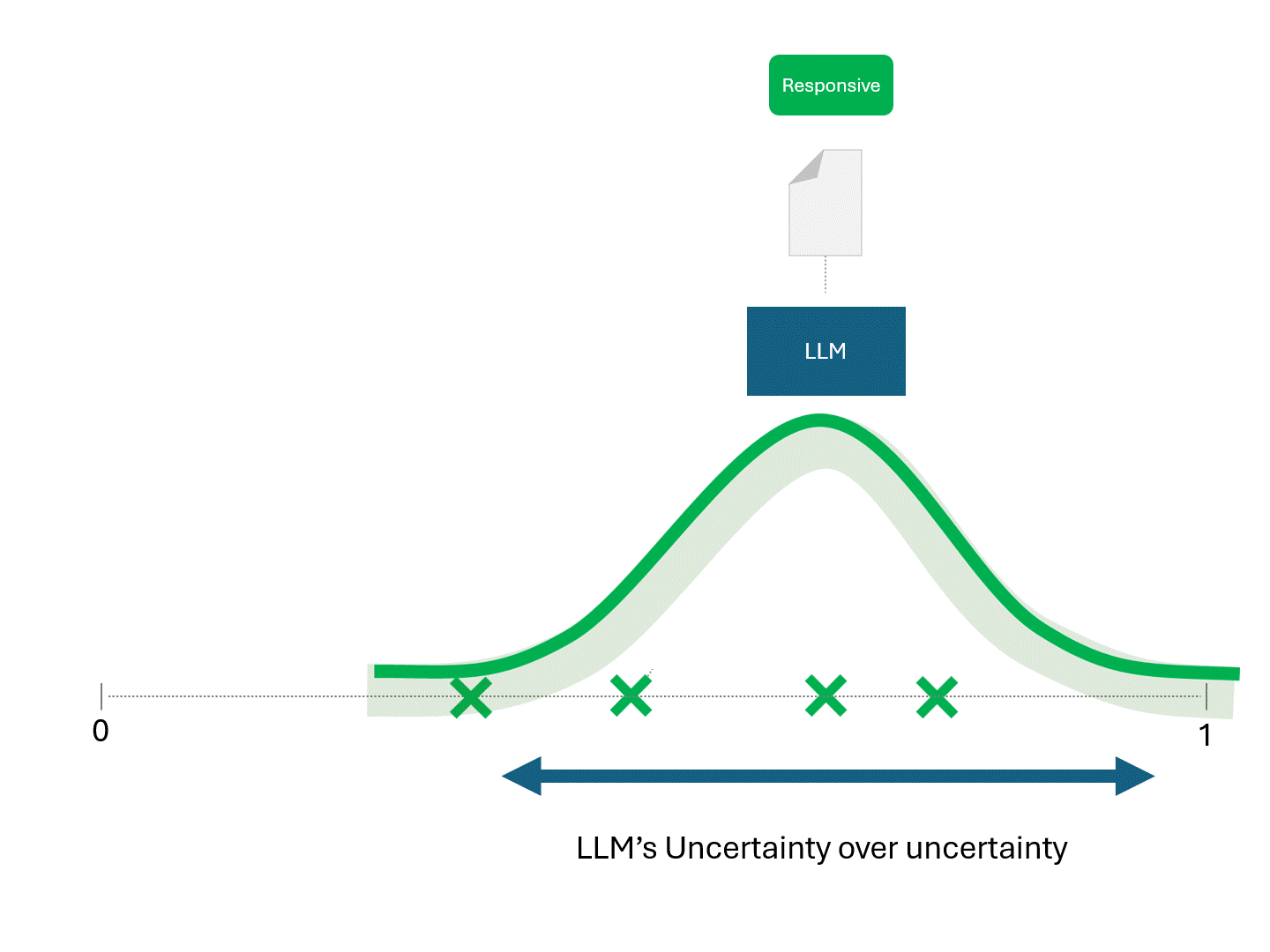
スコアが異なれば順位も異なるため、LLMに予測を依頼するたびに、再現率や精度といったパフォーマンス指標も異なることが予想される。
解決策は?
モデルの予測の一貫性を高める唯一の方法は、予測自体かスコアのどちらかを平均化することであると前述しました。例えば、LLMに同じ文書のスコアを繰り返し問い合わせ、その結果を平均化する方法です。十分なクエリーがあれば、平均は真の予測スコアに収束して安定し、従来のモデルのように決定論的なものに近づくだろう。
この方法の問題点は、LLMへのクエリーを何度も繰り返すことが現実的でないことで、特にGPT-4のようなものではコストが法外にかかることが多い。
その結果どうなるか?
LLMの信頼度出力をそのまま信頼するとどうなるか見てみましょう。
結果を説明するために、決定論的モデルとLLMのように予測にノイズを加えたモデルのPrecision-Recall曲線を比較します。
これをシミュレートするために、仮想的なスコアのセットを取り、それにノイズを加えます。そしてPrecision-Recall曲線を比較する:
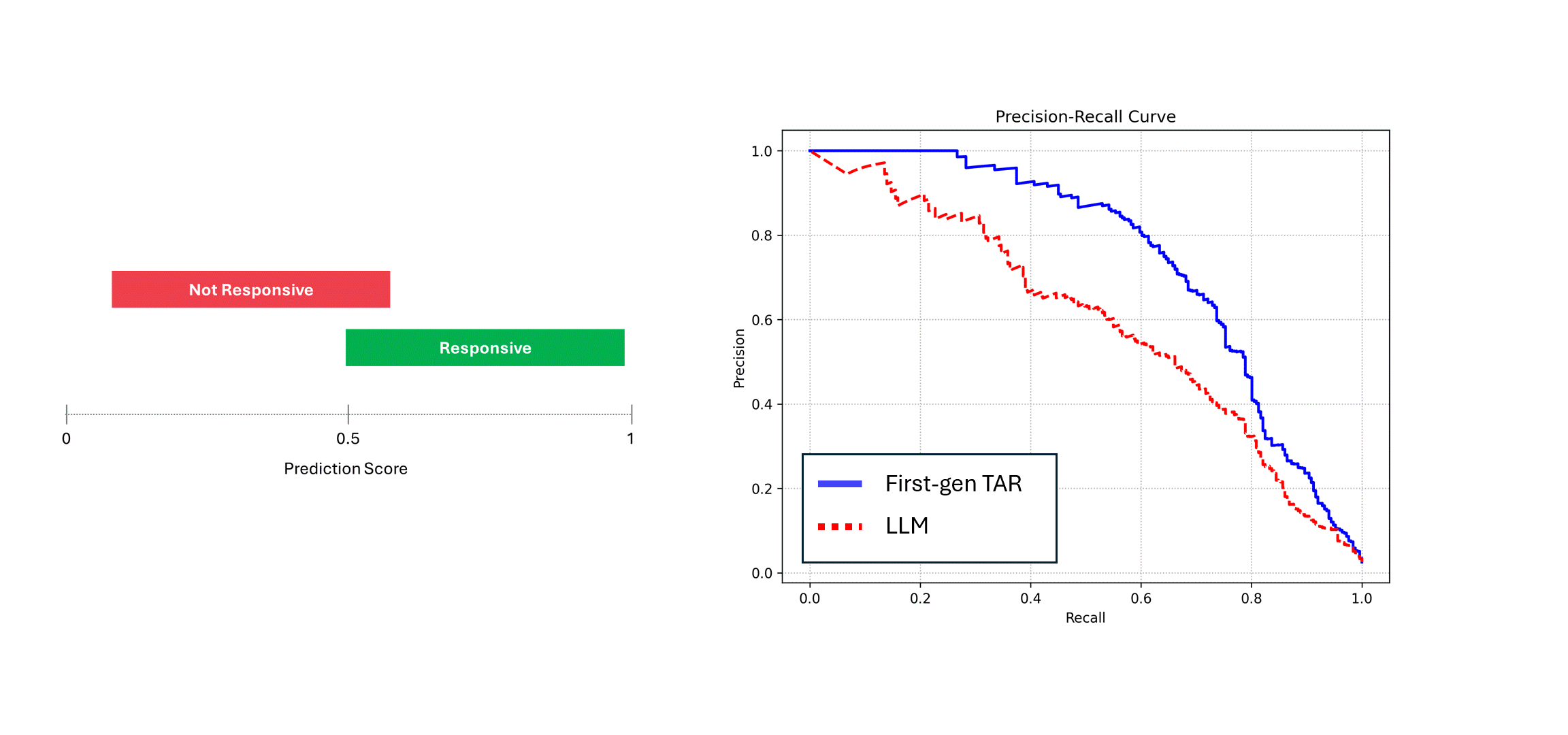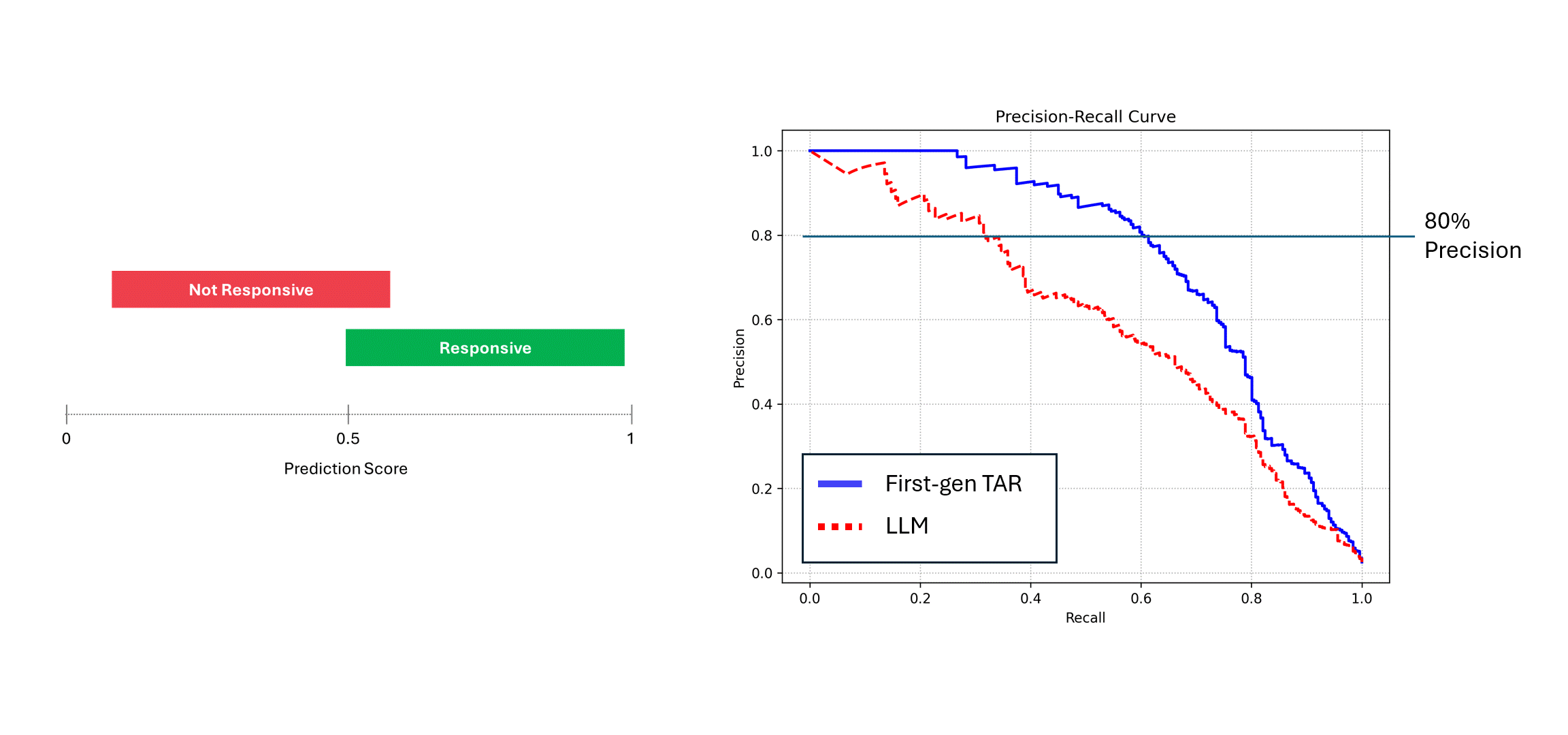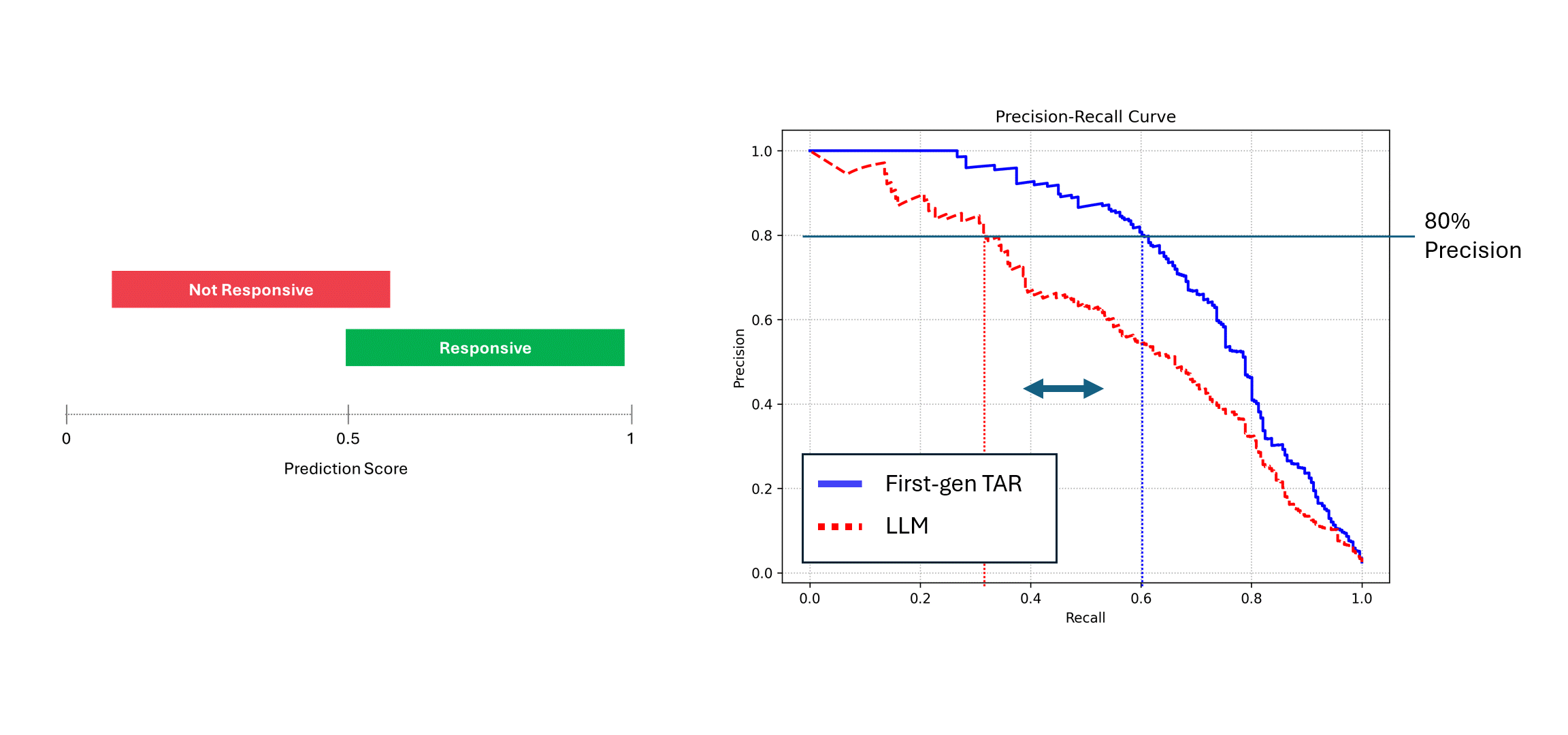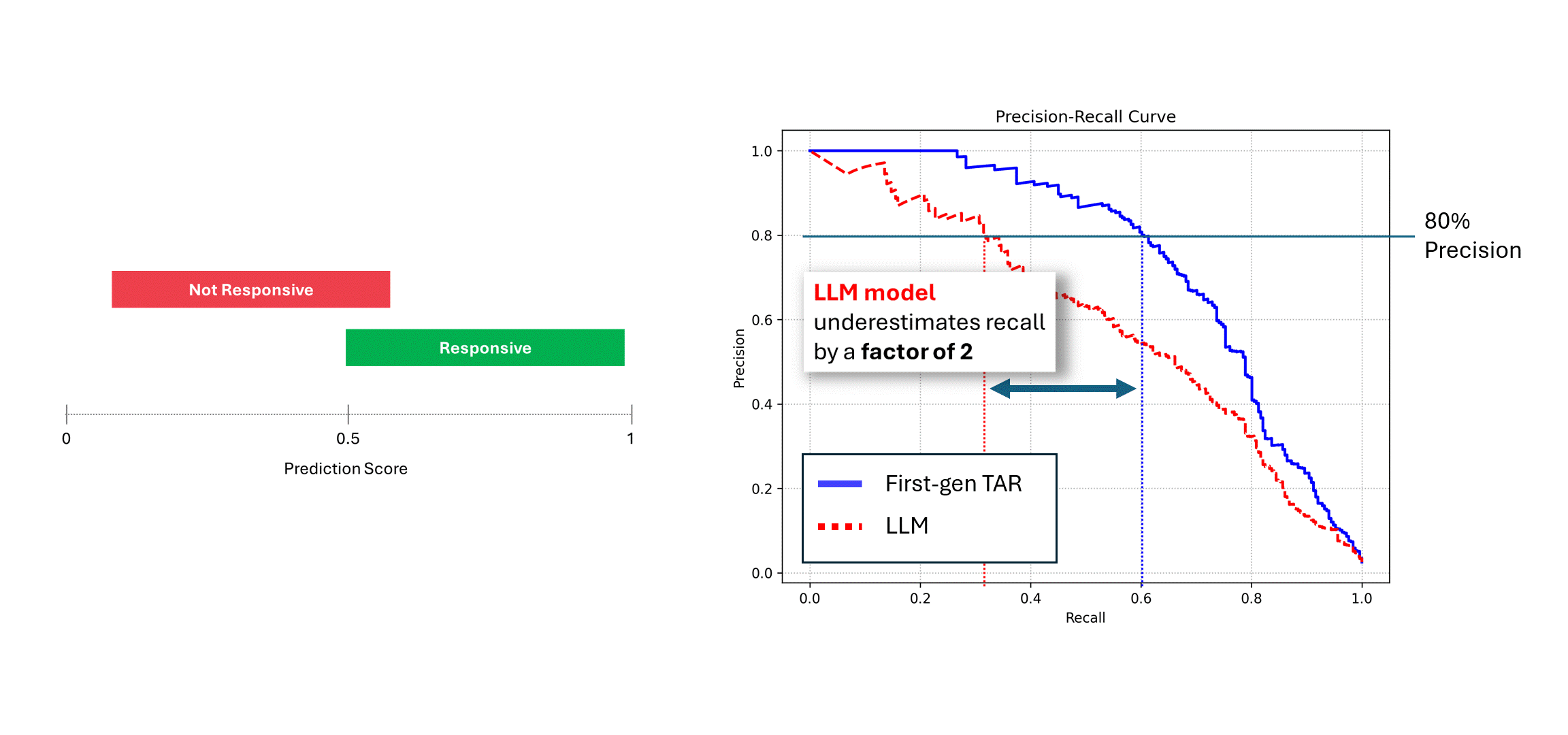
ノイズの多いモデル(つまりLLM)が同じデータで複数回実行され、そのスコアが平均されると、そのPrecisionとRecallは決定論的モデル、つまり青い曲線に近づきます。しかし、1回の予測に頼ると(赤い曲線)、性能は低下し、常にモデルの真の性能を過小評価します。上の例では、性能は実際の半分までと報告されることがあります。
現実的な意味合いは?
実際には、LLMのPrecision-Recall曲線(上の赤い曲線)を見ても、不十分なパフォーマンスしか見えず、その原因もわからない。直感的には、おそらくプロンプトをチューニングしたり、いくつかの例を追加したりして、モデルのパフォーマンスを改善することになるでしょう。
この場合、その努力はすべて無駄になってしまいます。パフォーマンスのギャップは、モデル自体が十分でないからではなく、非決定論的な性質がモデルのパフォーマンスを過小評価しているからです。このパフォーマンスギャップを埋める唯一の方法は、LLMに複数回スコアを求め、その予測値を平均化することです。
単純にコストと時間の理由から、各文書に対してモデルを10倍実行することはないことを考えると、モデルのパフォーマンスが正確に報告されるようにするための解決策はあるのでしょうか?答えはイエスです - 次回のブログポストで見てみましょう。ご期待ください!

Igor Labutov、Epiq AI Labsバイスプレジデント
Igor LabutovはEpiqのバイスプレジデントで、Epiq AI Labsの共同リーダーを務めています。Igorはコンピュータ科学者であり、自然言語などの人間の自然な監視から学習する機械学習アルゴリズムの開発に強い関心を持っています。人工知能および機械学習において10年以上の研究経験があります。Labutovはコーネル大学で博士号を取得し、カーネギーメロン大学の博士研究員として、人間中心のAIと機械学習の交差点で先駆的な研究を行いました。Epiqに入社する前は、LAER AIを共同設立し、自身の研究を応用して法律業界向けの革新的なテクノロジーを開発しました。